一、HashMap 集合简介
-
HashMap 基于哈希表的 Map 接口实现,是以 key-value 存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的 key、value 都可以为 null,此外,HashMap 中的映射不是有序的。
-
jdk1.8 之前 HashMap 由 数组 + 链表 组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的 hashCode 方法计算的哈希值经哈希函数算出来的地址被别的元素占用)而存在的(“拉链法”解决冲突)。jdk1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8 )并且当前数组的长度大于 64 时,此时此索引位置上的所有数据改为使用红黑树存储。
-
补充:将链表转换成红黑树前会判断,即便阈值大于 8,但是数组长度小于 64,此时并不会将链表变为红黑树,而是选择逬行数组扩容。
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要逬行左旋,右旋,变色这些操作来保持平衡。同时数组长度小于64时,搜索时间相对要快些。所以结上所述为了提高性能和减少搜索时间,底层阈值大于8并且数组长度大于64时,链表才转换为红黑树,具体可以参考 treeifyBin() 方法。
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于 8 并且数组长度大于 64 时,链表转换为红黑树时,效率也变的更高效。
-
小结:
HashMap 特点:
- 存储无序的。
- 键和值位置都可以是 null,但是键位置只能存在一个 null。
- 键位置是唯一的,是底层的数据结构控制的。
- jdk1.8 前数据结构是链表+数组,jdk1.8 之后是链表+数组+红黑树。
- 阈值(边界值)> 8 并且数组长度大于 64,才将链表转换为红黑树,变为红黑树的目的是为了高效的查询。
二、HashMap 集合底层的数据结构
2.1 存储数据的过程
示例代码:
HashMap<String, Integer> map = new HashMap<>();
map.put("柳岩", 18);
map.put("杨幂", 28);
map.put("刘德华", 40);
map.put("柳岩", 20);
输出结果:
{杨幂=28, 柳岩=20, 刘德华=40}
分析:
-
当创建 HashMap 集合对象的时候,HashMap 的构造方法并没有创建数组,而是在第一次调用 put 方法时创建一个长度是16 的数组 Node[] table (jdk1.8 之前是 Entry[] table)用来存储键值对数据。
-
假设向哈希表中存储 <柳岩,18> 数据,根据柳岩调用 String 类中重写之后的 hashCode() 方法计算出值,然后结合数组长度采用某种算法计算出向 Node 数组中存储数据的空间的索引值。如果计算出的索引空间没有数据,则直接将<柳岩,18>存储到数组中。(举例:计算出的索引是 3 )
-
向哈希表中存储数据 <刘德华,40>,假设算出的 hashCode() 方法结合数祖长度计算出的索引值也是3,那么此时数组空间不是 null,此时底层会比较柳岩和刘德华的 hash 值是否一致,如果不一致,则在空间上划出一个结点来存储键值对数据对 <刘德华,40>,这种方式称为拉链法。
-
假设向哈希表中存储数据 <柳岩,20>,那么首先根据柳岩调用 hashCode() 方法结合数组长度计算出索引肯定是 3,此时比较后存储的数据柳岩和已经存在的数据的 hash 值是否相等,如果 hash 值相等,此时发生哈希碰撞。那么底层会调用柳岩所属类 String 中的 equals() 方法比较两个内容是否相等:
相等:将后添加的数据的 value 覆盖之前的 value。
不相等:继续向下和其他的数据的 key 进行比较,如果都不相等,则划出一个结点存储数据,如果结点长度即链表长度大于阈值 8 并且数组长度大于 64 则将链表变为红黑树。

-
在不断的添加数据的过程中,会涉及到扩容问题,当超出阈值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的 2 倍,并将原有的数据复制过来。
-
综上描述,当位于一个表中的元素较多,即 hash 值相等但是内容不相等的元素较多时,通过 key 值依次查找的效率较低。而 jdk1.8 中,哈希表存储采用数组+链表+红黑树实现,当链表长度(阈值)超过8且当前数组的长度大于64时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。如下图所示:

-
jdk1.8 中引入红黑树的进一步原因:
jdk1.8 以前 HashMap 的实现是数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有n个元素,遍历的时间复杂度就是O(n),完全失去了它的优势。
针对这种情况,jdk1.8 中引入了红黑树(查找时间复杂度为 O(logn))来优化这个问题。当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。
-
总结:

说明:
- size 表示 HashMap 中键值对的实时数量,注意这个不等于数组的长度。
- threshold(临界值)= capacity(容量)* loadFactor(负载因子)。这个值是当前已占用数组长度的最大值。size 超过这个值就重新 resize(扩容),扩容后的 HashMap 容量是之前容量的两倍。
2.2 面试题
- HashMap 中 hash 函数是怎么实现的?还有哪些hash函数的实现方式?
答:对于 key 的 hashCode 做 hash 操作,无符号右移 16 位然后做异或运算。还有平方取中法,伪随机数法和取余数法。这三种效率都比较低。而无符号右移 16 位异或运算效率是最高的。 - 当两个对象的 hashCode 相等时会怎么样?
