提升orm操作性能注意的点
优化一:尽量不查对象,能用values就是用values
直接使用对象查询的结果是5条sql语句
def youhua(request): # 使用对象查 obj_list = models.Book.objects.all() for obj in obj_list: print(obj.title,obj.pubs.name) return render(request,"youhua.html")

使用values查询只执行了1条sql,会自动进行连表查询
def youhua(request): # 使用values obj_list = models.Book.objects.values('title', 'pubs__name') for obj in obj_list: print(obj['title'], obj['pubs__name']) return render(request,"youhua.html")
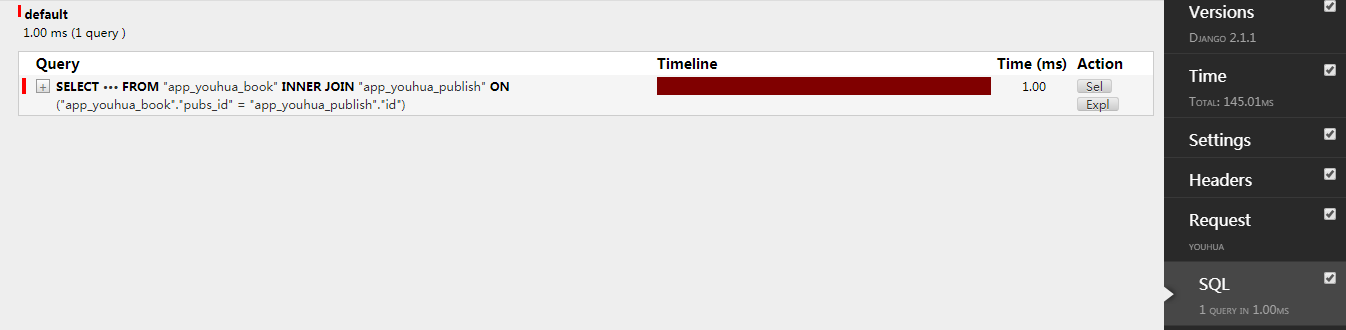
优化二:select_related('classes')
使用select_related('classes')
适用于:多对一 ,一对一查询添加select_related()方法,括号中是外键字段 。会进行连表查询
def youhua(request): # 使用对象查 obj_list = models.Book.objects.all().select_related('pubs') for obj in obj_list: print(obj.title, obj.pubs.name) return render(request,"youhua.html")
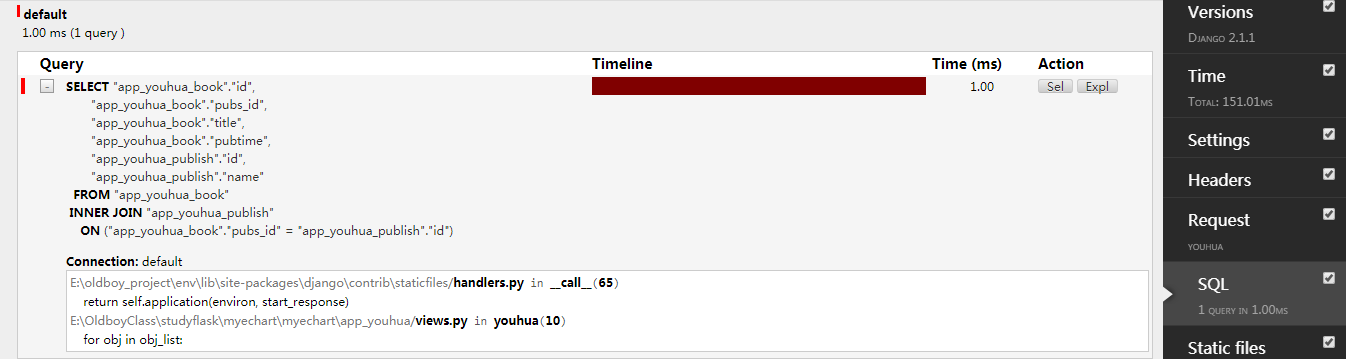
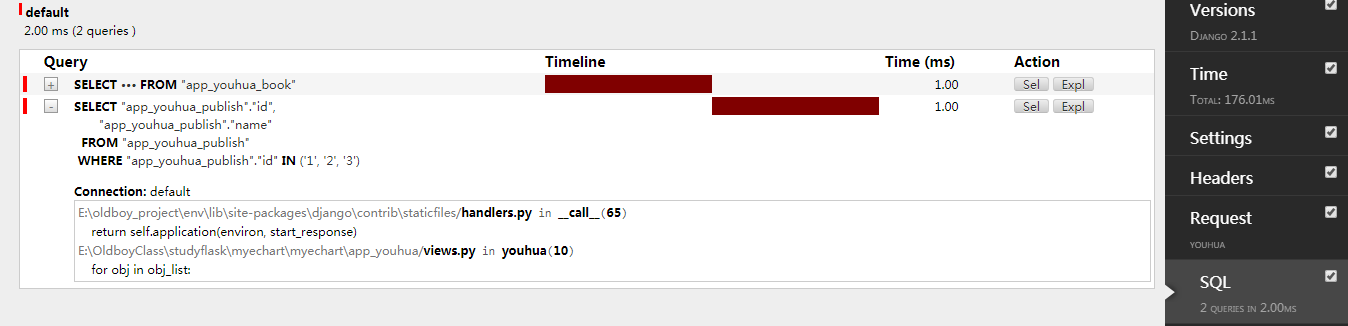
优化三:prefetch_related()
使用prefetch_related(),多对一,
def youhua(request): obj_list = models.Book.objects.all().prefetch_related("pubs") for obj in obj_list: print(obj.title,obj.pubs.name) return render(request,"youhua.html")
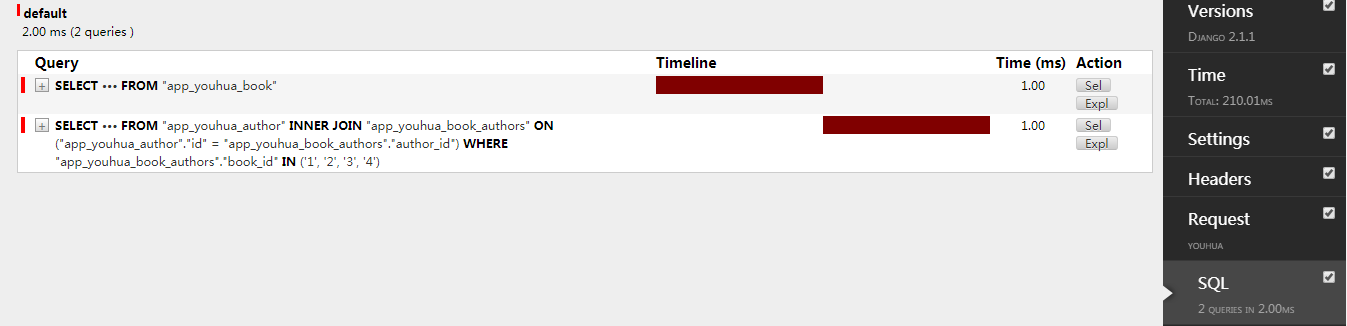
使用prefetch_related(),多对多,
def youhua(request): obj_list = models.Book.objects.all() for obj in obj_list: print(obj.title,obj.authors.all()) return render(request,"youhua.html")

