【译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正】
原文链接:传送门。
在本系列中,我们常常说一个特定的查询以一个特定的方式执行。我们引用生成的执行计划来支持我们的说明,SSMS对预估的和实际的查询计划的显示能够帮助你决定索引是否有益或者是否缺失,因此,本章节的目的是给足够的关于查询计划的知识,使得你可以:
- 当你读此系列文章时候验证我们的推断。
- 决定你的索引对于查询是否有益。
有许多文章是关于阅读执行查询计划的,包含了MSDN的一些文章。我们在这儿的打算不是扩展或者替换它们。事实上,在本章节我们将提供它们的许多链接。显示图形化的查询计划是个好的开始(http://msdn.microsoft.com/en-us/library/ms178071.aspx)。其他有用的资源包括Grant Fritchey的书SQL Server Execution Plans(电子书免费),以及Fabiano Amorim关于各种操作符(它们显示在查询计划输出窗口)的简单讨论文章(http://www.simple-talk.com/author/fabiano-amorim/)。
图形化的查询计划
查询计划是SQL SERVER执行计划时所遵循的一组指令。SSMS会为你以文本,图形化以及XML的形式显示一个查询计划。例如,考虑如下简单的查询:
SELECT LastName, FirstName, MiddleName, Title  FROM Person.Contact WHERE Suffix = 'Jr.' ORDER BY Title
这个查询的计划在图1会被看到。
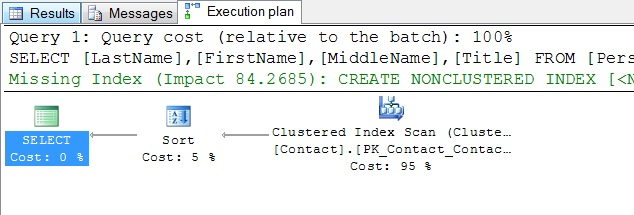
图1:图形化的查询计划
相应的,它也能以文本的形式展示。
|--Sort(ORDER BY:([AdventureWorks].[Person].[Contact].[Title] ASC)) |--Clustered Index Scan(OBJECT:([AdventureWorks].[Person].[Contact].[PK_Contact_ContactID]), WHERE:([AdventureWorks].[Person].[Contact].[Suffix]=N'Jr.'))
或者作为一个XML文档,它会以这样的格式开始:
我们可以以如下方式显示查询计划:
为了显示图形化的查询计划,我们可以使用SSMS的SQL编辑工具条(SQL Editor Toolbar),它有一个“显示预估的执行计划”(Show Estimated Execution Plan)和“包含实际的执行计划”(Include Actual Execution Plan)两个按钮。"显示预估的执行计划" 立即展示所选择的TSQL代码的执行计划图形,而不必执行这个查询;“包含实际的执行计划”按钮是一个开关,一旦当你选择了这个选项,每一个你执行的查询批处理,除了展示执行结果和消息之外,都会打开一个新的标签页,为你展示它的查询计划图形。这个在图1中便可以看到。
为了查看文本格式的执行计划,可以使用SET SHOWPLAN_TEXT ON语句。打开文本格式的执行计划会关闭图形格式的执行计划并且不会执行任何一个你的查询。
为了查看XML格式的执行计划,右键图形化的执行计划,从上下文菜单中选择"显示执行计划XML"。
本章的剩余部分我们将关注图形化显示,因为它通常提供了对于执行计划的最快速的理解,对于一个查询计划来说,一张图片通常会比一段文字更好理解。
读懂图形化的执行计划
图形化的执行计划通常从右至左阅读,最右边的图标代表着数据收集流的第一步。这通常是对一个堆或者聚集索引的访问。你会发现我们这儿不会使用表这个词语,进一步,你会看到聚集索引扫描或堆扫描,这是我们看到的第一个地方,可以看到哪些索引被用到了,如果确实有索引的话。
图形化查询计划里每一个图标都代表了一个操作,关于可能的图标的更多额外的信息,请查阅MSDN相关主题:http://msdn.microsoft.com/en-us/library/ms175913.aspx。
连接操作的箭头代表了数据行,从一个操作流向另一个下一个操作。
把鼠标放在图标或者箭头上会显示额外的信息。
不要把一个操作当做一个步骤,因为这暗示着一个操作在下一个操作开始之前必须完成,而这并不总是正确的。举例来说,当一个WHERE字句被计算时,也就是说,当一个过滤操作进行时,数据行一次只计算一个,而并不是一次性计算全部,在下一个数据行到达过滤操作之前,一个数据行可以已经移动到下一个操作节点中。而另一方面,一个排序操作,必须被全部处理完,它的第一个数据才能到达下一个处理节点。
使用一些额外信息
图形化的查询计划显示了两条潜在的有用信息,它们不是计划本身的一部分,建议的索引和各个操作的相关的开销。
在上面的例子中,建议索引以绿色显示并因为空间需要被截断,建议在Contact表的Suffix列加一个非聚集索引,并把这几列作为包含列:Title, FirstName, MiddleName, and LastName。
这个查询各个操作的相关的开销告知我们排序操作占了总开销的5%,同时表扫描占了95%。因此,如果我们想提高这个查询的性能,我们应该讨论这个表扫描,而不是排序操作,这也是为什么会建议一个索引,如果我们创建了建议的索引,如这样:
CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact ( Suffix ) INCLUDE ( Title, FirstName, MiddleName, LastName )
我们回到那个查询,逻辑读从569掉到3,如下显示的新的查询计划显示了为什么会发生这样。

新的非聚集索引,具有一个索引键:Suffix,使得“WHERE Suffix = 'Jr.'“的条目聚集在一起,因此减少了返回数据所需要的IO数。其结果就是,这个和之前计划一样的排序操作,现在占了这个查询计划总开销的75%,而不是它曾经占的5%了。因此,原来的计划需要75/5 = 15倍的工作来收集和当前计划一样的信息。
既然我们的WHERE子句仅仅包含一个相等操作符,我们能进一步更新我的索引,将Title 列移动到索引键中,像这样:
IF  EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID(N'Person.Contact') AND name = N'IX_Suffix') DROP INDEX IX_Suffix ON Person.Contact CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact ( Suffix, Title ) INCLUDE ( FirstName, MiddleName, LastName )
现在所需要的条目仍然聚集在索引中,并在各个聚集内,它们按照请求顺序排列(Now, the needed entries are still clustered together within the index, and within each cluster they are in the requested sequence; as indicated by the new query plan, shown in Figure 2.)。如同图2所显示的新的查询计划指示的。

图2:重建非聚集索引后的查询计划
查询计划现在显示排序操作已不再需要了。在此刻我们可以扔掉最有益的覆盖索引,这将恢复Contact 表到我们最开始时候的方式,这是进入下一主题之前我们想让它处于的状态。
下一节,我们将讨论并行数据处理,排序,预排序,以及哈希操作。谢谢阅读与支持。