答:会产生哈希碰撞。若 key 值内容相同则替换旧的 value,不然连接到链表后面,链表长度超过阈值 8 就转换为红黑树存储。 - 什么是哈希碰撞,如何解决哈希碰撞?
答:只要两个元素的 key 计算的哈希码值相同就会发生哈希碰撞。jdk8 之前使用链表解决哈希碰撞。jdk8之后使用链表 + 红黑树解决哈希碰撞。 - 如果两个键的 hashCode 相同,如何存储键值对?
答:通过 equals 比较内容是否相同。相同:则新的 value 覆盖之前的 value。不相同:则将新的键值对添加到哈希表中。
三、HashMap继承关系
HashMap继承关系如下图所示:

说明:
- Cloneable 空接口,表示可以克隆。创建并返回 HashMap 对象的一个副本。
- Serializable 序列化接口。属于标记性接口。HashMap 对象可以被序列化和反序列化。
- AbstractMap 父类提供了 Map 实现接口。以最大限度地减少实现此接口所需的工作。
补充:
通过上述继承关系我们发现一个很奇怪的现象,就是 HashMap 已经继承了AbstractMap 而 AbstractMap 类实现了Map 接口,那为什么 HashMap 还要在实现 Map 接口呢?同样在 ArrayList 中 LinkedLis 中都是这种结构。
据 Java 集合框架的创始人 Josh Bloch 描述,这样的写法是一个失误。在 Java 集合框架中,类似这样的写法很多,最幵始写 Java 集合框架的时候,他认为这样写,在某些地方可能是有价值的,直到他意识到错了。显然的,jdk 的维护者,后来不认为这个小小的失误值得去修改,所以就这样保留下来了。
四、HashMap 集合类的成员
4.1 成员变量
4.1.1 serialVersionUID
序列化版本号
private static final long serialVersionUID = 362498820763181265L;
4.1.2 DEFAULT_INITIAL_CAPACITY
集合的初始化容量(必须是 2 的 n 次幂)
// 默认的初始容量是16 1 << 4 相当于 1*2的4次方
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
问题:为什么必须是 2 的 n 次幂?如果输入值不是 2 的幂比如 10 会怎么样?
HashMap 构造方法还可以指定集合的初始化容量大小:
// 构造一个带指定初始容量和默认负载因子(0.75)的空 HashMap。
HashMap(int initialCapacity)
根据上述讲解我们已经知道,当向 HashMap 中添加一个元素的时候,需要根据 key 的 hash 值,去确定其在数组中的具体位置。HashMap 为了存取高效,减少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现的关键就在把数据存到哪个链表中的算法。
这个算法实际就是取模,hash % length,计算机中直接求余效率不如位移运算。所以源码中做了优化,使用 hash & (length - 1),而实际上 hash % length 等于 hash & ( length - 1) 的前提是 length 是 2 的 n 次幂。
例如长度为 8 的时候,3 & (8 - 1) = 3,2 & (8 - 1) = 2,不同位置上,不碰撞。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
说明:
当在实例化 HashMap 实例时,如果给定了 initialCapacity,由于 HashMap 的 capacity 必须都是 2 的幂,因此这个方法用于找到大于等于 initialCapacity 的最小的 2 的幂。
分析:
- int n = cap - 1;
防止 cap 已经是 2 的幂。如果 cap 已经是 2 的幂,又没有这个减 1 操作,则执行完后面的几条无符号操作之后,返回的 capacity 将是这个 cap 的 2 倍。 - 如果 n 这时为 0 了(经过了cap - 1后),则经过后面的几次无符号右移依然是 0,最后返回的 capacity 是1(最后有个 n + 1 的操作)。
- 注意:容量最大也就是 32bit 的正数,因此最后 n |= n >>> 16; 最多也就 32 个 1(但是这已经是负数了,在执行 tableSizeFor 之前,对 initialCapacity 做了判断,如果大于MAXIMUM_CAPACITY(2 ^ 30),则取 MAXIMUM_CAPACITY。如果等于MAXIMUM_CAPACITY,会执行位移操作。所以这里面的位移操作之后,最大 30 个 1,不会大于等于 MAXIMUM_CAPACITY。30 个 1,加 1 后得 2 ^ 30)。
完整例子:

注意:得到的这个 capacity 却被赋值给了 threshold。
this.threshold = tableSizeFor(initialCapacity);
4.1.3 DEFAULT_LOAD_FACTOR
默认的负载因子(默认值 0.75)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4.1.4 MAXIMUM_CAPACITY
集合最大容量
static final int MAXIMUM_CAPACITY = 1 << 30; // 2的30次幂
4.1.5 TREEIFY_THRESHOLD
当链表的值超过8则会转为红黑树(jdk1.8新增)
// 当桶(bucket)上的结点数大于这个值时会转为红黑树
static final int TREEIFY_THRESHOLD = 8;
问题:为什么 Map 桶中结点个数超过 8 才转为红黑树?
