来源:https://www.cnblogs.com/cgmcoding/p/14360420.html
其中count encoder,one-hot encoder,label encoder主要针对低基数无序特征,比如性别。可以采用target encoder或者mean encoder的方法来针对高基数无序特征,比如地区,邮编等
一、Label Encoding
LabelEncoder() 将转换成连续的数值型变量。即是对不连续的数字或者文本进行编号,我们知道,梯度提升树模型是无法对此类特征进行处理的。直接将其输入到模型就会报错。而这个时候最为常见的就是使用LabelEncoder对其进行编码。LabelEncoder可以将类型为object的变量转变为数值形式
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
Label encoding在某些情况下很有用,但是场景限制很多。再举一例:比如有[dog,cat,dog,mouse,cat],我们把其转换为[1,2,1,3,2]。这里就产生了一个奇怪的现象:dog和mouse的平均值是cat。所以目前还没有发现标签编码的广泛使用
Pandas的factorize()可以将Series中的标称型数据映射称为一组数字
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
Label Encoding只是将文本转化为数值,并没有解决文本特征的问题:所有的标签都变成了数字,算法模型直接将根据其距离来考虑相似的数字,而不考虑标签的具体含义。使用该方法处理后的数据适合支持类别性质的算法模型,如LightGBM
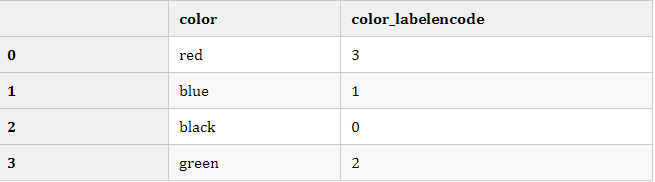
LabelEncoder默认会先将object类型的变量进行排序,然后按照大小顺序进行的编码,此处N为该特征中不同变量的个数。几乎所有的赛题中都会这么做,这样做我们就可以将转化后的特征输入到模型,虽然这并不是模型最喜欢的形式,但是至少也可以吸收10%左右的信息,会总直接丢弃该变量的信息好很多。
模板代码如下:
from sklearn import preprocessing df = pd.DataFrame({'color':['red','blue','black','green']}) le = preprocessing.LabelEncoder() le.fit(df['color'].values) df['color_labelencode'] = le.transform(df['color'].values) df
二、One-Hot Encoding
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为male和female。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,比如有如下三个特征属性:
- 性别:[“male”,”female”]
- 地区:[“Europe”,”US”,”Asia”]
- 浏览器:[“Firefox”,”Chrome”,”Safari”,”Internet Explorer”]
对于某一个样本,如[“male”,”US”,”Internet Explorer”],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是,即使转化为数字表示后,上述数据也不能直接用在我们的分类器中。因为,分类器往往默认数据是连续的,并且是有序的。按照上述的表示,数字并不是有序的,而是随机分配的。这样的特征处理并不能直接放入机器学习算法中。
为了解决上述问题,其中一种可能的解决方法是采用独热编码(One-Hot Encoding)。独热编码,又称为一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
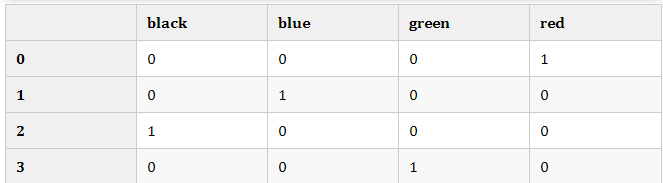
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是四维的,这样,我们可以采用One-Hot编码的方式对上述的样本[“male”,”US”,”Internet Explorer”]编码,male则对应着[1,0],同理US对应着[0,1,0],Internet Explorer对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。
为什么能使用One-Hot Encoding
- 使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
- 将离散型特征使用one-hot编码,可以会让特征之间的距离计算更加合理。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
- 优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。而且One-Hot Encoding+PCA这种组合在实际中也非常有用
One-Hot Encoding的使用场景
- 独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
- 基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念
再插一个
什么情况下(不)需要归一化?
- 需要: 基于参数的模型或基于距离的模型,都是要进行特征的归一化。
- 不需要:基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。

模板代码
from sklearn import preprocessing df = pd.DataFrame({'color':['red','blue','black','green']}) pd.get_dummies(df['color'].values)
三、Frequency编码
Frequency编码是数据竞赛中使用最为广泛的技术,在90%以上的数据建模的问题中都可以带来提升。因为在很多的时候,频率的信息与我们的目标变量往往存在有一定关联,例如:
- 在音乐推荐问题中,对于乐曲进行Frequency编码可以反映该乐曲的热度,而热度高的乐曲往往更受大家的欢迎;
- 在购物推荐问题中,对于商品进行Frequency编码可以反映该商品的热度,而热度高的商品大家也更乐于购买;
- 微软设备被攻击概率问题中,预测设备受攻击的概率,那么设备安装的软件是非常重要的信息,此时安装软件的count编码可以反映该软件的流行度,越流行的产品的受众越多,那么黑客往往会倾向对此类产品进行攻击,这样黑客往往可以获得更多的利益
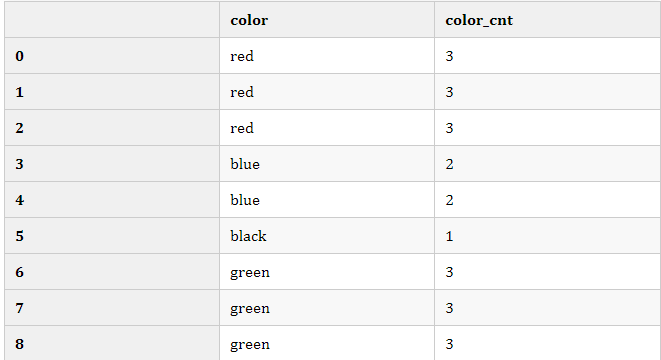
Frequency编码通过计算特征变量中每个值的出现次数来表示该特征的信息,详细的案例如下所示:
在很多实践问题中,Count编码往往可以给模型的效果带来不错的帮助
from sklearn import preprocessing df = pd.DataFrame({'color':['red','red','red','blue','blue','black','green','green','green']}) df['color_cnt'] = df['color'].map(df['color'].value_counts()) df