Kafka 0.9版本开始推出了Java版本的consumer,优化了coordinator的设计以及摆脱了对zookeeper的依赖。社区最近也在探讨正式用这套consumer API替换Scala版本的consumer的计划。鉴于目前这方面的资料并不是很多,本文将尝试给出一个利用KafkaConsumer编写的多线程消费者实例,希望对大家有所帮助。
这套API最重要的入口就是KafkaConsumer(o.a.k.clients.consumer.KafkaConsumer),普通的单线程使用方法官网API已有介绍,这里不再赘述了。因此,我们直奔主题——讨论一下如何创建多线程的方式来使用KafkaConsumer。KafkaConsumer和KafkaProducer不同,后者是线程安全的,因此我们鼓励用户在多个线程中共享一个KafkaProducer实例,这样通常都要比每个线程维护一个KafkaProducer实例效率要高。但对于KafkaConsumer而言,它不是线程安全的,所以实现多线程时通常由两种实现方法:
1 每个线程维护一个KafkaConsumer
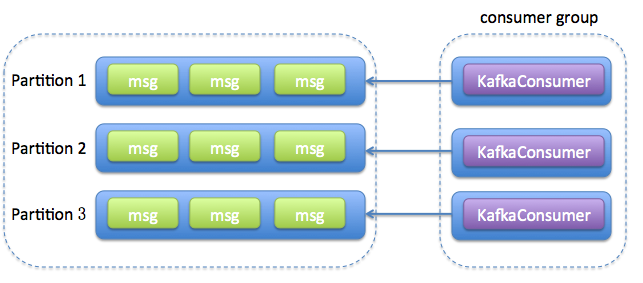
2 维护一个或多个KafkaConsumer,同时维护多个事件处理线程(worker thread)

当然,这种方法还可以有多个变种:比如每个worker线程有自己的处理队列。consumer根据某种规则或逻辑将消息放入不同的队列。不过总体思想还是相同的,故这里不做过多展开讨论了。
下表总结了两种方法的优缺点:
| 优点 | 缺点 | |
| 方法1(每个线程维护一个KafkaConsumer) | 方便实现 速度较快,因为不需要任何线程间交互 易于维护分区内的消息顺序 |
更多的TCP连接开销(每个线程都要维护若干个TCP连接) consumer数受限于topic分区数,扩展性差 频繁请求导致吞吐量下降 线程自己处理消费到的消息可能会导致超时,从而造成rebalance |
| 方法2 (单个(或多个)consumer,多个worker线程) | 可独立扩展consumer数和worker数,伸缩性好 |
实现麻烦
通常难于维护分区内的消息顺序
处理链路变长,导致难以保证提交位移的语义正确性
|
下面我们分别实现这两种方法。需要指出的是,下面的代码都是最基本的实现,并没有考虑很多编程细节,比如如何处理错误等。
方法1
ConsumerRunnable类
1 import org.apache.kafka.clients.consumer.ConsumerRecord; 2 import org.apache.kafka.clients.consumer.ConsumerRecords; 3 import org.apache.kafka.clients.consumer.KafkaConsumer; 4 5 import java.util.Arrays; 6 import java.util.Properties; 7 8 public class ConsumerRunnable implements Runnable { 9 10 // 每个线程维护私有的KafkaConsumer实例 11 private final KafkaConsumer<String, String> consumer; 12 13 public ConsumerRunnable(String brokerList, String groupId, String topic) { 14 Properties props = new Properties(); 15 props.put("bootstrap.servers", brokerList); 16 props.put("group.id", groupId); 17 props.put("enable.auto.commit", "true"); //本例使用自动提交位移 18 props.put("auto.commit.interval.ms", "1000"); 19 props.put("session.timeout.ms", "30000"); 20 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 21 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 22 this.consumer = new KafkaConsumer<>(props); 23 consumer.subscribe(Arrays.asList(topic)); // 本例使用分区副本自动分配策略 24 } 25 26 @Override 27 public void run() { 28 while (true) { 29 ConsumerRecords<String, String> records = consumer.poll(200); // 本例使用200ms作为获取超时时间 30 for (ConsumerRecord<String, String> record : records) { 31 // 这里面写处理消息的逻辑,本例中只是简单地打印消息 32 System.out.println(Thread.currentThread().getName() + " consumed " + record.partition() + 33 "th message with offset: " + record.offset()); 34 } 35 } 36 } 37 }
ConsumerGroup类
1 package com.my.kafka.test; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 public class ConsumerGroup { 7 8 private List<ConsumerRunnable> consumers; 9 10 public ConsumerGroup(int consumerNum, String groupId, String topic, String brokerList) { 11 consumers = new ArrayList<>(consumerNum); 12 for (int i = 0; i < consumerNum; ++i) { 13 ConsumerRunnable consumerThread = new ConsumerRunnable(brokerList, groupId, topic); 14 consumers.add(consumerThread); 15 } 16 } 17 18 public void execute() { 19 for (ConsumerRunnable task : consumers) { 20 new Thread(task).start(); 21 } 22 } 23 }
ConsumerMain类
1 public class ConsumerMain { 2 3 public static void main(String[] args) { 4 String brokerList = "localhost:9092"; 5 String groupId = "testGroup1"; 6 String topic = "test-topic"; 7 int consumerNum = 3; 8 9 ConsumerGroup consumerGroup = new ConsumerGroup(consumerNum, groupId, topic, brokerList); 10 consumerGroup.execute(); 11 } 12 }