8这个阈值定义在HashMap中,针对这个成员变量,在源码的注释中只说明了 8 是 bin(bin就是 bucket 桶)从链表转成树的阈值,但是并没有说明为什么是 8。
在 HashMap 中有一段注释说明:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins
contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too
small (due to removal or resizing) they are converted back to plain bins. In usages with
well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes,
the frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution)
with a parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance,
the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are:
翻译:因为树结点的大小大约是普通结点的两倍,所以我们只在箱子包含足够的结点时才使用树结点(参见 TREEIFY_THRESHOLD)。
当它们变得太小(由于删除或调整大小)时,就会被转换回普通的桶。在使用分布良好的用户 hashCode 时,很少使用树箱。
理想情况下,在随机哈希码下,箱子中结点的频率服从泊松分布
(http://en.wikipedia.org/wiki/Poisson_distribution) ,默认调整阈值为0.75,平均参数约为0.5,尽管由
于调整粒度的差异很大。忽略方差,列表大小 k 的预朗出现次数是(exp(-0.5) * pow(0.5, k) / factorial(k))。
第一个值是:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
TreeNodes 占用空间是普通 Nodes 的两倍,所以只有当 bin 包含足够多的结点时才会转成 TreeNodes,而是否足够多就是由 TREEIFY_THRESH〇LD 的值决定的。当 bin 中结点数变少时,又会转成普通的 bin。并且我们查看源码的时候发现,链表长度达到 8 就转成红黑树,当长度降到 6 就转成普通 bin。
这样就解释了为什么不是一开始就将其转换为 TreeNodes,而是需要一定结点数才转为 TreeNodes,说白了就是权衡空间和时间。
这段内容还说到:当 hashCode 离散性很好的时候,树型 bin 用到的概率非常小,因为数据均匀分布在每个 bin 中,几乎不会有 bin 中链表长度会达到阈值。但是在随机 hashCode 下,离散性可能会变差,然而 jdk 又不能阻止用户实现这种不好的 hash 算法,因此就可能导致不均匀的数据分布。不理想情况下随机 hashCode 算法下所有 bin 中结点的分布频率会遵循泊松分布,我们可以看到,一个 bin 中链表长度达到 8 个元素的槪率为 0.00000006,几乎是不可能事件。所以,之所以选择 8,不是随便決定的,而是裉据概率统计决定的。甶此可见,发展将近30年的 Java 每一项改动和优化都是非常严谨和科学的。
也就是说:选择 8 因为符合泊松分布,超过 8 的时候,概率已经非常小了,所以我们选择 8 这个数宇。
补充:
-
Poisson 分布(泊松分布),是一种统计与概率学里常见到的离散[概率分布]。泊松分布的概率函数为:

泊松分布的参数 A 是单位时间(或单位面积)内随机事件的平均发生次数。泊松分布适合于描述单位时间内随机事件发生的次数。 -
以下是我在研究这个问题时,在一些资料上面翻看的解释,供大家参考:
红黑树的平均查找长度是 log(n),如果长度为 8,平均查找长度为 log(8) = 3,链表的平均查找长度为 n/2,当长度为 8 时,平均查找长虔为 8/2 = 4,这才有转换成树的必要;链表长度如果是小于等于 6, 6/2 = 3,而 log(6) = 2.6,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
4.1.6 UNTREEIFY_THRESHOLD
当链表的值小于 6 则会从红黑树转回链表
// 当桶(bucket)上的结点数小于这个值,树转为链表
static final int UNTREEIFY_THRESHOLD = 6;
4.1.7 MIN_TREEIFY_CAPACITY
当 Map 里面的数量超过这个值时,表中的桶才能进行树形化,否则桶内元素太多时会扩容,而不是树形化为了避免进行扩容、树形化选择的冲突,这个值不能小于4*TREEIFY_THRESHOLD(8)
// 桶中结构转化为红黑树对应的数组长度最小的值
static final int MIN_TREEIFY_CAPACITY = 64;
4.1.8 table
table 用来初始化(必须是二的n次幂)(重点)
// 存储元素的数组
transient Node<K,V>[] table;
在 jdk1.8 中我们了解到 HashMap 是由数组加链表加红黑树来组成的结构,其中 table 就是 HashMap 中的数组,jdk8 之前数组类型是 Entry<K,V> 类型。从 jdk1.8 之后是 Node<K,V> 类型。只是换了个名字,都实现了一样的接口:Map.Entry<K,V>。负责存储键值对数据的。
4.1.9 entrySet
用来存放缓存
// 存放具体元素的集合
transient Set<Map.Entry<K,V>> entrySet;
4.1.10 size
HashMap 中存放元素的个数(重点)
// 存放元素的个数,注意这个不等于数组的长度
transient int size;
size 为 HashMap 中 K-V 的实时数量,不是数组 table 的长度。
4.1.11 modCount
用来记录 HashMap 的修改次数
// 每次扩容和更改 map 结构的计数器
transient int modCount;
4.1.12 threshold
用来调整大小下一个容量的值计算方式为(容量*负载因子)
// 临界值 当实际大小(容量*负载因子)超过临界值时,会进行扩容
int threshold;
4.1.13 loadFactor
哈希表的负载因子(重点)
// 负载因子
final float loadFactor;
说明:
- loadFactor 是用来衡量 HashMap 满的程度,表示HashMap的疏密程度,影响 hash 操作到同一个数组位置的概率,计算 HashMap 的实时负载因子的方法为:size/capacity,而不是占用桶的数量去除以 capacity。capacity 是桶的数量,也就是 table 的长度 length。
- loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
- 当 HashMap 里面容纳的元素已经达到 HashMap 数组长度的 75% 时,表示 HashMap 太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。所以开发中尽量减少扩容的次数,可以通过创建 HashMap 集合对象时指定初始容量来尽量避免。
- 在 HashMap 的构造器中可以定制 loadFactor。
// 构造方法,构造一个带指定初始容量和负载因子的空HashMap
HashMap(int initialCapacity, float loadFactor);
-
为什么负载因子设置为0.75,初始化临界值是12?
