1. Flink on YARN两种方式
Flink on YARN 有两种模式:Session模式和Per-Job模式。在Session模式中多个 JobManager 共享 Dispatcher 和 YarnResourceManager。在这种模式下,需要先向 YARN 申请资源,初始化一个常驻服务在 YARN 上,后续提交的Job都将运行在这个Session上:

而Per-Job模式则相反,一个 JobManager 独享 Dispatcher 和 YarnResourceManager。也就是说每提交一个Job都新建一个Session,不同Job之间的资源是隔离的,不会互相影响:

image.png
想要深入了解的话可以参考官方文档:
2 Flink on YARN Session模式实操
首先将在 Flink部署及作业提交(On Flink Cluster) 一文中编译好的Flink目录拷贝到当前部署了Hadoop环境的机器上:
[root@hadoop01 ~]# scp -r 192.168.243.148:/usr/local/src/flink-release-1.11.2/flink-dist/target/flink-1.11.2-bin/flink-1.11.2/ /usr/local/flink
配置环境变量,否则Flink会报找不到Hadoop相关Class的异常:
[root@hadoop01 ~]# vim /etc/profile export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_CLASSPATH=$HADOOP_COMMON_HOME/lib:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/mepreduce/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/tools/*:$HADOOP_HOME/share/hadoop/httpfs/*:$HADOOP_HOME/share/hadoop/kms/*:$HADOOP_HOME/share/hadoop/common/lib/*
然后执行./bin/yarn-session.sh --help命令测试一下能否正常输出帮助信息:
[root@hadoop01 ~]# cd /usr/local/flink/ [root@hadoop01 /usr/local/flink]# ./bin/yarn-session.sh --help ... Usage: Optional -at,--applicationType <arg> Set a custom application type for the application on YARN -D <property=value> use value for given property -d,--detached If present, runs the job in detached mode -h,--help Help for the Yarn session CLI. -id,--applicationId <arg> Attach to running YARN session -j,--jar <arg> Path to Flink jar file -jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB) -m,--jobmanager <arg> Address of the JobManager to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration. -nl,--nodeLabel <arg> Specify YARN node label for the YARN application -nm,--name <arg> Set a custom name for the application on YARN -q,--query Display available YARN resources (memory, cores) -qu,--queue <arg> Specify YARN queue. -s,--slots <arg> Number of slots per TaskManager -t,--ship <arg> Ship files in the specified directory (t for transfer) -tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB) -yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead) -z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode [root@hadoop01 /usr/local/flink]#
