概念
文件系统
磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍。
文件系统块一般为几千字节,磁盘块一般512字节。
hdfs的block、pocket、chunk
-
block
hdfs的块,常说的block,是这三个里最大的单位。默认128MB(配置参数:dfs.block.size)。
128MB的原因:块太小会增加寻址时间;块太大会减少Map的任务(通常一个Map只处理一个块的数据)。
注:文件的大小小于一个block并不会占据整个block的空间,如一个1M的文件存储在128MB的block中时,并不是占用128MB的的磁盘空间,而是1MB。
-
pocket
这三个里面中等大小的单位,DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
-
chunk
是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
分布式文件系统使用块的好处
- 一个文件的大小可以大于网络中任意磁盘的容量。
- 使用抽象快而不是整个文件作为存储,大大简化了存储子系统的设计。
文件读

- 客户端调用FileSyste对象的open()方法打开要读取的文件。
- DistractedFileSystem通过远程过程调用(RPC)来调用namenode,以获取文件的其实位置。对于每一个块,namenode返回该副本的datanode的地址。这些datanode根据它们与客户端的距离来排序(根据集群的网络拓扑)。如果客户端本身就是一个datanode,那么会从保存相应数据块副本的本地datanode读取数据。
- DistrubutedFileSystem返回一个FSDataInputStream对象(支持文件定位的数据流)给客户端便读取数据。FSDataInputStream转而封装DFSInputStream对象,它管理datanode和namenode的I/O。接着客户端对这个数据流调用read()。
- 存储着文件的块的datanode地址的DFSInputStream会连接距离最近的文件中第一个块所在的datanode。反复调用read()将数据从datanode传输到客户端。
- 读到块的末尾时,DFSInputStream关闭与前一个datanode的连接,然后寻找下一个块的最佳datanode。
- 客户端的读写顺序时按打开的datanode的顺序读的,一旦读取完成,就对FSDataIputStream调用close()方法。
在读取数据的时候,datanode一旦发生故障,DFSInputStream会尝试从这个块邻近的datanode读取数据,同时也会记住哪个故障的datanode,并把它通知到namenode。
文件写
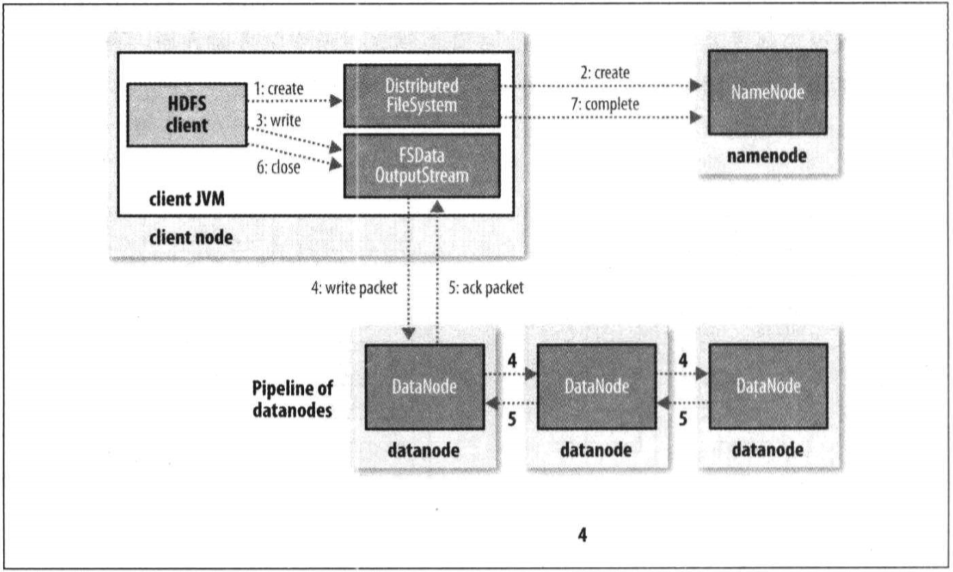
- 客户端通过调用DistributedFileSystem的create()方法新建文件。
- DistributedFileSystem对namenode创建RPC调用,在文件系统的命名空间新建一个文件,此时该文件还没有相应的数据块。
- namenode执行各种检查以确保这个文件不存在以及客户端新建文件的权限。如果各种检查都通过,就创建;否则抛出IO异常。DistributedFileSystem向客户端返回一个FSDataOutputStream对象,由此客户端开始写入数据,FSDataOutputStream会封装一个DFSoutPutstream对象,负责namenode和datanode之间的通信。
- DFSOutPutstream将数据分成一个个的数据包(packet),并写入内部队列,即数据队列(data queue),DataStreamer处理数据队列,它将选择一组datanode,并据此要求namenode重新分配新的数据块。这一组datanode构成管线,假设副本数是3,所以管线有3个节点。DataStreamer将数据包流式传输到第一个datanode,该datanode存储数据包并发送给第二个datanode。。。依次类推,直到最后一个。【面试题】
- DFSOutPutstream维护了一个数据包队列等待datanode的收到确认回执,成为确认队列(ack queue),每一个datanode收到数据包后都会返回一个确认回执,然后放到这个ack queue,等所有的datanode确认信息后,该数据包才会从队列ack queue删除。
- 完成数据写入后,对数据流调用close。
在写入过程中datanode发生故障,将执行以下操作
1)关闭管线,把队列的数据报都添加到队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。
2)为存储在另一个正常的datanode的当前数据块指定一个新的标识,并把标识发送给namenode,以便在datanode恢复正常后可以删除存储的部分数据块。
3)从管线中删除故障datanode,基于正常的datanode构建一条新管线。余下的数据块写入管线中正常的datanode。namenode注意到块副本数量不足,会在另一个节点上创建一个新的副本。后续的数据块正常接受处理。
如果多个datanode发生故障(非常少见)
只要写入了dfs.namenode.replication.min的副本数(默认1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目的的副本数(dfs.replication的默认值3)
参考
hadoop权威指南