loadFactor 越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。

如果希望链表尽可能少些,要提前扩容。有的数组空间有可能一直没有存储数据,负载因子尽可能小一些。
举例:
例如:负载因子是0.4。 那么16*0.4--->6 如果数组中满6个空间就扩容会造成数组利用率太低了。
负载因子是0.9。 那么16*0.9--->14 那么这样就会导致链表有点多了,导致查找元素效率低。
所以既兼顾数组利用率又考虑链表不要太多,经过大量测试 0.75 是最佳方案。
-
threshold 计算公式:capacity(数组长度默认16) * loadFactor(负载因子默认0.75)。
这个值是当前已占用数组长度的最大值。当 Size >= threshold 的时候,那么就要考虑对数组的 resize(扩容),也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。 扩容后的 HashMap 容量是之前容量的两倍。
4.2 构造方法
HashMap 中重要的构造方法,它们分别如下:
4.2.1 HashMap()
构造一个空的HashMap,默认初始容量(16)和默认负载因子(0.75)。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 将默认的负载因子0.75赋值给loadFactor,并没有创建数组
}
4.2.2 HashMap(int initialCapacity)
构造一个具有指定的初始容量和默认负载因子(0.75)HashMap 。
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
4.2.3 HashMap(int initialCapacity, float loadFactor)
构造一个具有指定的初始容量和负载因子的 HashMap。
/*
指定“容量大小”和“负载因子”的构造函数
initialCapacity:指定的容量
loadFactor:指定的负载因子
*/
public HashMap(int initialCapacity, float loadFactor) {
// 判断初始化容量initialCapacity是否小于0
if (initialCapacity < 0)
// 如果小于0,则抛出非法的参数异常IllegalArgumentException
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 判断初始化容量initialCapacity是否大于集合的最大容量MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
// 如果超过MAXIMUM_CAPACITY,会将MAXIMUM_CAPACITY赋值给initialCapacity
initialCapacity = MAXIMUM_CAPACITY;
// 判断负载因子loadFactor是否小于等于0或者是否是一个非数值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
// 如果满足上述其中之一,则抛出非法的参数异常IllegalArgumentException
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 将指定的负载因子赋值给HashMap成员变量的负载因子loadFactor
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
// 最后调用了tableSizeFor,来看一下方法实现:
/*
返回比指定初始化容量大的最小的2的n次幂
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
说明:
对于 javathis.threshold = tableSizeFor(initialCapacity); 疑问解答:
tableSizeFor(initialCapacity)判断指定的初始化容量是否是2的n次幂,如果不是那么会变为比指定初始化容量大的最小的2的n次幂。
但是注意,在tableSizeFor方法体内部将计算后的数据返回给调用这里了,并且直接赋值给threshold边界值了。有些人会觉得这里是一个bug,应该这样书写:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;
这样才符合threshold的意思(当HashMap的size到达threshold这个阈值时会扩容)。
但是请注意,在jdk8以后的构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算。
4.2.4 HashMap(Map<? extends K, ? extends V> m)
包含另一个 “Map” 的构造函数
// 构造一个映射关系与指定 Map 相同的新 HashMap。
public HashMap(Map<? extends K, ? extends V> m) {
// 负载因子loadFactor变为默认的负载因子0.75
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
最后调用了 putMapEntries(),来看一下方法实现:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
//获取参数集合的长度
int s = m.size();
if (s > 0) {
//判断参数集合的长度是否大于0,说明大于0
if (table == null) { // 判断table是否已经初始化
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
注意:
float ft = ((float)s / loadFactor) + 1.0F; 这一行代码中为什么要加 1.0F ?
