最近v2ex论坛上出现一篇很热门的帖子《QQ正在尝试读取你的浏览记录》,题目很耸动,结果也很令人吃惊。
简要介绍一下事情的来龙去脉,楼主反映火绒杀毒软件提示QQ正在触发一些规则,QQ尝试读取用户的AppDataLocalGoogleChromeUser DataDefaultHistory等目录,目录中的信息为用户浏览器历史记录。有点东西,随后看雪平台的安全大佬对行为进行了逆向分析([原创]关于QQ读取Chrome历史记录的澄清),其先读取各种 User DataDefaultHistory 文件,读到了就复制到Temp目录下的temphis.db。然后再用SQLite读取数据库,然后“select url from urls”,获取到用户的历史信息域名,至于获取这些域名信息后面的操作已经可以猜到了!
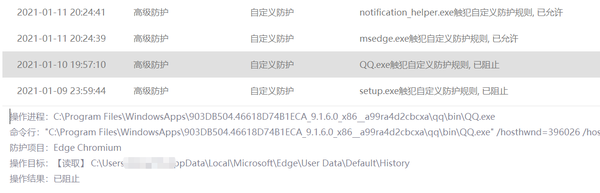
结论,QQ并不是特意读取Chrome的历史记录的,而是会试图读取电脑里所有谷歌系浏览器的历史记录并提取链接,确认会中招的浏览器包括但不限于Chrome、Chromium、360极速、360安全、猎豹、2345等浏览器。
大部分的浏览器都会中招,QQ就这么轻而易举地扒掉了浏览器的“底裤”。
对于后面的结果我不太惊讶,我吃惊于为何手段如此简单。
过去经常有人发出“手机窃听说话、聊天信息导致app推荐如此之准”的疑惑,作为一名算法工程师,我对于推荐的精准一点都不意外,因为基于用户的大量浏览记录、留存于app上的基础信息和目前所在环境信息,这些大量的用户信息在模型的“召回-》精排-》粗排”过后给用户推荐出感兴趣的音乐、视频、新闻并不是一件什么困难的事情。
但是,数据的获取细节,我们可能也不太了解。对于数据来源,我以前的猜想是用户在app上的点击埋点信息以及集团下面的兄弟企业间的信息共享就可以达到我在百度搜索了团建游戏,微信朋友圈就有望京小腰的广告推荐。
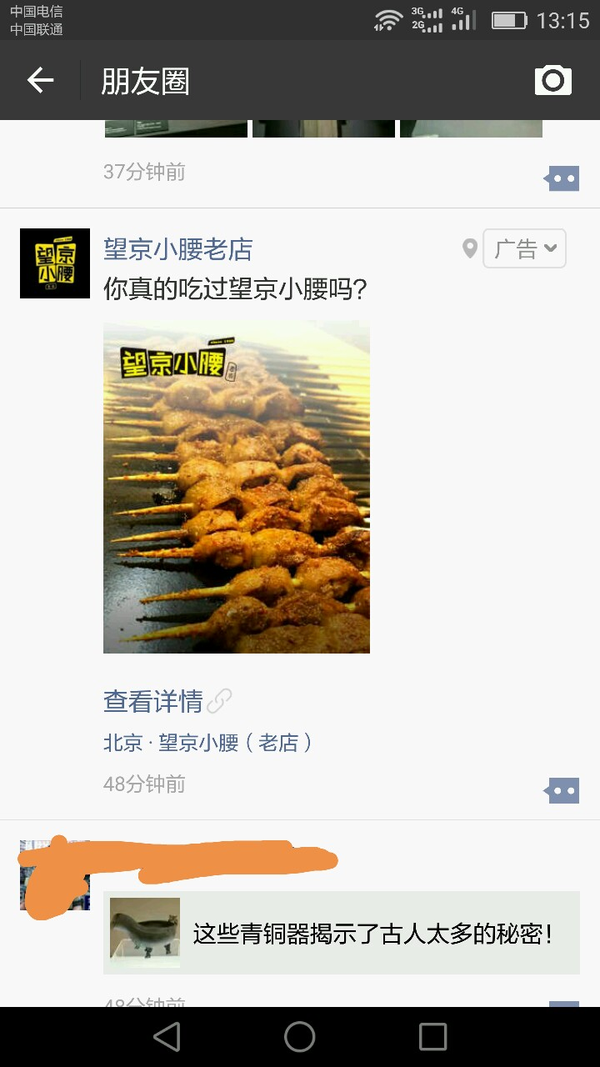
只要友商够多,收购的小弟们够多,这种做法理论上是行得通的,也是有效的。但是这种模式相当受限,想让百度、阿里、腾讯进行这种准实时的数据合作相当之难。而且,在技术层面想达到服务间的数据及时共享也得耗费大量人力财力。

直接扒浏览器文件夹,相较于我的猜想可谓是神之一手,不用商务去对接“友商”,不用产品去互啃对方文档,不用技术加班996,只用把文件夹复制一份就搞定,妙!
不过,目前的一些信息也只是两位热心市民的自助探索,到底腾讯对这一步技术操作如何解释,我也相当好奇(吃瓜
最后,提醒各位一句,互联网上无隐私,保护好自己,你偷偷看的东西,还有一群人在帮你分析=。=
插图来源:帆咔嚓@FanKetchup
微信公众号:正版乔