这篇文章主要和大家讨论几乎所有人都熟悉,但不少人又陌生的一条select语句。不知道大家有没有想过到底是什么东西让SQLServer能理解我们写的select。这中间到底发生了什么,是不是有过冲动想去了解。至少我曾经冲动想去了解,但当时主要在研究CLR以及webform相关知识。后来主要精力放在研究SQLserver内部机制,今天就给大家介绍下这条语句。
一、范例数据库脚本
create database Test
alter database Test set recovery simple
go
use Test
go
create table Test
ID int identity(1,1) primary key,
[Name] varchar(64) not null default '',
CreatedTime datetime not null default getdate()
)
insert into Test([name]) values('xiaojun')
这个脚本就不介绍了,很简单。
二、语句分析
select * from Test
简单吧,本来嘛标题就是之简单语句。下面开始分析这条语句吧,假设读者已经知道了SQLServer整体架构或者已经阅读过这个系列第一篇文章。当这条语句被可靠的传递到关系引擎中的命令分析器,接下来就发生了:
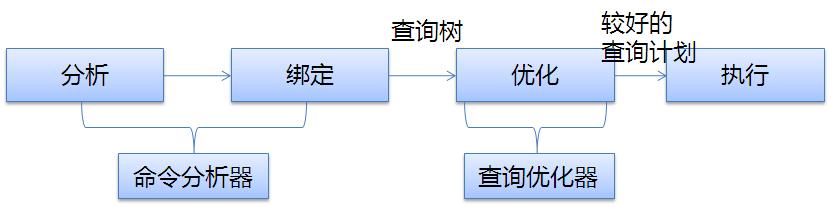
分析:从语法库中检查T-SQL进行基本的语法检查。如果语法出错了,那整个语句就立即停止,提示用户语法出错,哪出错。比如错误使用的关键字、列、表名等。如果语法没有出错,就会生成一个分析树传递给下一个步骤。
绑定:1、名字解析:检查所有的对象在用户的安全上下文中存在并可见。这个步骤很好理解主要是数据库每个对象都有权限。如果登录的账号没有相应权限,就结束这个步骤。
2、类型推导:确定解析树中每个节点的最终类型。这个步骤主要是补充分析分析步骤中的分析树,确定其最终的类型。不知道大家可想过为什么要到这一步才确定。为什么不在分析中确定呢?主要原因是效率,类型推导会消耗资源,没有必要在没有确定用户对每个对象有权限的情况下确定。那为什么不直接先确定用户对每个对象有权限再做分析呢。那是因为没做分析的时候,系统无法知道具体有哪些对象。我又要说了,SQLServer的设计真的可以说是很精致的,连这样的细节和资源消耗都考虑了。值得我们学习哦。
3、聚合绑定:确定哪些地方可以进行聚合。这个步骤主要和SQL中是否有聚合操作有关系。
4、组合绑定:将聚合绑定到正确的选择列表中。这个步骤是把聚合操作与需要聚合的列绑定对应起来。
这两步操作主要是由命令分析器完成,它最终得到分析树,传递给SQLServer引擎中最复杂最优技术含量的组件,没有之一,查询优化器。查询优化器功能概况起来很简单,就是优化SQL。具体优化模型如下:
优化:1、检查执行计划缓存中是有没对应的执行计划。 如果没有,继续下面操作。如果有则使用缓存。SQLServer是根据SQL的哈希值比较的。想想为什么?
2、预优化:查询语句很简单,开销足够小,直接结束优化。比如没有联接的基本查询。属于零开销,称为普通计划。比如我们这的select语句预优化就搞定了。
3、阶段0:检验基本规则,以及散列和嵌套联接选项。这个计划的开销是否小于0.2,如果是,结束优化。这里的0.2以及下面的1.0,这是SQLServer内部的开销值,仅供SQLServer系统内部使用。
4、阶段1:检验更多的规则,以及变换联接的顺序。如果开销最小的计划的开销小于1.0,如果是,结束优化。如果不是,继续判断。如果maxdop>0且这个系统是SMP系统,以及最小开销大于并行化的开销临界值,则使用并行计划。比较并行计划的开销和最好的串行计划的开销,将开销更小的计划传递给阶段2。
并行计划是指优化器根据情况,将恰当的操作符拆分为数个可以同步运行的进程在不同的处理器上运行,需要多核支持。对于大数据量查询可以提高效率。
maxdop是什么呢?这是SQLServer的一个高级配置。我们可以通过sp_configure查看。如下图:
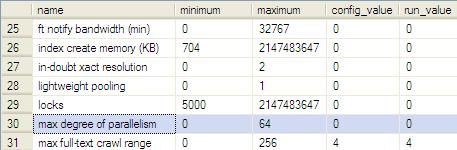
可能你直接运行sp_configure,看不到这个配置。主要是这是个高级配置项,默认不开启。你运行以下语句后再运行sp_configure就能看到以上图中信息。
sp_configure 'show advanced options',1
这里面的高级配置值,默认情况下不需要修改。必须你对SQLServer有较深理解,以及在修改前做好修改对整个SQLServer的影响的评估后才去改动。说说这个maxdop吧,这是说SQLServer在执行并行计划的最大处理器数目,0代表由SQLServer决定。否则就是按照用户指定的最大并行度。因此上面的maxdop>0且这个系统是SMP系统的意思就是当用户修改了这个配置项,那么执行器在评估开销时要优先考虑用户修改过的最大并行度小的系统开销。SMP系统是对称处理器体系结构,基于Intel处理器的服务器基本上都是SMP系统。在此不展开说。
不知道大家注意到没,我上面的图查询优化器输出的是较好的执行计划。想想为什么? 如果想查看优化过程的内部情况,可以使用一下sys.dm_exec_query_optimizer_info动态管理视图。比如,下面演示证明我们这条select语句是属于普通计划。按照如下操作执行:
dbcc freeproccache --清空执行计划缓存
select * from sys.dm_exec_query_optimizer_info where counter in('optimizations','trivial plan','search 0','search 1','search 2')
结果如下:

继续:
select * from Test
select * from sys.dm_exec_query_optimizer_info where counter in('optimizations','trivial plan','search 0','search 1','search 2')
结果如下:

发现了吧,trival plan类型计数+1,说明优化器对select * from Test进行优化时是普通计划。
5、阶段2:检验所有可能的计划,并且选择达到检验的时间限制时开销最小的计划。
执行:这个计划被调度执行,这个涉及到SQLOS不在本篇文章讨论范围,只要先简单理解为交给CPU执行。
三、结尾
其中这个语句还有很多地方可以分析,比较在这条语句执行时,加锁以及如何被调度执行。这些还是希望在放在后面的章节中解释。这篇文章主要是谈到了SQLServer如何对SQL进行解析优化的。仔细研究,你会发现SQLServer的查询优化器做了很多优化措施当然其他数据库也类似的组件。其实你会发现这些对于我们大部分开发人员都是屏蔽的。屏蔽是一种进步,java、.net的垃圾回收屏蔽了开发人员对内存的管理,那SQLServer在这里屏蔽了什么呢,这需要研究数据库历史。只有研究历史,才能站在一个较高的角度知道现在的数据库为什么是现在的样子。