- 如果没配环境变量的话,执行这条命令就会报找不到类的错误
确认Flink可以正常找到Hadoop后,使用如下命令在 YARN 上创建一个常驻服务:
[root@hadoop01 /usr/local/flink]# ./bin/yarn-session.sh -jm 1024m -tm 2048m ... JobManager Web Interface: http://hadoop01:37525 # 创建成功的话会输出JobManager的web访问地址
-jm:指定JobManager需要的内存资源-tm:指定TaskManager需要的内存资源
使用浏览器打开 YARN 的web界面,正常情况下会有如下应用:
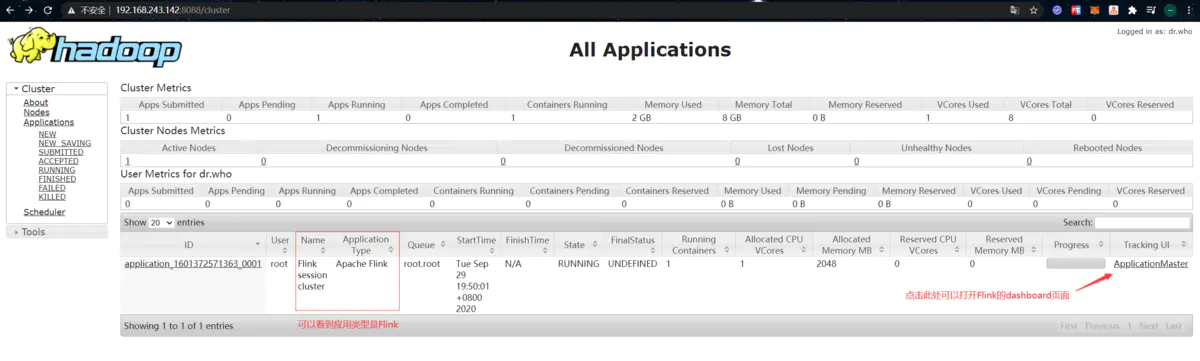
点击应用右边的 “ApplicationMaster” 可以跳转到Flink的dashboard。此时可以看到Flink Dashboard页面上任何数字都是0,应该就能看得出实际这只是启动了一个JobManager:
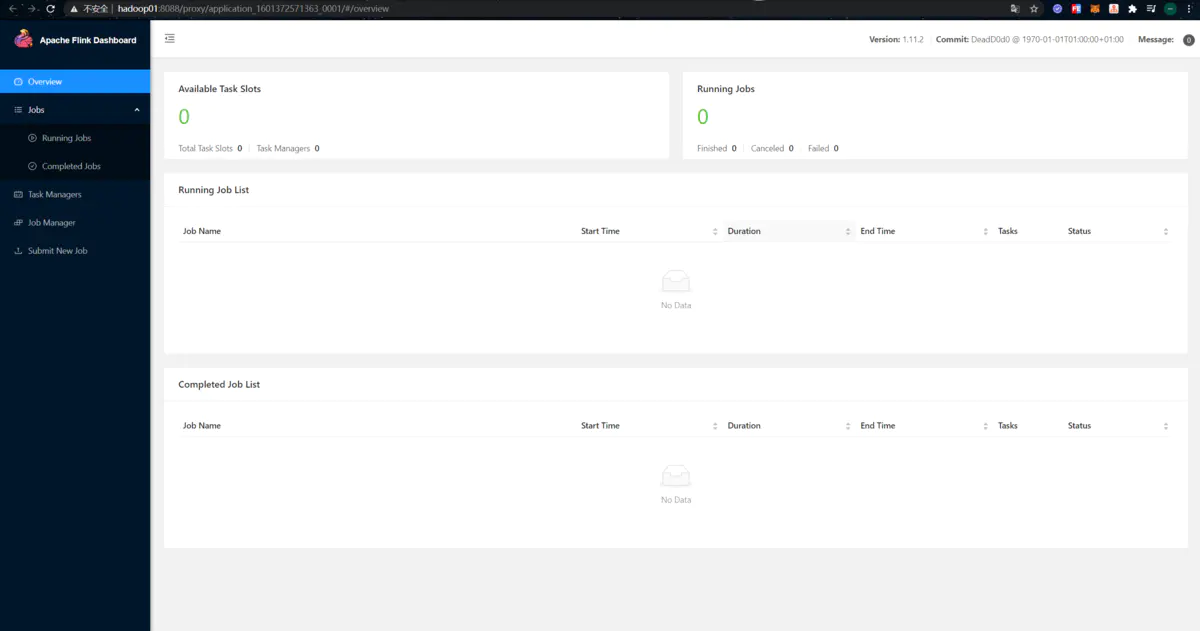
- Tips:要想页面能够正常跳转,还得在浏览器所在主机的
hosts文件中配置一下hadoop01这个主机名到IP的映射关系
接下来我们尝试一下提交作业到 YARN 上运行,首先准备好官方提供的测试文件,并put到HDFS中:
[root@hadoop01 ~]# wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt [root@hadoop01 ~]# hadoop fs -copyFromLocal LICENSE-2.0.txt /
然后执行如下命令,提交一个Word Count作业:
[root@hadoop01 ~]# cd /usr/local/flink/ [root@hadoop01 /usr/local/flink]# ./bin/flink run -m hadoop01:37525 ./examples/batch/WordCount.jar --input hdfs://hadoop01:8020/LICENSE-2.0.txt --output hdfs://hadoop01:8020/wordcount-result.txt
- Tips:这里的
hadoop01:37525,是执行完yarn-session.sh命令输出的JobManager的访问地址
执行完成后,控制台会输出如下内容:
Job has been submitted with JobID 2240e11994cf8579a78e16a1984f08db
Program execution finished
Job with JobID 2240e11994cf8579a78e16a1984f08db has finished.
Job Runtime: 10376 ms
此时到“Completed Jobs”页面中,可以看到运行完成的作业及其信息:
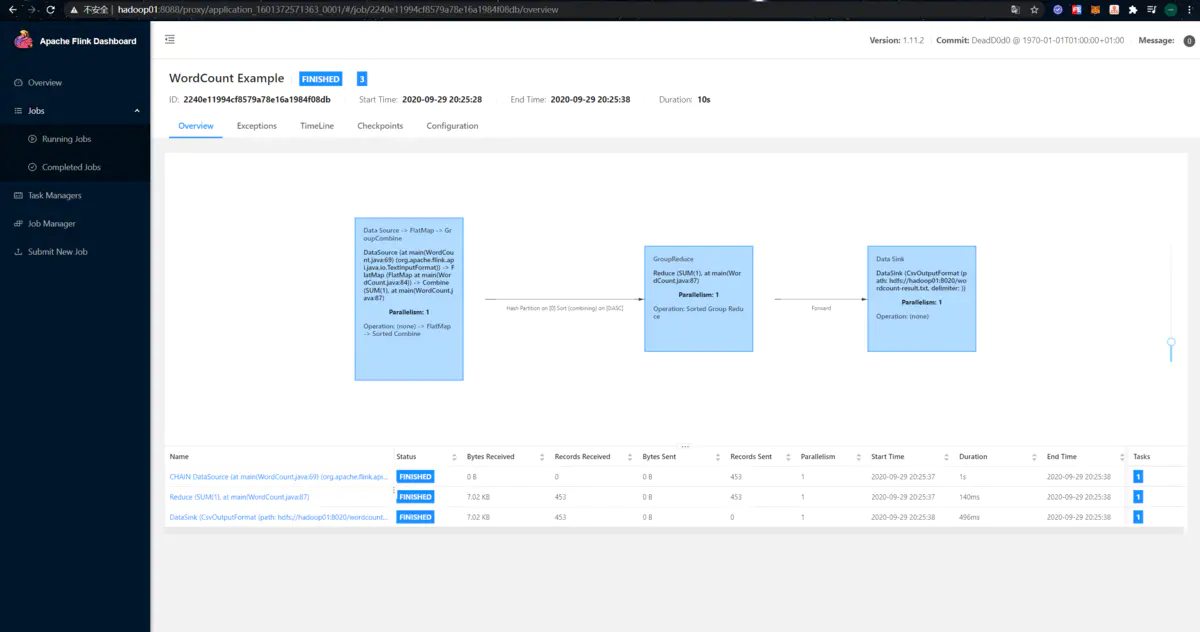
除此之外,我们还可以查看该作业输出到HDFS中的结果文件:
[root@hadoop01 /usr/local/flink]# hadoop fs -ls /wordcount-result.txt -rw-r--r-- 1 root supergroup 4499 2020-09-29 20:25 /wordcount-result.txt [root@hadoop01 /usr/local/flink]# hadoop fs -text /wordcount-result.txt
作者:端碗吹水
链接:https://www.jianshu.com/p/9c9f815f249e
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.jianshu.com/p/9c9f815f249e
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。