方法2
Worker类
1 import org.apache.kafka.clients.consumer.ConsumerRecord; 2 3 public class Worker implements Runnable { 4 5 private ConsumerRecord<String, String> consumerRecord; 6 7 public Worker(ConsumerRecord record) { 8 this.consumerRecord = record; 9 } 10 11 @Override 12 public void run() { 13 // 这里写你的消息处理逻辑,本例中只是简单地打印消息 14 System.out.println(Thread.currentThread().getName() + " consumed " + consumerRecord.partition() 15 + "th message with offset: " + consumerRecord.offset()); 16 } 17 }
ConsumerHandler类
1 import org.apache.kafka.clients.consumer.ConsumerRecord; 2 import org.apache.kafka.clients.consumer.ConsumerRecords; 3 import org.apache.kafka.clients.consumer.KafkaConsumer; 4 5 import java.util.Arrays; 6 import java.util.Properties; 7 import java.util.concurrent.ArrayBlockingQueue; 8 import java.util.concurrent.ExecutorService; 9 import java.util.concurrent.ThreadPoolExecutor; 10 import java.util.concurrent.TimeUnit; 11 12 public class ConsumerHandler { 13 14 // 本例中使用一个consumer将消息放入后端队列,你当然可以使用前一种方法中的多实例按照某张规则同时把消息放入后端队列 15 private final KafkaConsumer<String, String> consumer; 16 private ExecutorService executors; 17 18 public ConsumerHandler(String brokerList, String groupId, String topic) { 19 Properties props = new Properties(); 20 props.put("bootstrap.servers", brokerList); 21 props.put("group.id", groupId); 22 props.put("enable.auto.commit", "true"); 23 props.put("auto.commit.interval.ms", "1000"); 24 props.put("session.timeout.ms", "30000"); 25 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 26 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 27 consumer = new KafkaConsumer<>(props); 28 consumer.subscribe(Arrays.asList(topic)); 29 } 30 31 public void execute(int workerNum) { 32 executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS, 33 new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy()); 34 35 while (true) { 36 ConsumerRecords<String, String> records = consumer.poll(200); 37 for (final ConsumerRecord record : records) { 38 executors.submit(new Worker(record)); 39 } 40 } 41 } 42 43 public void shutdown() { 44 if (consumer != null) { 45 consumer.close(); 46 } 47 if (executors != null) { 48 executors.shutdown(); 49 } 50 try { 51 if (!executors.awaitTermination(10, TimeUnit.SECONDS)) { 52 System.out.println("Timeout.... Ignore for this case"); 53 } 54 } catch (InterruptedException ignored) { 55 System.out.println("Other thread interrupted this shutdown, ignore for this case."); 56 Thread.currentThread().interrupt(); 57 } 58 } 59 60 }
Main类
1 public class Main { 2 3 public static void main(String[] args) { 4 String brokerList = "localhost:9092,localhost:9093,localhost:9094"; 5 String groupId = "group2"; 6 String topic = "test-topic"; 7 int workerNum = 5; 8 9 ConsumerHandler consumers = new ConsumerHandler(brokerList, groupId, topic); 10 consumers.execute(workerNum); 11 try { 12 Thread.sleep(1000000); 13 } catch (InterruptedException ignored) {} 14 consumers.shutdown(); 15 } 16 }
总结一下,这两种方法或是模型都有各自的优缺点,在具体使用时需要根据自己实际的业务特点来选取对应的方法。就我个人而言,我比较推崇第二种方法以及背后的思想,即不要将很重的处理逻辑放入消费者的代码中,很多Kafka consumer使用者碰到的各种rebalance超时、coordinator重新选举、心跳无法维持等问题都来源于此。