1. 什么是浏览器伪装技术
有些网站可以识别出访问者是通过浏览器还是爬虫等自动访问程序访问网站,如果识别出使用的不是浏览器,则会禁止访问或者禁止该用户在网站上的其他行为,比如不允许登录等。如果此时我们想对该网站进行爬取,则需要使用浏览器伪装技术。前面我们已经接触了一些简单的浏览器防伪装技术,如设置 Header 信息中的 User-Agent 字段,伪装成浏览器来访问。
有一些网站为了避免爬虫的恶意访问,会设置一些反爬虫机制,常见的反爬虫机制主要有:
(1) 通过分析用户请求的 Header 信息进行反爬虫,常见的有 User-Agent 、Referer 字段
(2) 通过检测用户行为进行反爬虫,比如判断同一个IP在短时间内是否频繁访问,我们可以通过设置代理解决
(3) 通过动态页面增加爬虫爬取的难度,达到反爬虫的目的,我们可以利用 Selenium 、phantomJS 等工具解决
2. 浏览器伪装技术预备知识
在使用浏览器伪装技术之前,我们需要先了解 Header(头部信息)的基本原理与结构:当我们通过浏览器访问某个网址的时候,会向服务器发送一些 Headers 头信息,当服务器接收到这些头信息之后,可以知道当前浏览器的状态,同样服务器也可以根据当前浏览器的状态分析对应请求的用户是爬虫的可能性有多大,从而决定是否做出响应以及做出什么样的响应。
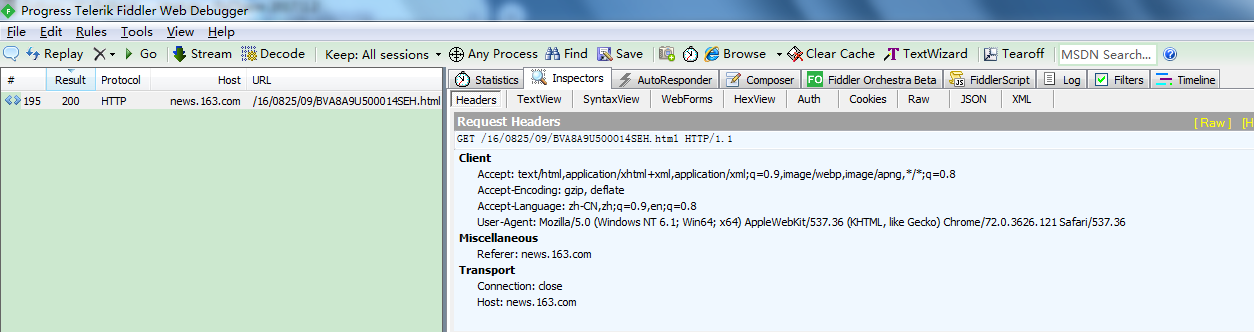
这里我们打开 Fiddler ,来分析 Header 中都有哪些字段:
Accept:表示浏览器能够支持的内容类型有哪些,如下图,表示支持 HTML文档 、XHTML文档 、XML文档 、Image图片
Accept-Encoding:表示浏览器支持的压缩编码有哪些,如下图,表示支持 gzip 和 deflate 两种压缩编码
Accept-Language:表示浏览器支持的语言类型,zh-CN 表示简体中文(其中zh表示中文,CN表示简体)、en-US 表示美国英语 、en 表示通用英语
User-Agent:表示用户代理,服务器可以通过该字段识别出客户端的浏览器类型、浏览器版本号、客户端的操作系统及版本号,网页排版引擎等客户端信息
Connection:表示客户端与服务端的连接类型,通常有 keep-alive 和 close 两种连接类型,keep-alive 表示持久性连接,close 表示单方面关闭连接,让连接断开
Host:表示请求的服务器网址是什么,这里我们请求的是 www.youku.com
Referer:表示是从哪个链接跳转过来的,比如我们通过优酷首页访问其他的优酷子页面,那么我们就是从优酷首页跳转到其他优酷子页面的
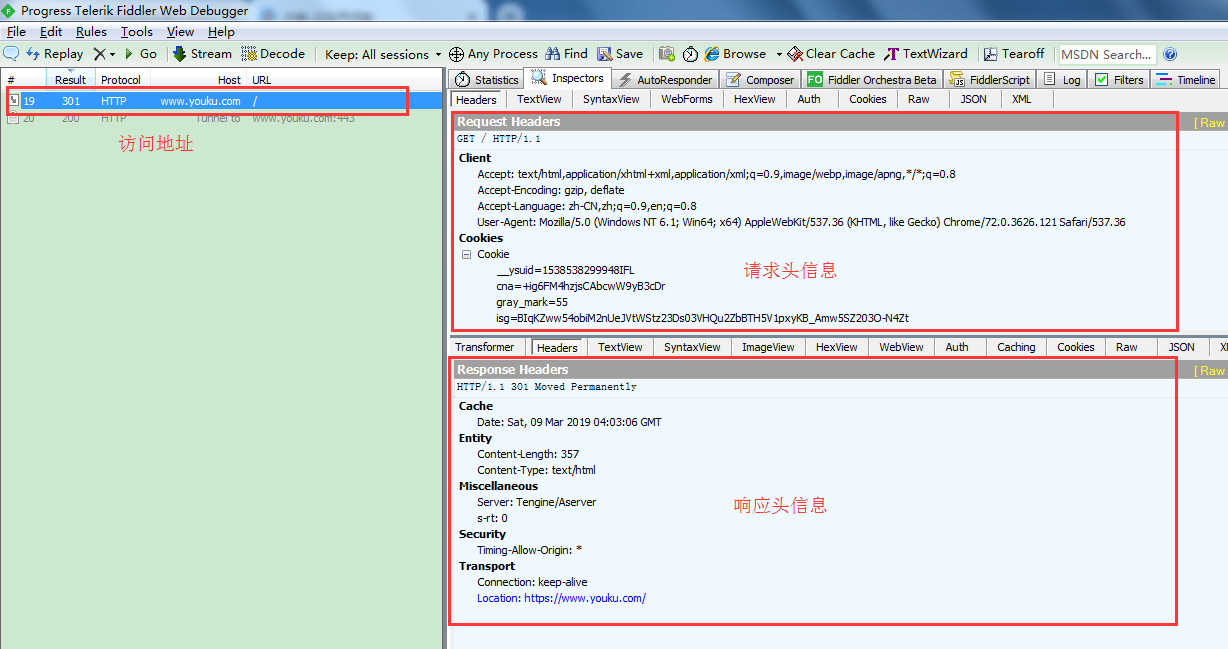
3. 浏览器伪装技术实战
上面我们学习了 Header 请求头中都有哪些字段,接下来我们用 Python 来伪装这些字段,高相似度地模拟成浏览器:
import urllib.request import http.cookiejar url = "http://news.163.com/16/0825/09/BVA8A9U500014SEH.html" # 网易新闻页 headers = { "Host": "www.youku.com", # 模拟请求的服务器网址 "Connection": "keep-alive", # 模拟客户端与服务端的连接类型 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36", # 模拟用户代理 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", # 模拟浏览器支持的内容类型 "Accept-Encoding": "gzip, deflate", # 模拟浏览器支持的压缩编码 "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", # 模拟浏览器支持的语言类型 "referer": "news.163.com", # 模拟Referer,表示从网易新闻首页跳转过去 } headall = [] for k,y in headers.items(): item = (k, y) headall.append(item) cookie = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) opener.addheaders = headall urllib.request.install_opener(opener) data = urllib.request.urlopen(url).read() print(data)import urllib.request import http.cookiejar url = "http://news.163.com/16/0825/09/BVA8A9U500014SEH.html" # 网易新闻页 headers = { "Connection": "close", # 模拟客户端与服务端的连接类型 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36", # 模拟用户代理 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", # 模拟浏览器支持的内容类型 "Accept-Encoding": "gzip, deflate", # 模拟浏览器支持的压缩编码 "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", # 模拟浏览器支持的语言类型 "referer": "news.163.com", # 模拟Referer,表示从网易新闻首页跳转过去 } headall = [] for k,y in headers.items(): item = (k, y) headall.append(item) cookie = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) opener.addheaders = headall urllib.request.install_opener(opener) data = urllib.request.urlopen(url).read() print(data)
执行 Python 脚本之后,抓包内容如下: