数据库的选型
对于很多程序员来说,公司选择什么样的数据库,基本不需要你来决定。当你加入一个公司的时候,公司的大部分技术选型已经确认,特别是数据库选型,因为数据库一旦选择,后期迁移的代价还是很大的。
![]()
随着大数据时代的来临,涌现出了很多新型数据库,在公司遇到数据性能瓶颈,喊去IOE口号或者是想尝鲜时,都会慢慢的使用新型数据库。但是无论是技术选型还是转型,你都不能忽略一个因素:你选的数据库技术你能驾驭吗?
我们知道,现在有很多开源数据库可以让我们选择,但是我们有相关的技术人员精通这些数据库吗?比如GreenPlum这款数据,有开源版本,也有商业公司在运作,我们看到官方宣传的案例很好,查询效率很高。在一些大数据量查询聚合也比Oracle快一点。但是作为生产数据库使用,随着数据量的增加,你会发现各种你之前没有了解到的问题,对于开发人员来说,比之前的Oracle难用多了。这时候你可能会寻求商业公司的帮助,r派来高级工程师对数据库进行巡检后,提出了很多优化方案、使用规范和管理策略,这些都是你之前不曾了解的。
很多人看到了BAT用的很好,自己就去尝试,并很快用于生产。你可以看看BAT有多少研究员,可能你的公司一个都没有。很多人会问,postgreSQL宣传的很好,我们替换掉MySQL吧。一个公司的数据库如果从来不出现问题,那一定是没有业务量,一旦业务量上来,就会遇到各种问题,这时候什么最重要?救火!所以在数据库出现问题时,公司是否有足够专业的工程师去解决问题是很重要的。所以,对很多想要去O的公司来说,你要想好如何选型新技术。看着开源的免费,贸然使用会付出更多代价。
技术更新很快,还是希望大家在测试开发时候使用新技术,逐步精通的过程中,缓慢过度生产,如果公司有预算,可以请商业公司进行指导半年到一年,自己人学到精髓后再开展独立运维。
数据库如何避坑
再好的数据库,如果使用姿势不对也是枉然,更何况很多程序员并不怎么懂数据库。在数据库使用中,我们常会碰到很多问题。
-
人为失误
![]()
人为失误一般分两类,一种是DBA操作失误,一种是程序员开人员程序里使用不当。DBA一般我们认为是数据库管理的专家了,出错的概率比较小,但是一旦出错,危险是做大的。比如我们经常调侃的“删库跑路”,虽然是依据调侃,但是我是真真的见到过两次,生产环境出现一次,就会在你的工作生涯上记上“光辉”一笔,所以说DBA算是一个高危工作了吧。另一种是开发人员使用不当。常见的比如在使用大表时候,不考虑是否有索引,进行了全表扫描,导致整个数据库被拖垮。
-
数据库的访问瓶颈
只要是数据库,就会有并发量的限制。以前使用MySQL,我们经常看到互联网公司并发上万的压测。但是对于很多新型的MPP数据库,他们的并发并不是你想的那样,MPP一般由集群CPU物理核数有关。比如以前开发程序查询的MySQL,迁移到GP,那么你的数据库连接池要改一改了。特别是对于一些面向互联网的网站,数据库管理层也要做访问策略,不然,一个外挂可能就会把你的库搞死。
-
索引
我们都知道索引在传统的关系型数据库中使用的很多,效果也很明显。但是你要知道索引是拿存储换时间的操作。曾遇到过开发人员动不动就让建索引,搞的好像不要钱一样。还有像Vertica(适用OLAP场景)这个数据库就比较友好了,不需要建立索引,只需要在建表时候预排序分布即可提高查询效率,同时列存储的数据还是压缩的,降低了存储,还提高了查询效率。
-
HA(高可用)
数据库作为存储查询引擎的同时,支撑着大型网站的后台服务,一定要考虑高可用。对于一些天然不支持高可用或者高可用不友好的选型一定要小心。再来安利一下Vertica,无Master MPP架构,集群中只要不超过一半机器宕机(物理位置不相邻),集群就处于可用状态。
-
标准SQL
SQL就是针对数据库查询产生的语言。随着新型数据库的出现,很多数据库不支持标准SQL或者支持很弱。比如HBase。这对于很多以前的开发人员还是有一定学习门槛的,还有就是后期如果出现业务迁移还是很困难的。
Oracle支持标准SQL,但是存储过程并不是每个数据库都有的,这也是阿里为何禁用存储过程的吧,你无法想象一个上万行存储过程的迁移要耗费多少资源。对标准SQL的支持,降低了开发人员的使用门槛,也降低了以后业务迁移的风险。
数据库发展期望
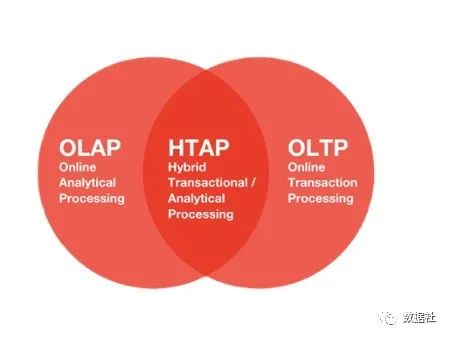
我们会发现传统的MySQL数据库对于并发联机事务处理支持很好,但是随着互联网和物联网发展,很多场景下无法单独使用MySQL做支撑,我们通常选引入大数据技术比如HBase辅助,或者搜索引擎。在分析领域我们选择Hadoop和MPP数据库作为支撑,效果也很好,但是越多的技术栈意味着越多的学习成本和风险。
听过PingCAP提出的HTAP架构。数据是系统架构的中心,但过去的系统通常都只能解决一部分场景的问题,在 OLTP,OLAP,数据仓库方面各有侧重,现在终于走向更全能的 HTAP 架构,在一致性、可用性、可扩展性上取得平衡,充分利用云的弹性供给能力和动态调度能力,并且降低运维成本和系统复杂性。
如果出现了一款数据库能够两者兼顾,那必然是美好的。也许还会其他更好的方案,不管怎样,我们会逐步看到更多以数据为中心的架构,更好应对业务和环境的复杂性,响应需求的变化,数据库领域的未来还有许多探索空间~