1. 计算机视觉的任务
(1)图像分类(Image Classification),指的是图像中是否存在某种物体,对图像进行特征描述。通过是CNN网络,结构基本是由卷积层、池化层以及全连接层组成,算法包括AlexNet(2012)、ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)。
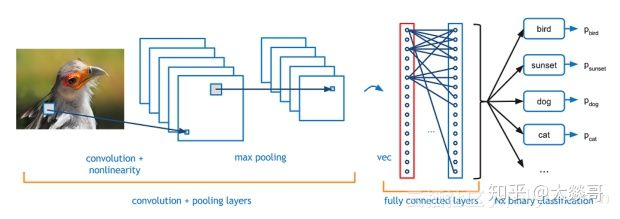
(2)图像定位(Image Location),指的是在图像分类的基础上,得到图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。网络带有两个输出分支,一个分支用于做图像分类,另一个分支用于判断目标位置。
(3)目标检测(Object Dection),指的是在图像定位基础之上,输入图片/视频,经过处理,得到多个目标的位置信息(左上角和右下角的坐标)、目标的预测类别、目标的预测置信度(confidence)。算法包括R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、 RetinaNet。

(4)目标跟踪(Object Track),指的是在给定场景中跟踪感兴趣的一个或多个具体对象的过程。算法包括FCNT、MD Net。
(5)语义分割(Semantic Segmentation),指的是在目标检测基础之上,将整个图像分成像素组,然后对其进行标记和分类,在语义上理解每个像素的角色(例如,汽车、摩托车等),不能分割同一类型的对象。算法包括FCN。

(6)实例分割(Instance segmentation),指的是在语义分割基础之上,对图像中的每个实例进行像素级分割,确定它们之间的界限、差异和关系。算法包括Mask RCNN。

(7)其他任务:图像标注 (Image Captioning)、图像生成(Image Generator)、超分辨率、风格迁移、着色、显著性检测、行为识别、人体姿势估计、场景理解、图像恢复、图像合成、图像重建、自然场景文本检测与识别、3D视觉。
(8)mAP(mean Average Precision),指的是算法检测图像的准确率,越高越好。
reference:https://zhuanlan.zhihu.com/p/76681592
2. darknet19 图像分类

git clone https://github.com/pjreddie/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/darknet19.weights
./darknet classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights data/dog.jpg
Log:
layer filters size input output
0 conv 32 3 x 3 / 1 256 x 256 x 3 -> 256 x 256 x 32 0.113 BFLOPs
1 max 2 x 2 / 2 256 x 256 x 32 -> 128 x 128 x 32
24 avg 8 x 8 x1000 -> 1000
25 softmax 1000
Loading weights from darknet19.weights...Done!
data/dog.jpg: Predicted in 0.769246 seconds.
42.55%: malamute # 爱斯基摩狗
22.93%: Eskimo dog # 北极犬
12.51%: Siberian husky # 西伯利亚哈士奇
2.76%: bicycle-built-for-two
1.20%: mountain bike
reference:https://pjreddie.com/darknet/imagenet/
3. Yolo v3 目标检测
实时目标检测,平衡速度和准确率,达到即快又准确的效果。
github: https://github.com/pjreddie/darknet
homepage: https://pjreddie.com/darknet/yolo/
reference: https://zhuanlan.zhihu.com/p/57613816
安装
installing website: https://pjreddie.com/darknet/install/
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
Log:
layer filters size input output
0 conv 16 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 16 0.150 BFLOPs
1 max 2 x 2 / 2 416 x 416 x 16 -> 208 x 208 x 16
23 yolo
Loading weights from yolov3-tiny.weights...Done!
data/dog.jpg: Predicted in 1.183869 seconds.
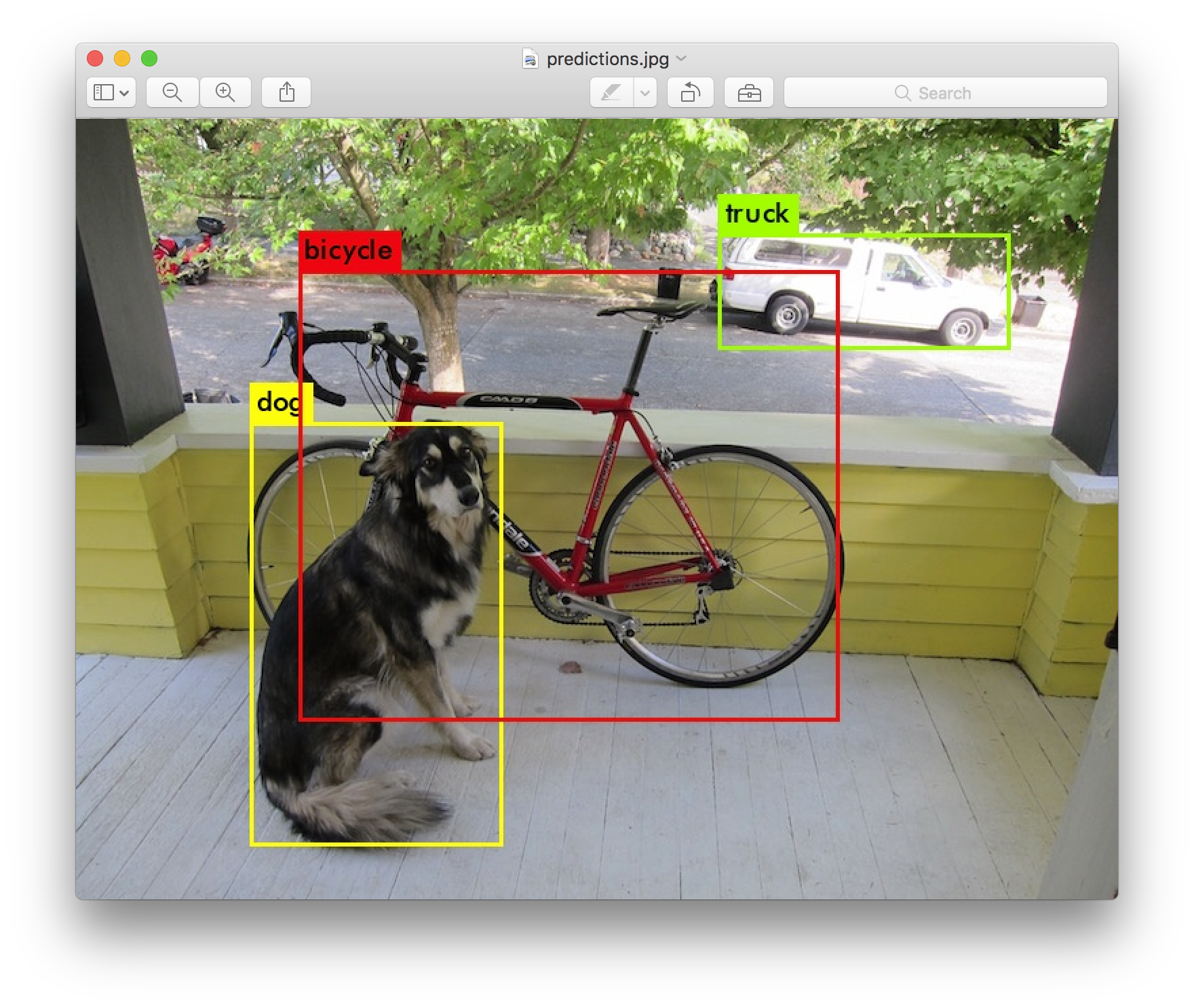
dog: 57%
car: 52%
truck: 56%
car: 62%
bicycle: 59%