s/loadFactor 的结果是小数,加 1.0F 与 (int)ft 相当于是对小数做一个向上取整以尽可能的保证更大容量,更大的容量能够减少 resize 的调用次数。所以 + 1.0F 是为了获取更大的容量。
例如:原来集合的元素个数是 6 个,那么 6/0.75 是8,是 2 的n次幂,那么新的数组大小就是 8 了。然后原来数组的数据就会存储到长度是 8 的新的数组中了,这样会导致在存储元素的时候,容量不够,还得继续扩容,那么性能降低了,而如果 +1 呢,数组长度直接变为16了,这样可以减少数组的扩容。
4.3 成员方法
4.3.1 增加方法 put()
put方法是比较复杂的,实现步骤大致如下:
-
先通过 hash 值计算出 key 映射到哪个桶;
-
如果桶上没有碰撞冲突,则直接插入;
-
如果出现碰撞冲突了,则需要处理冲突:
a 如果该桶使用红黑树处理冲突,则调用红黑树的方法插入数据;
b 否则采用传统的链式方法插入。如果链的长度达到临界值,则把链转变为红黑树;
-
如果桶中存在重复的键,则为该键替换新值 value;
-
如果 size 大于阈值 threshold,则进行扩容;
具体的方法如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
说明:
- HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。 所以我们重点看 putVal 方法。
- 我们可以看到在 putVal 方法中 key 在这里执行了一下 hash 方法,来看一下 hash 方法是如何实现的。
static final int hash(Object key) {
int h;
/*
1)如果key等于null:返回的是0.
2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的
二进制进行按位异或得到最后的hash值
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从上面可以得知 HashMap 是支持 key 为空的,而 HashTable 是直接用 Key 来获取hashCode 所以 key 为空会抛异常。
解读上述 hash 方法:
我们先研究下 key 的哈希值是如何计算出来的。key 的哈希值是通过上述方法计算出来的。
这个哈希方法首先计算出 key 的 hashCode 赋值给 h,然后与 h 无符号右移 16 位后的二进制进行按位异或得到最后的 hash 值。计算过程如下所示:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
在 putVal 函数中使用到了上述 hash 函数计算的哈希值:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
...
if ((p = tab[i = (n - 1) & hash]) == null) // 这里的n表示数组长度16
...
}
计算过程如下所示:
说明:
- key.hashCode();返回散列值也就是 hashcode,假设随便生成的一个值。
- n 表示数组初始化的长度是 16。
- &(按位与运算):运算规则:相同的二进制数位上,都是 1 的时候,结果为 1,否则为0。
- ^(按位异或运算):运算规则:相同的二进制数位上,数字相同,结果为 0,不同为 1。

简单来说就是:
高 16bit 不变,低 16bit 和高 16bit 做了一个异或(得到的 hashCode 转化为 32 位二进制,前 16 位和后 16 位低 16bit 和高 16bit 做了一个异或)。
问题:为什么要这样操作呢?
如果当 n 即数组长度很小,假设是 16 的话,那么 n - 1 即为 1111 ,这样的值和 hashCode 直接做按位与操作,实际上只使用了哈希值的后 4 位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成哈希冲突了,所以这里把高低位都利用起来,从而解决了这个问题。
现在看 putVal 方法,看看它到底做了什么。
主要参数:
- hash:key 的 hash 值
- key:原始 key
- value:要存放的值
- onlyIfAbsent:如果 true 代表不更改现有的值
- evict:如果为false表示 table 为创建状态
putVal 方法源代码如下所示:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1)transient Node<K,V>[] table; 表示存储Map集合中元素的数组。
2)(tab = table) == null 表示将空的table赋值给tab,然后判断tab是否等于null,第一次肯定是null。
3)(n = tab.length) == 0 表示将数组的长度0赋值给n,然后判断n是否等于0,n等于0,由于if判断使用双或,满足一个即可,则执行代码 n = (tab = resize()).length; 进行数组初始化,并将初始化好的数组长度赋值给n。
4)执行完n = (tab = resize()).length,数组tab每个空间都是null。
*/
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*
1)i = (n - 1) & hash 表示计算数组的索引赋值给i,即确定元素存放在哪个桶中。
2)p = tab[i = (n - 1) & hash]表示获取计算出的位置的数据赋值给结点p。
3) (p = tab[i = (n - 1) & hash]) == null 判断结点位置是否等于null,如果为null,则执行代码:tab[i] = newNode(hash, key, value, null);根据键值对创建新的结点放入该位置的桶中。
小结:如果当前桶没有哈希碰撞冲突,则直接把键值对插入空间位置。
*/
if ((p = tab[i = (n - 1) & hash]) == null)
// 创建一个新的结点存入到桶中
tab[i] = newNode(hash, key, value, null);
else {
// 执行else说明tab[i]不等于null,表示这个位置已经有值了
Node<K,V> e; K k;
/*
比较桶中第一个元素(数组中的结点)的hash值和key是否相等
1)p.hash == hash :p.hash表示原来存在数据的hash值 hash表示后添加数据的hash值 比较两个hash值是否相等。
说明:p表示tab[i],即 newNode(hash, key, value, null)方法返回的Node对象。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
而在Node类中具有成员变量hash用来记录着之前数据的hash值的。
2)(k = p.key) == key :p.key获取原来数据的key赋值给k key 表示后添加数据的key比较两个key的地址值是否相等。