def youhua(request): obj_list = models.Book.objects.all().prefetch_related("authors") for obj in obj_list: print(obj.title,obj.authors.all()) return render(request,"youhua.html")
优化四:only()指定查询字段
直接查询的情况,会将所有字段都查询出来
def youhua(request): obj_list = models.Book.objects.all() for obj in obj_list: print(obj.title) return render(request,"youhua.html")

查询时指定某些字段查询,使用only指定字段只会查我们需要的那个字段。
def youhua(request): obj_list = models.Book.objects.all().only('title') for obj in obj_list: print(obj.title) return render(request,"youhua.html")
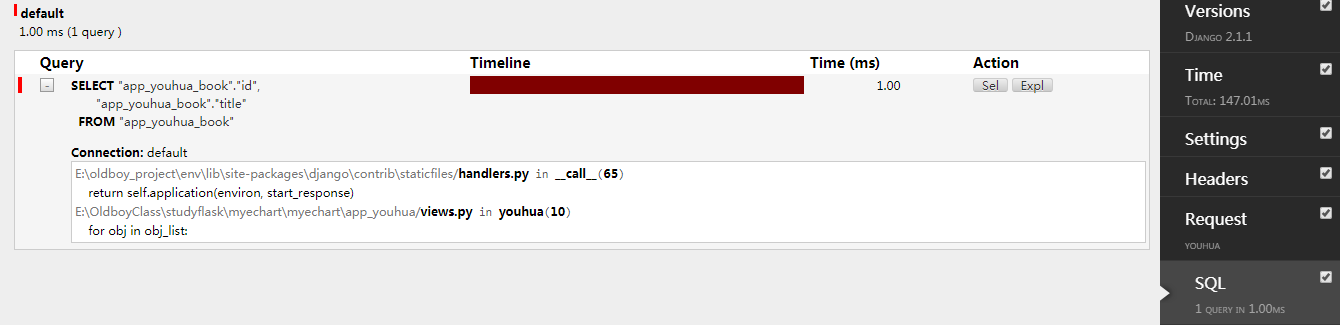
优化五:defer() 查询时指定排除某些字段和only相反
如果我们需要的字段较多,不需要的较少,可以使用defer排除
def youhua(request): obj_list = models.Book.objects.all().defer('title') for obj in obj_list: print(obj.pubtime) return render(request,"youhua.html")
注:如果排除的字段,还要查会增加查询负担,当然查询指定字段之外的字段也会增加查询负担。