一、说明:
在 Python 中处理文本数据是使用 str 对象,也称为 字符串。
字符串是由 Unicode 码位构成的不可变 序列。 字符串字面值有多种不同的写法:
字符串字面值有三种不同的写法:
- 单引号
- 双引号
- 三重引号
使用三重引号的字符串可以跨越多行 —— 其中所有的空白字符都将包含在该字符串字面值中。
作为单一表达式组成部分,之间只由空格分隔的多个字符串字面值会被隐式地转换为单个字符串字面值。 也就是说,("spam " "eggs") == "spam eggs"。
由于不存在单独的“字符”类型,对字符串做索引操作将产生一个长度为 1 的字符串。 也就是说,对于一个非空字符串 s, s[0] == s[0:1]。
不存在可变的字符串类型,但是 str.join() 或 io.StringIO 可以被被用来根据多个片段高效率地构建字符串。
io.StringIO() 是以字符串的方式从内存中的文件读取数据。
二、字符串常用方法
2.1 str.count(sub[, start[, end]])
返回子字符串 sub 在 [start, end] 范围内非重叠出现的次数。 可选参数 start 与 end 会被解读为切片表示法。
可以用collection.Counter来代替
from collections import Counter str_3 = 'I can because I believe I can' n1 = str_3.count("I") n2 = Counter(str_3.split())["I"] # 可以用Counter来代替 print(n1) print(n2)

2.2 find(sub[, start[, end]])
返回子字符串 sub 在 s[start:end] 切片内被找到的最小索引。 可选参数 start 与 end 会被解读为切片表示法。 如果 sub 未被找到则返回 -1。
2.3 str.index(sub[, start[, end]])
类似于 find,但在找不到子类时会引发 ValueError。
如果想报错,就使用index,不想报错就使用find。
str_1 = 'jiayoau' n3 = str_1.find("o") n4 = str_1.index("o") n5 = str_1.find("Q") # n6 = str_1.index("Q") # 出错 print(n3) print(n4) print(n5)

2.4 str.replace(old, new[, count])
返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。 如果给出了可选参数 count,则只替换前 count 次出现。
2.5 str.rpartition(sep)
在 sep 最后一次出现的位置拆分字符串,返回一个 3 元组,其中包含分隔符之前的部分、分隔符本身,以及分隔符之后的部分。 如果分隔符未找到,则返回的 3 元组中包含两个空字符串以及字符串本身。
如果 sep 没有出现在母串中,返回值是 (sep, '', '') ;
否则,返回值的第一个元素是 sep 左端的部分,第二个元素是 sep 自身,第三个元素是 sep 右端的部分。
str_1 = 'hello world and hello python' print(str_1.rpartition('and'))

2.6 str.splitlines([keepends])
print('ab c de fg kl '.splitlines())

2.7 str.split(sep=None, maxsplit=-1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。
sep默认为所有的空字符,包括空格、换行( )、制表符( )等;maxsplit默认为 -1, 即分隔所有。
str.split() 和 str.split(' ') 的返回值是不相同的。
产生差异的原因在于:当忽略 sep 参数或 sep 参数为 None 时与明确给 sep 赋予字符串值时, split() 采用两种不同的算法。
对于前者, split() 先去除字符串两端的空白符,然后以任意长度的空白符串作为界定符分切字符串(即连续的空白符串被当做单一的空白符看待);
对于后者则认为两个连续的 sep 之间存在一个空字符串。
2.8 str.title()
返回原字符串的标题版本,其中每个单词第一个字母为大写,其余字母为小写。
2.9 str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。
str_1 = 'hello world' str_2 = '你好世界 hello world' print('str_1.title(): ', str_1.title()) # 单词的首字母大写 print('str_1.capitalize():', str_1.capitalize()) # 英文开头,只有首字母大写 print('str_2.title(): ', str_2.title()) print('str_2.capitalize():', str_2.capitalize()) # 非英文开头,不变