3)key != null && key.equals(k):能够执行到这里说明两个key的地址值不相等,那么先判断后添加的key是否等于null,如果不等于null再调用equals方法判断两个key的内容是否相等。
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
/*
说明:两个元素哈希值相等,并且key的值也相等,将旧的元素整体对象赋值给e,用e来记录
*/
e = p;
// hash值不相等或者key不相等;判断p是否为红黑树结点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 说明是链表结点
else {
/*
1)如果是链表的话需要遍历到最后结点然后插入
2)采用循环遍历的方式,判断链表中是否有重复的key
*/
for (int binCount = 0; ; ++binCount) {
/*
1)e = p.next 获取p的下一个元素赋值给e。
2)(e = p.next) == null 判断p.next是否等于null,等于null,说明p没有下一个元素,那么此时到达了链表的尾部,还没有找到重复的key,则说明HashMap没有包含该键,将该键值对插入链表中。
*/
if ((e = p.next) == null) {
/*
1)创建一个新的结点插入到尾部
p.next = newNode(hash, key, value, null);
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
注意第四个参数next是null,因为当前元素插入到链表末尾了,那么下一个结点肯定是null。
2)这种添加方式也满足链表数据结构的特点,每次向后添加新的元素。
*/
p.next = newNode(hash, key, value, null);
/*
1)结点添加完成之后判断此时结点个数是否大于TREEIFY_THRESHOLD临界值8,如果大于则将链表转换为红黑树。
2)int binCount = 0 :表示for循环的初始化值。从0开始计数。记录着遍历结点的个数。值是0表示第一个结点,1表示第二个结点。。。。7表示第八个结点,加上数组中的的一个元素,元素个数是9。
TREEIFY_THRESHOLD - 1 --》8 - 1 ---》7
如果binCount的值是7(加上数组中的的一个元素,元素个数是9)
TREEIFY_THRESHOLD - 1也是7,此时转换红黑树。
*/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 转换为红黑树
treeifyBin(tab, hash);
// 跳出循环
break;
}
/*
执行到这里说明e = p.next 不是null,不是最后一个元素。继续判断链表中结点的key值与插入的元素的key值是否相等。
*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
/*
要添加的元素和链表中的存在的元素的key相等了,则跳出for循环。不用再继续比较了
直接执行下面的if语句去替换去 if (e != null)
*/
break;
/*
说明新添加的元素和当前结点不相等,继续查找下一个结点。
用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
*/
p = e;
}
}
/*
表示在桶中找到key值、hash值与插入元素相等的结点
也就是说通过上面的操作找到了重复的键,所以这里就是把该键的值变为新的值,并返回旧值
这里完成了put方法的修改功能
*/
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
// 用新值替换旧值
// e.value 表示旧值 value表示新值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 修改记录次数
++modCount;
// 判断实际大小是否大于threshold阈值,如果超过则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
4.3.2 将链表转换为红黑树 treeifyBin()
结点添加完成之后判断此时结点个数是否大于 TREEIFY_THRESHOLD 临界值 8,如果大于则将链表转换为红黑树,转换红黑树的方法 treeifyBin,整体代码如下:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//转换为红黑树 tab表示数组名 hash表示哈希值
treeifyBin(tab, hash);
treeifyBin 方法如下所示:
/*
替换指定哈希表的索引处桶中的所有链接结点,除非表太小,否则将修改大小。
Node<K,V>[] tab = tab 数组名
int hash = hash表示哈希值
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
/*
如果当前数组为空或者数组的长度小于进行树形化的阈值(MIN_TREEIFY_CAPACITY = 64),就去扩容。而不是将结点变为红黑树。
目的:如果数组很小,那么转换红黑树,然后遍历效率要低一些。这时进行扩容,那么重新计算哈希值,链表长度有可能就变短了,数据会放到数组中,这样相对来说效率高一些。
*/
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//扩容方法
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
/*
1)执行到这里说明哈希表中的数组长度大于阈值64,开始进行树形化
2)e = tab[index = (n - 1) & hash]表示将数组中的元素取出赋值给e,e是哈希表中指定位置桶里的链表结点,从第一个开始
*/
// hd:红黑树的头结点 tl:红黑树的尾结点
TreeNode<K,V> hd = null, tl = null;
do {
// 新创建一个树的结点,内容和当前链表结点e一致
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p; // 将新创键的p结点赋值给红黑树的头结点
else {
p.prev = tl; // 将上一个结点p赋值给现在的p的前一个结点
tl.next = p; // 将现在结点p作为树的尾结点的下一个结点
}
tl = p;
/*
e = e.next 将当前结点的下一个结点赋值给e,如果下一个结点不等于null
则回到上面继续取出链表中结点转换为红黑树
*/
} while ((e = e.next) != null);
/*
让桶中的第一个元素即数组中的元素指向新建的红黑树的结点,以后这个桶里的元素就是红黑树
而不是链表数据结构了
*/
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
小结:上述操作一共做了如下几件事:
- 根据哈希表中元素个数确定是扩容还是树形化。
- 如果是树形化遍历桶中的元素,创建相同个数的树形结点,复制内容,建立起联系。
