pyspark可以直接将DataFrame格式数据转成table,也可在程序中执行sql代码。
1. 首先导入库和环境,os.environ在系统中有多个python版本时需要设置
import os from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession from pyspark.sql import HiveContext os.environ["PYSPARK_PYTHON"]="/usr/bin/python3" conf = SparkConf().setAppName('test_sql') sc = SparkContext('local', 'test', conf=conf) spark = SparkSession(sc) hive_text = HiveContext(spark)
2. 获取DataFrame格式数据
获取DataFrame格式的方式有很多种:读取sql/hive数据、读取csv数据、读取text数据、rdd转DataFrame数据、Pandas数据转DataFrame数据、读取json数据、读取parquet数据等等。
本例采用pandas转DataFrame格式数据,其中生成pandas数据的方式可见:https://www.cnblogs.com/qi-yuan-008/p/12412018.html,例如
import pandas as pd df_1 = pd.DataFrame([['Jack','M',40],['Tony','M',20],['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
然后从pandas建立DataFrame数据(spark.createDataFrame)<注:从DataFrame转成pandas也很方便:df.toPandas()即可>:
df = spark.createDataFrame(df_1) print(df.show())
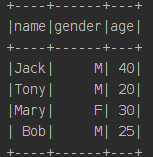
3. 将DataFrame数据转成table:registerDataFrameAsTable
rows_data = hive_text.registerDataFrameAsTable(df, tableName='table_moment') #生成虚拟表,设置表名 data_2 = hive_text.sql("select * from table_moment") #执行sql语句 print(data_2.take(2)) print(data_2.collect()[0])

取表中某一列数据:
print(data_2.select('name').show())
取表中多列数据:
print(data_2.select(['name', 'age']).show())
注意:如果要连hive表的数据,并用sql语句操作hive表,以上方法不行,需要其他设置。
4. 代码中操作hive表的sql语句,需要修改以上spark的配置(配置enableHiveSupport().getOrCreate()),不再需要配置sc和conf,直接配置spark,改成:
spark = SparkSession.builder.master("local").appName("SparkOnHive").enableHiveSupport().getOrCreate() hive_text = HiveContext(spark)
其中 'local' 可以修改成其他 “主机+端口号” 形式,然后可以访问hive表:
hive_text.sql('use database_name') data_3 = hive_text.sql("select * from table_name") print(data_3.first())
而此时,就可以将上述的第3步的表:table_moment 直接写入hive形成新的表
hive_text.sql('create table default.test_pandas select * from table_moment')
default是已有的数据库名,test_pandas是新建表名
参考:
https://www.jianshu.com/p/d1f6678db183
https://blog.csdn.net/u011412768/article/details/93426353
##