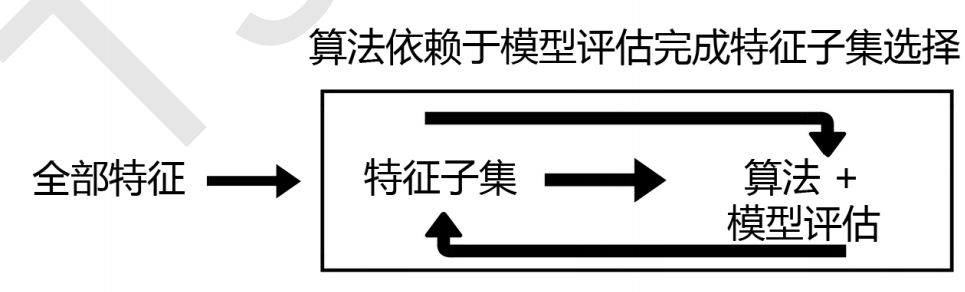
1 Embedded嵌入法







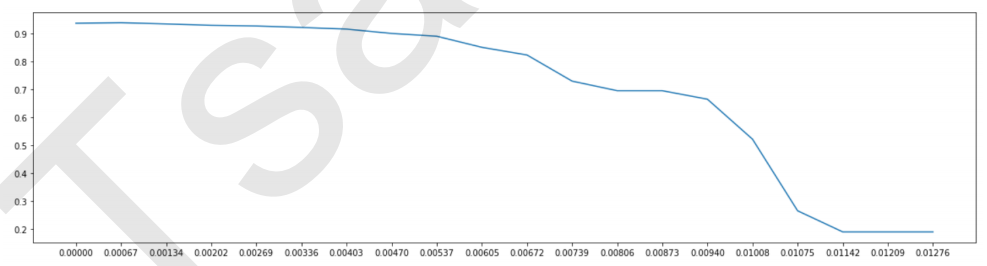
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import RandomForestClassifier as RFC RFC_ = RFC(n_estimators =10,random_state=0) X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y) #在这里我只想取出来有限的特征。0.005这个阈值对于有780个特征的数据来说,是非常高的阈值,因为平均每个特征 只能够分到大约0.001的feature_importances_ X_embedded.shape #模型的维度明显被降低了 #同样的,我们也可以画学习曲线来找最佳阈值 #======【TIME WARNING:10 mins】======# import numpy as np import matplotlib.pyplot as plt RFC_.fit(X,y).feature_importances_ threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20) score = [] for i in threshold: X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y) once = cross_val_score(RFC_,X_embedded,y,cv=5).mean() score.append(once) plt.plot(threshold,score) plt.show()

X_embedded = SelectFromModel(RFC_,threshold=0.00067).fit_transform(X,y)
X_embedded.shape
cross_val_score(RFC_,X_embedded,y,cv=5).mean()

#======【TIME WARNING:10 mins】======# score2 = [] for i in np.linspace(0,0.00134,20): X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y) once = cross_val_score(RFC_,X_embedded,y,cv=5).mean() score2.append(once) plt.figure(figsize=[20,5]) plt.plot(np.linspace(0,0.00134,20),score2) plt.xticks(np.linspace(0,0.00134,20)) plt.show()
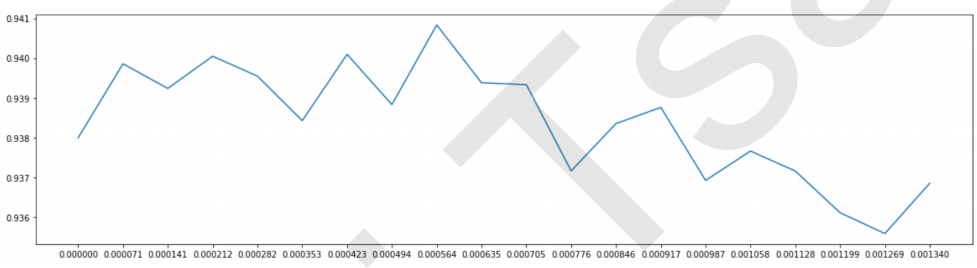

X_embedded = SelectFromModel(RFC_,threshold=0.000564).fit_transform(X,y) X_embedded.shape cross_val_score(RFC_,X_embedded,y,cv=5).mean() #=====【TIME WARNING:2 min】=====# #我们可能已经找到了现有模型下的最佳结果,如果我们调整一下随机森林的参数呢? cross_val_score(RFC(n_estimators=100,random_state=0),X_embedded,y,cv=5).mean()

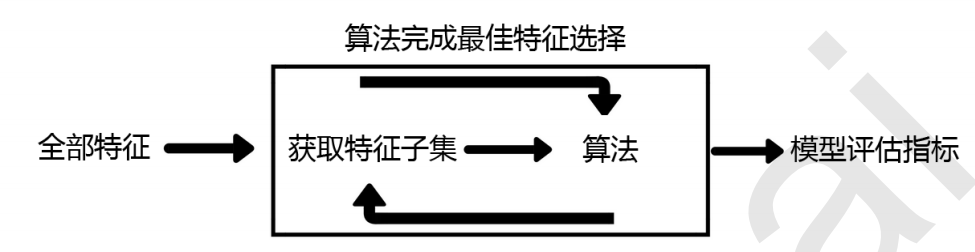
2 Wrapper包装法



from sklearn.feature_selection import RFE RFC_ = RFC(n_estimators =10,random_state=0) selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y) selector.support_.sum() selector.ranking_ X_wrapper = selector.transform(X) cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
我们也可以对包装法画学习曲线:
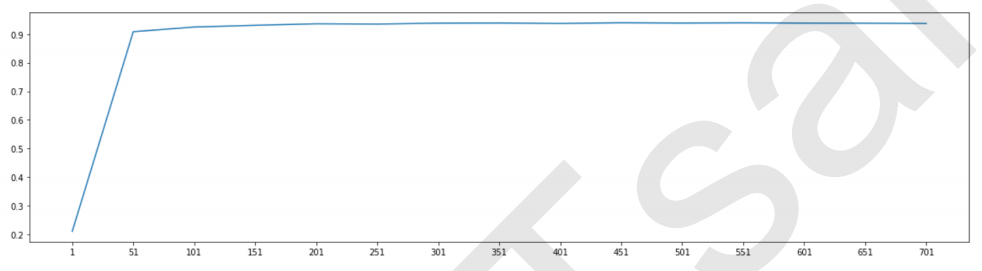
#======【TIME WARNING: 15 mins】======# score = [] for i in range(1,751,50): X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y) once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean() score.append(once) plt.figure(figsize=[20,5]) plt.plot(range(1,751,50),score) plt.xticks(range(1,751,50)) plt.show()

3 特征选择总结

参考;https://blog.csdn.net/kylin_learn/article/details/82658673