- 然后让桶中的第一个元素指向新创建的树根结点,替换桶的链表内容为树形化内容。
4.3.3 扩容方法 resize()
扩容机制:
-
什么时候才需要扩容
当 HashMap 中的元素个数超过数组大小(数组长度)*loadFactor(负载因子)时,就会进行数组扩容,loadFactor 的默认值是 0.75。
-
HashMap 的扩容是什么
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
HashMap 在进行扩容时,使用的 rehash 方式非常巧妙,因为每次扩容都是翻倍,与原来计算的 (n - 1) & hash 的结果相比,只是多了一个 bit 位,所以结点要么就在原来的位置,要么就被分配到 “原位置 + 旧容量” 这个位置。
例如我们从 16 扩展为 32 时,具体的变化如下所示:

因此元素在重新计算 hash 之后,因为 n 变为 2 倍,那么 n - 1 的标记范围在高位多 1bit(红色),因此新的 index 就会发生这样的变化。

说明:
5 是假设计算出来的原来的索引。这样就验证了上述所描述的:扩容之后所以结点要么就在原来的位置,要么就被分配到 “原位置 + 旧容量” 这个位置。
因此,我们在扩充 HashMap 的时候,不需要重新计算 hash,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就可以了,是 0 的话索引没变,是 1 的话索引变成 “原位置 + 旧容量” 。可以看看下图为 16 扩充为 32 的 resize 示意图:
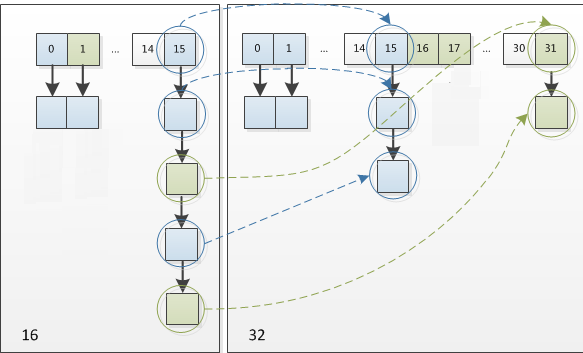
正是因为这样巧妙的 rehash 方式,既省去了重新计算 hash 值的时间,而且同时,由于新增的 1bit 是 0 还是 1 可以认为是随机的,在 resize 的过程中保证了 rehash 之后每个桶上的结点数一定小于等于原来桶上的结点数,保证了 rehash 之后不会出现更严重的 hash 冲突,均匀的把之前的冲突的结点分散到新的桶中了。
源码 resize 方法的解读
下面是代码的具体实现:
final Node<K,V>[] resize() {
// 得到当前数组
Node<K,V>[] oldTab = table;
// 如果当前数组等于null长度返回0,否则返回当前数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//当前阀值点 默认是12(16*0.75)
int oldThr = threshold;
int newCap, newThr = 0;
// 如果老的数组长度大于0
// 开始计算扩容后的大小
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
// 修改阈值为int的最大值
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*
没超过最大值,就扩充为原来的2倍
1) (newCap = oldCap << 1) < MAXIMUM_CAPACITY 扩大到2倍之后容量要小于最大容量
2)oldCap >= DEFAULT_INITIAL_CAPACITY 原数组长度大于等于数组初始化长度16
*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
// 老阈值点大于0 直接赋值
else if (oldThr > 0) // 老阈值赋值给新的数组长度
newCap = oldThr;
else { // 直接使用默认值
newCap = DEFAULT_INITIAL_CAPACITY;//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize最大上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 新的阀值 默认原来是12 乘以2之后变为24
threshold = newThr;
// 创建新的哈希表
@SuppressWarnings({"rawtypes","unchecked"})
//newCap是新的数组长度--》32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 判断旧数组是否等于空
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
// 遍历旧的哈希表的每个桶,重新计算桶里元素的新位置
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 原来的数据赋值为null 便于GC回收
oldTab[j] = null;
// 判断数组是否有下一个引用
if (e.next == null)
// 没有下一个引用,说明不是链表,当前桶上只有一个键值对,直接插入
newTab[e.hash & (newCap - 1)] = e;
//判断是否是红黑树
else if (e instanceof TreeNode)
// 说明是红黑树来处理冲突的,则调用相关方法把树分开
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 采用链表处理冲突
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 通过上述讲解的原理来计算结点的新位置
do {
// 原索引
next = e.next;
// 这里来判断如果等于true e这个结点在resize之后不需要移动位置
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
4.3.4 删除方法 remove()
删除方法就是首先先找到元素的位置,如果是链表就遍历链表找到元素之后删除。如果是用红黑树就遍历树然后找到之后做删除,树小于 6 的时候要转链表。
删除 remove() 方法:
// remove方法的具体实现在removeNode方法中,所以我们重点看下removeNode方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
removeNode() 方法:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 根据hash找到位置
// 如果当前key映射到的桶不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 如果桶上的结点就是要找的key,则将node指向该结点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// 说明结点存在下一个结点
if (p instanceof TreeNode)
// 说明是以红黑树来处理的冲突,则获取红黑树要删除的结点
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// 判断是否以链表方式处理hash冲突,是的话则通过遍历链表来寻找要删除的结点
