在上spark的时候,一开始需要虚拟机模拟真实环境,而spark主要的三种模式:local、standalone、yarn 均可以通过虚拟机模拟。
这里要讨论的是业务逻辑如何和 spark 结合,具体技术细节可自行查阅资料。
抛开技术层面,spark 针对的是,数据集的并行操作或者计算逻辑的并行操作:
(1)数据集的并行操作指的是,假设你拥有海量数据(在此并不定义数据集的大小),可以通过将数据集合切分(等切或者非等切,非等切可能需要加入其他操作),一台或者多台机器同时对切分的数据集进行操作;可以理解为数据集的并行 HDFS 文件系统;例如:
sc.textFile(paths, minPartitions)
(2)计算逻辑的并行操作,即拥有的一批数据,需要做同样的业务逻辑操作,即可以将这个业务逻辑分发至每台机器,并行计算,从而快速得到计算结果。同时也可能会涉及 sc.makeRDD( ) 等函数的调用。例如:
case class Person(name: String, age: Int)
// 构造样例类
val people: RDD[Person] = ...
// map 执行逻辑函数 或者与其他的算法结合
people.map(逻辑函数)
people.foreach(println)
需要掌握map函数的使用,在调入其他变量的时候,会有很重要的作用。
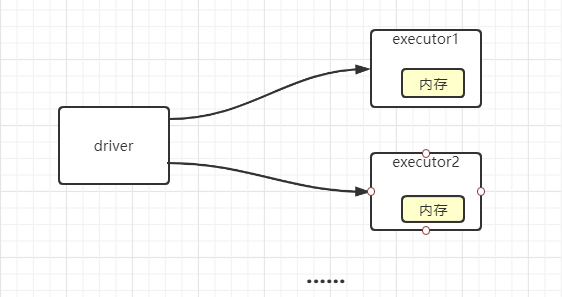
逻辑操作的并行,需要注意内存问题,如果没有使用broadcast,那executers 或者driver 有可能都复制了内存,所以需要考虑优化内存的问题。
另外一点,当 spark 与 SQL 结合的时候,可以通过自定义UDF函数,在SQL中使用,仅针对改变 sql数据表的数据。例如:
spark.udf.register(
"函数名", // 函数名称
(参数) => { // 函数体
// 操作逻辑
}
)
然后在 SQL 语句中调用这个 "函数名" 函数,例如,
"SELECT 函数名(参数) AS 别名 FROM 表"
当然,通过 DSL(采用DSL方式读取Hive表数据)的方式也是可以的,也是在执行语句进行填写,这里不作展开了。
备注:一般数据集合均可以进行并行读取,但是如果数据集不大,且又是对单个对象操作,这时强行使用spark不便下手了。