三、Storm的并行度以及流分组
因为我们在这里,是讲给java工程师的storm教程
所以我期望的场景是,你们所在的公司,基本上来说,已经有大数据团队,有人在维护storm集群
我觉得,对于java工程师来说,先不说精通storm
至少说,对storm的核心的基本原理,门儿清,你都很清楚,集群架构、核心概念、并行度和流分组
接下来,掌握最常见的storm开发范式,spout消费kafka,后面跟一堆bolt,bolt之间设定好流分组的策略
在bolt中填充各种代码逻辑
了解如何将storm拓扑打包后提交到storm集群上去运行
掌握如何能够通过storm ui去查看你的实时计算拓扑的运行现状
你在一个公司里,如果说,需要在你的java系统架构中,用到一些类似storm的大数据技术,如果已经有人维护了storm的集群
那么此时你就可以直接用,直接掌握如何开发和部署即可
但是,当然了,如果说,恰巧没人负责维护storm集群,也没什么大数据的团队,那么你可能需要说再去深入学习一下storm
当然了,如果你的场景不是特别复杂,整个数据量也不是特别大,其实自己主要研究一下,怎么部署storm集群
你自己部署一个storm集群,也ok
好多年前,我第一次接触storm的时候,真的,我觉得都没几个人能彻底讲清楚,用一句话讲清楚什么是并行度,什么是流分组
很多时候,你以外你明白了,其实你不明白
比如我经常面试一些做过storm的人过来,我就问一个问题,就知道它的水深水浅,流分组的时候,数据在storm集群中的流向,你画一下
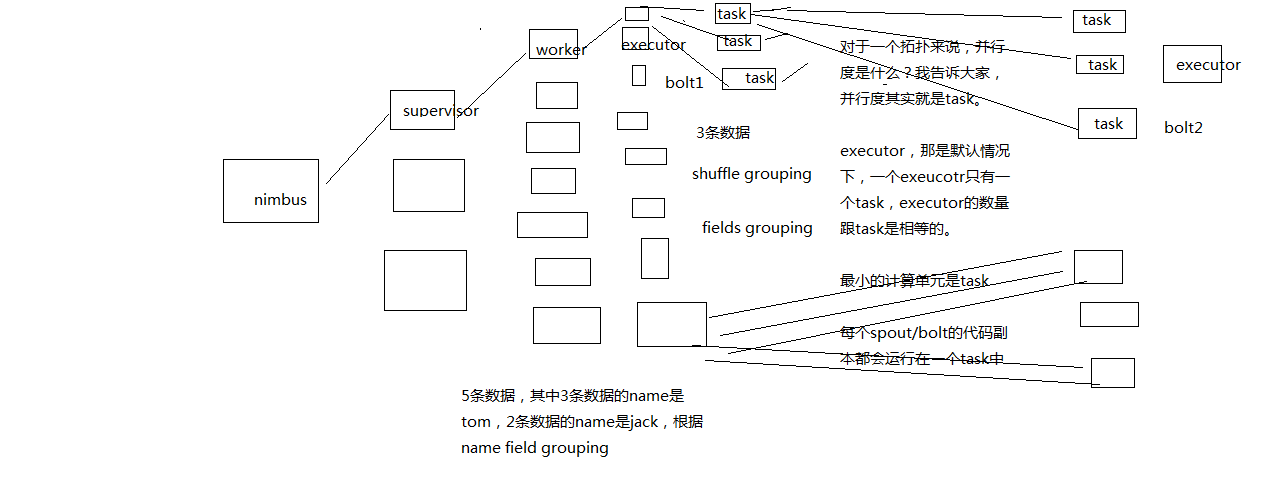
比如你自己随便设想一个拓扑结果出来,几个spout,几个bolt,各种流分组情况下,数据是怎么流向的,要求具体画出集群架构中的流向
worker,executor,task,supervisor,流的
几乎没几个人能画对,为什么呢,很多人就没搞明白这个并行度和流分组到底是什么
并行度:Worker->Executor->Task,没错,是Task
流分组:Task与Task之间的数据流向关系
Shuffle Grouping:随机发射,负载均衡
Fields Grouping:根据某一个,或者某些个,fields,进行分组,那一个或者多个fields如果值完全相同的话,那么这些tuple,就会发送给下游bolt的其中固定的一个task
你发射的每条数据是一个tuple,每个tuple中有多个field作为字段
比如tuple,3个字段,name,age,salary
{"name": "tom", "age": 25, "salary": 10000} -> tuple -> 3个field,name,age,salary
All Grouping
Global Grouping
None Grouping
Direct Grouping
Local or Shuffle Grouping