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 比较找到的key的value和要删除的是否匹配
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 通过调用红黑树的方法来删除结点
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
// 链表删除
tab[index] = node.next;
else
p.next = node.next;
// 记录修改次数
++modCount;
// 变动的数量
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
4.3.5 查找元素方法 get()
查找方法,通过元素的 key 找到 value。
代码如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
get 方法主要调用的是 getNode 方法,代码如下:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 如果哈希表不为空并且key对应的桶上不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
/*
判断数组元素是否相等
根据索引的位置检查第一个元素
注意:总是检查第一个元素
*/
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果不是第一个元素,判断是否有后续结点
if ((e = first.next) != null) {
// 判断是否是红黑树,是的话调用红黑树中的getTreeNode方法获取结点
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 不是红黑树的话,那就是链表结构了,通过循环的方法判断链表中是否存在该key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
小结:
-
get 方法实现的步骤:
a. 通过 hash 值获取该 key 映射到的桶
b. 桶上的 key 就是要查找的 key,则直接找到并返回
c. 桶上的 key 不是要找的 key,则查看后续的结点:如果后续结点是红黑树结点,通过调用红黑树的方法根据 key 获取 value 如果后续结点是链表结点,则通过循环遍历链表根据 key 获取 value -
上述红黑树结点调用的是 getTreeNode 方法通过树形结点的 find 方法进行查找:
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p; // 找到之后直接返回
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
// 递归查找
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
- 查找红黑树,由于之前添加时已经保证这个树是有序的了,因此查找时基本就是折半查找,效率更高。
- 这里和插入时一样,如果对比结点的哈希值和要查找的哈希值相等,就会判断key是否相等,相等就直接返回。不相等就从子树中递归查找。
- 若为树,则在树中通过key.equals(k)查找,O(logn)。若为链表,则在链表中通过key.equals(k)查找,O(n)。
4.3.6 遍历 HashMap 集合几种方式
- 分别遍历 Key 和 Values
for (String key : map.keySet()) {
System.out.println(key);
}
for (Object vlaue : map.values() {
System.out.println(value);
}
- 使用 Iterator 迭代器迭代
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> mapEntry = iterator.next();
System.out.println(mapEntry.getKey() + "---" + mapEntry.getValue());
}
- 通过 get 方式(不建议使用)
Set<String> keySet = map.keySet();
for (String str : keySet) {
System.out.println(str + "---" + map.get(str));
}
说明:
根据阿里开发手册,不建议使用这种方式,因为迭代两次。keySet 获取 Iterator一次,还有通过 get 又迭代一次,降低性能。
- jdk8 以后使用 Map 接口中的默认方法:
default void forEach(BiConsumer<? super K,? super V> action)
// BiConsumer接口中的方法:
void accept(T t, U u) 对给定的参数执行此操作。
参数
t - 第一个输入参数
u - 第二个输入参数
遍历代码:
HashMap<String,String> map = new HashMap();
map.put("001", "zhangsan");
map.put("002", "lisi");
map.forEach((key, value) -> {
System.out.println(key + "---" + value);
});
五、设计 HashMap 的初始化容量
5.1 问题描述
如果我们确切的知道我们有多少键值对需要存储,那么我们在初始化 HashMap 的时候就应该指定它的容量,以防止 HashMap 自动扩容,影响使用效率。
默认情况下 HashMap 的容量是 16,但是,如果用户通过构造函数指定了一个数字作为容量,那么 Hash 会选择大于该数字的第一个 2 的幂作为容量(3->4、7->8、9->16)。这点我们在上述已经进行过讲解。
5.2 《阿里巴巴Java开发手册》的建议
《阿里巴巴Java开发手册》原文:

关于设置 HashMap 的初始化容量:
我们上面介绍过,HashMap 的扩容机制,就是当达到扩容条件时会进行扩容。HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容。所以,如果我们没有设置初始容量大小,随着元素的不断增加,HashMap 会有可能发生多次扩容,而 HashMap 中的扩容机制决定了每次扩容都需要重建 hash 表,是非常影响性能的。
但是设置初始化容量,设置的数值不同也会影响性能,那么当我们已知 HashMap 中即将存放的 KV 个数的时候,容量设置成多少为好呢?
关于设置 HashMap 的初始化容量大小:
可以认为,当我们明确知道 HashMap 中元素的个数的时候,把默认容量设置成 initialCapacity/ 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
而 Jdk 并不会直接拿用户传进来的数字当做默认容量,而是会进行一番运算,最终得到一个 2 的幂。