https://zhuanlan.zhihu.com/p/64419762
每当拿到原始数据,不如意十有八九,快速准确的清洗数据也是必备技能,数据清洗正好是 PowerQuery 的强项,本文就来介绍两个常用的 M 函数:Text.Remove 和 Text.Select。
看到以 Text 开头的,就知道是文本处理函数,比如原始数据如下,
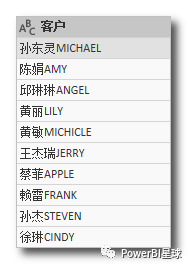
如果只想要中文名,就是把英文字母都去掉,可以用Text.Remove函数,添加自定义列,
姓名=Text.Remove([客户],{"A".."Z"})

Text.Remove 的参数有两个,第一个就是文本,第二个就是要移除的字符,可以是文本或者是文本的列表,{"A".."Z"}就是生成了一个从A到Z的列表,只要是大写字母,就从客户的信息中移除。
如果有小写字母,需要把所有的字母都移除了,把大写的"Z"替换成小写的"z"就行了,
姓名=Text.Remove([客户],{"A".."z"})
如果只想要英文名,要去掉中文名,可以这样写,
英文名=Text.Remove([客户],{"一".."龟"})
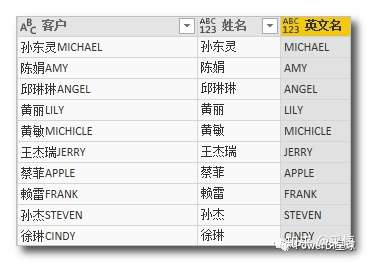
Powerquery 的中文字符以 Unicode 连续储存,"一"的 Unicode最小,正常使用的汉字中,"龟"的 Unicode 最大,因此{"一".."龟"}就包含了所有正常使用的汉字列表,正好利用这个特性,去除了所有的中文字符。
如果有更多种类的文本数据不规则的堆放在一起,比如这样,
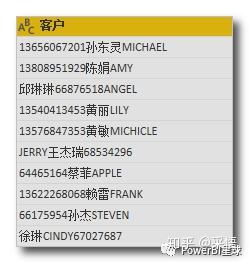
想把联系方式提取出来,第二个参数还可以这样写,
联系方式=Text.Remove([客户],{"A".."z","一".."龟"})
把中文字符和英文字符的列表都放到第二个参数中,全部移除。

不过如果字符种类很多,像这样更加杂乱的,
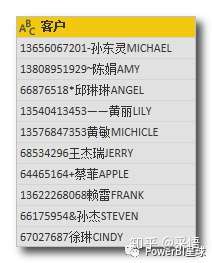
要提取联系方式,用Text.Remove 就有点麻烦,各种奇怪的符号种类太多了,编码也不一定连续。还好有一个 Text.Select 函数专门用来提取的。
Text.Select 函数和 Text.Remove 正好相反,Text.Select 只提取第二个参数中的字符,上图中提取联系方式,直接这样写,
联系方式=Text.Select([客户],{"0".."9"})
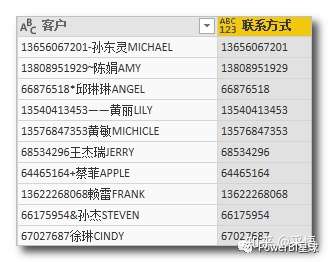
直接就可以得到联系方式信息。
提取各种字符的列表如下,

这两个函数的都很简单,需要提取或者移除字符的情况直接套用就可以了。