文件的基本操作
r:只读(默认),不能写,在打开文件时,r可以省略不写,打开不存在的文件会报错

w:只写模式,不可读:不存在的文件则会创建,存在的文件会清空文件内容

a:追加模式,不可读:不存在的文件会创建,存在的文件会追加

r+:可读,可写,。打开不存在的文件会报错

w+:读写模式,已经存在的文件,内容会被清空,可以读到已经写得内容

a+:追加读写模式,不存在则创建,存在则只追加内容

文件的操作方法
readlines():读取文件所有内容,把每行的内容放到一个list里面

readline():读取文件里面第一行的内容
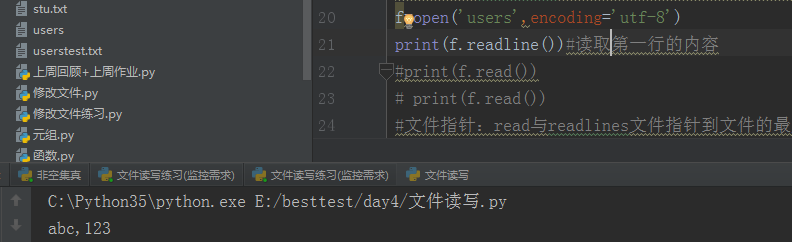
read():读取文件的所有内容
seek():文件指针
1、当前文件指针指到哪,seek(0):指到文件的最前面
2、read与readlines文件指针到文件的最后一行;readline文件指针到第二行

write():写入内容,传的内容必须得是字符串
flush():写入文件后,刷新缓冲区,立即写到磁盘上.例如f.write()文件没有写入成功,那就就要用.flush方法,文件就会更新,即写入成功了
tell():获取当前文件的指针指向
truncate():清空文件内容
writelines():会循环list里面的每一个元素都写进文件里面去
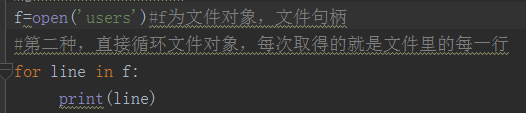
高效读取文件
思路:直接循环文件对象,每次取得的就是文件里的每一行,直接使用for循环即可
with使用方法
with:会在使用完这个文件之后,自动关闭文件,用法如下:

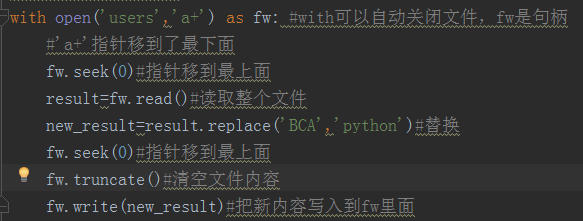
修改文件
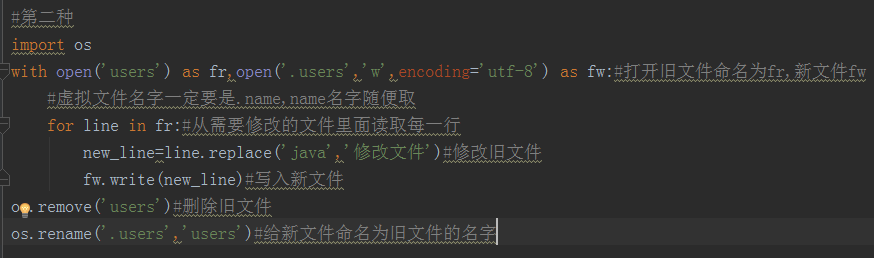
修改文件的话,有两种方式,一种是把文件的全部内容都读到内存中,然后把原有的文件内容清空,重新写新的内容;第二种是把修改后的文件内容写到一个新的文件中
第一种:
第二种:
非空即真、非0即真
TRUE:真
false:'' none,[],{}
非空即真:
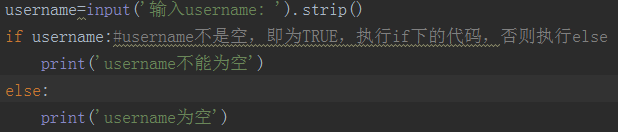
非0即真:

练习:
#-*-coding:utf-8-*-
#需求:每分钟监控服务器日志,IP请求超过200次的,加入黑名单
#
#1、读文件,获取到每行的内容,open readlines
# 178.210.90.90 - - [04/Jun/2017:03:44:13 +0800]
#2、找到IP,按照空格分隔字符串,取第一个元素,split
# 3、把IP存到字典里,每个IP出现一次,IP次数就+1
# 4、判断IP次数是否大于200,加入黑明单
import time
point=0#定义一个指针为0,即在文件的最上边
while True:#循环
ips={}#定义一个空字典
f=open('access.log',encoding='utf-8')
f.seek(point)#指定到指针的位置
for line in f.readlines():#循环文件里的每一行,即生成list
#获取所有的IP和次数存在字典里
ip=line.split()[0]#list里面按照空格分隔字符串,第一个元素即为ip,存在变量ip里面
#print(ip)
if ip not in ips:#
ips[ip]=1#如果从list里面取到的ip不在字典ips里面,那么这个ip对应的value=1
else:
ips[ip]+=1#如果从list里面取到的ip在字典ips里面,那么这个ip对应的value的值就+1
point=f.tell()#记录读完之后的文件指针
for k,count in ips.items():
if count>200:
print('[%s]加入黑明单 '%ip)
#print(ips)
time.sleep(60)
修改文件:
文件内容如下:

#-*-coding:utf-8-*-
# 把文件里面没有交作业的人名字后面加上‘没有交’
# 已经交作业的加上‘交了’
# 1、读文件
# 2、按照空格分隔每个人的作业信息
import os
with open('stu.txt',encoding='utf-8')as fr,open('.new_stu','w',encoding='utf-8')as fw:#打开两个文件
for line in fr:#在fr里面循环取每一行的数据
line_list=line.split()#按照空格分隔字符串,生成list
if len(line_list)>1:
line_list[-1]='已交 '
else:
line_list.append('未交 ')
fw.writelines(line_list)
os.remove('stu.txt')
os.rename('.new_stu','stu.txt')