2.10 str.upper()
返回原字符串的副本,其中所有区分大小写的字符 均转换为大写。
2.11 str.lower()
返回原字符串的副本,其中所有区分大小写的字符 均转换为小写。
2.12 str.swapcase()
返回原字符串的副本,其中所有区分大小写的字符 均有大写转化为小写,小写转化为大写。
2.13 str.strip([chars])
返回原字符串的副本,移除其中的前导和末尾字符。 chars 参数为指定要移除字符的字符串。
如果省略或为 None,则 chars 参数默认移除空格符。 实际上 chars 参数并非指定单个前缀或后缀;而是会移除参数值的所有组合:
print(' spacious '.strip()) print('www.example.com'.strip('cmowz.'))
最外侧的前导和末尾 chars 参数值将从字符串中移除。 开头端的字符的移除将在遇到一个未包含于 chars 所指定字符集的字符时停止。
2.14 str.center(width[, fillchar])
返回长度为 width 的字符串,原字符串在其正中。 使用指定的 fillchar 填充两边的空位。fillchar只能是单个字符。
2.15 ljust(width[, fillchar])
返回长度为 width 的字符串,原字符串在其中靠左对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
2.16 rjust(width[, fillchar])
返回长度为 width 的字符串,原字符串在其中靠右对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
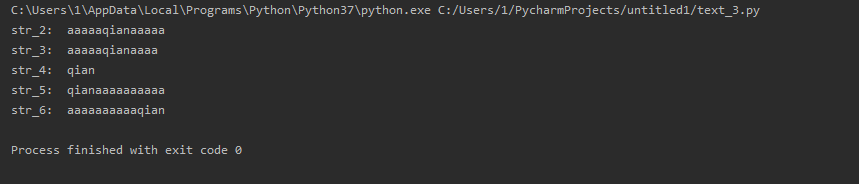
str_1 = 'qian' str_2 = str_1.center(14, 'a') # 在返回长度为14的字符串,原字符串在其正中,左边5个a,右边5个a str_3 = str_1.center(13, 'a') # 在返回长度为13的字符串,原字符串在其正中,左边5个a,右边4个a;优先填充左边 str_4 = str_1.center(3, 'a') # 填充后的长度小于len(str_1),返回原字符串 str_5 = str_1.ljust(14, 'a') # 返回长度为 width 的字符串,原字符串在其中靠左对齐。 str_6 = str_1.rjust(14, 'a') # 返回长度为 width 的字符串,原字符串在其中靠右对齐。 print("str_2: ", str_2) print("str_3: ", str_3) print("str_4: ", str_4) print("str_5: ", str_5) print("str_6: ", str_6)
2.17 str.zfill(width)
返回原字符串的副本,在左边填充 ASCII '0' 数码使其长度变为 width。 正负值前缀 ('+'/'-') 的处理方式是在正负符号 之后 填充而非在之前。 如果 width 小于等于 len(s) 则返回原字符串的副本。
而 zfill() 中的 z 是指 zero, zfill()即是以字符 0 进行填充,在输出数值时比较常用。
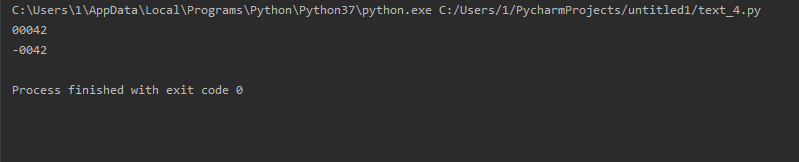
print("42".zfill(5)) print("-42".zfill(5))
2.18 str.expandtabs(tabsize=8)
返回字符串的副本,其中所有的制表符会由一个或多个空格替换,具体取决于当前列位置和给定的制表符宽度。 每 tabsize 个字符设为一个制表位(默认值 8 时设定的制表位在列 0, 8, 16 依次类推)。
要展开字符串,当前列将被设为零并逐一检查字符串中的每个字符。
如果字符为制表符 ( ),则会在结果中插入一个或多个空格符,直到当前列等于下一个制表位。 (制表符本身不会被复制。)
如果字符为换行符 (
) 或回车符 (
),它会被复制并将当前列重设为零。 任何其他字符会被不加修改地复制并将当前列加一,不论该字符在被打印时会如何显示。
str_1 = '01 012 0123 01234 0'.expandtabs() str_2 = '01 012 0123 01234 0'.expandtabs(4) print(str_1) print(str_2)

2.19 其他方法。
| 方法 | 含义 | 参考 |
str.lstrip([chars]) |
返回原字符串的副本,移除其中的前导字符 | str.strip([chars]) |
str.rstrip([chars]) |
返回原字符串的副本,移除其中的末尾字符 | str.strip([chars]) |
str.rfind(sub[, start[, end]]) |
返回子字符串 sub 在字符串内被找到的最大(最右)索引 | str.find(sub[, start[, end]]) |
str.rindex(sub[, start[, end]]) |
类似于 str.rfind,但在子字符串 sub 未找到时会引发 ValueError |
str.index(sub[, start[, end]]) |
|
在 sep 最后一次出现的位置拆分字符串,返回一个 3 元组 | |
|
从最右边开始 | str.split(sep=None, maxsplit=-1) |
|
返回原字符串的副本,移除其中的末尾字符 | |