1 什么是随机变量
⼀个事件的所有可能结果组成这个事件的样本空间,其中的每⼀种结果叫做样本点。如果对于每⼀个样本点,都有⼀个唯⼀的实数与之对应,则就产⽣了⼀个样本点到唯⼀实数之间的函数,我们称该函数为随机变量。随机变量中的每⼀个取值及取值的概率被称为概率分布。
2 随机变量的两种类型
2.1 离散型随机变量
当⼀个随机变量的全部可能取值,只有有限多个或者可列⽆穷多个,则称他是离散型随机变量。
import pandas as pd import seaborn as sns import numpy as np ar=np.random.randn(20,4) df=pd.DataFrame(ar,columns=['a','b','c','d']) df['e']=pd.Series(['one','one','one','one','one','one','two','two','two','two' ,'two','two','two','two', 'three','three','three','three','three','three']) sns.scatterplot(df['a'],df['b'],hue=df['e'])
<matplotlib.axes._subplots.AxesSubplot at 0x1a184de2b0>
import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") # Load the example iris dataset diamonds = sns.load_dataset("diamonds") # Draw a scatter plot while assigning point colors and sizes to different # variables in the dataset f, ax = plt.subplots(figsize=(6.5, 6.5)) sns.despine(f, left=True, bottom=True) clarity_ranking = ["I1", "SI2", "SI1", "VS2", "VS1", "VVS2", "VVS1", "IF"] sns.scatterplot(x="carat", y="price", hue="clarity", size="depth", palette="ch:r=-.2,d=.3_r", hue_order=clarity_ranking, sizes=(1, 8), linewidth=0, data=diamonds, ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x1a1fe877f0>
2.1.1离散型随机变量对应的常⻅分布:
两点分布
⼆项分布
⼏何分布
超⼏何分布
均匀分布
泊松分布
2.1.2 概率质量函数(分布律)
离散型随机变量的概率分布可以使⽤分布律(概率质量函数)来描述。
我们通常⽤⼤写字⺟푃来表示离散型随机变量的分布律,如P(x)表示离散型随机变量x的分布律。分布律将随机变量中的每个取值映射到该取值的概率。x =x 的概率⽤P(x=x)来表示。
如果P是⼀个随机变量的分布律,则要满⾜下⾯⼏个条件:
1、 푃的定义域是 x 的所有可能取值的集合。
2、 对∀x∈x,0≤P(x)≤1。不可能事件概率为0,必然事件概率为1。
3、 Σx∈xP(x)=1,也就是P(x)的所有取值之和为1,我们称这条性质为归⼀化的(normalized)。
2.1.3 联合概率分布
分布律可以作⽤于多个随机变量,这种多个随机变量的概率分布被称为联合概率分布(joint probability distribution),如P(X=x, Y=x)表示X=x,Y=y同时发⽣的概率,有时可以简写为
p(x,y)。
2.2 连续型随机变量
当⼀个变量的所有可能取值为连续的(全部实数、⼀段区间),则称它为连续型随机变量。
import matplotlib.pyplot as plt import seaborn as sns # 数据集 data = sns.load_dataset("fmri") print(data.head()) # 绘画折线图 sns.relplot(x="timepoint", y="signal", kind="line", data=data, ci=None) # 显示 plt.show()
2.2.1 连续型随机变量常⻅的分布:
指数分布
正态分布
2.2.2 概率密度函数
连续型随机变量的概率分布可以使⽤概率密度函数来描述。
若存在⾮负可积函数f(x),使得随机变量X的取值在任⼀区间(a,b]的概率可表示成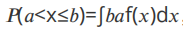 ,则X称为连续型随机变量f(x)为X的概率密度函数。
,则X称为连续型随机变量f(x)为X的概率密度函数。
如果⼀个函数f是概率密度函数,则f需要满⾜以下⼏条性质:
1、f的定义域是 x 的所有可能取值的集合。
2 对∀x∈X,f(x)≥0,注意,这⾥并不要求f(x)≤1,因为f(푥)只是概率密度函数,对f(x)积分才是概率分布律。
3、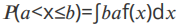 ,含义是푥落到区间(a,b]的概率((a,b),[a, b], (a,b], [a, b)均满⾜这个公式)。
,含义是푥落到区间(a,b]的概率((a,b),[a, b], (a,b], [a, b)均满⾜这个公式)。
4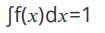
4