优化背景
- 当前生产环境机器配置为4核8G,默认JDK版本1.6,堆内存2G-2.7G,未充分利用硬件资源
- 由于JDK版本为比较老的1.6,使用一些第三方依赖时会遇到新版本不支持的问题
- 当前使用默认的Parallel Scavenge(吞吐量优先)收集器,运行一段时间后Full GC为几百毫秒级别,同时在压测时FGC较频繁,怀疑其影响了TP999指标
- 根据官方兼容性说明JDK1.7和JDK1.8在二进制兼容方面满足我们需求,即当前应用不需要修改任何代码和编译环境就可以直接在新版虚拟机环境运行,tomcat6版本暂不升级
- JDK升级会带来一些隐形性能提升的福利,同时为未来代码层面使用新语言特性做准备
优化过程 - 兼容性测试
最早计划先升级到1.7版本,依次在测试环境和预发布环境中将JDK升级为1.7版本,并回归测试核心流程,然后保持较长的运行时间,经验证未发现任何兼容问题。后面针对JDK的1.8版本也按此流程进行了验证并顺利通过。
优化过程 - 不同配置对比 - 虚拟机监控
适合运行在服务器端的收集器主要为Parallel Scavenge(吞吐量优先)、ParNew + CMS(低停顿响应优先)和G1。其中G1被描述为用于取代CMS收集器的新一代收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求。本次优化重点考虑验证G1收集器,在生产服务器上选取了六台机器使用了如下配置进行小范围测试验证。
| 序号 | 机器IP | JDK版本 | 堆内存配置 | 收集器 | 额外参数 |
|---|---|---|---|---|---|
| 1 | xx.xx.xx.246 | JDK1.6 | 2G-2.7G | Parallel Scavenge | |
| 2 | xx.xx.xx.247 | JDK1.6 | 4G | Parallel Scavenge | |
| 3 | xx.xx.xx.242 | JDK1.7 | 4G | G1 | MaxGCPauseMillis=20 |
| 4 | xx.xx.xx.245 | JDK1.7 | 4G | G1 | |
| 5 | xx.xx.xx.234 | JDK1.8 | 4G | G1 | |
| 6 | xx.xx.xx.244 | JDK1.8 | 4G | Parallel Scavenge |
经过一天运行后,在压测的过程中截取虚拟机监控信息如下:
| 序号 | 特征 | YGC次数 | YGC平均耗时 | FGC次数 | FGC平均耗时 | 总GC耗时 | 吞吐量 | 压测时CPU |
|---|---|---|---|---|---|---|---|---|
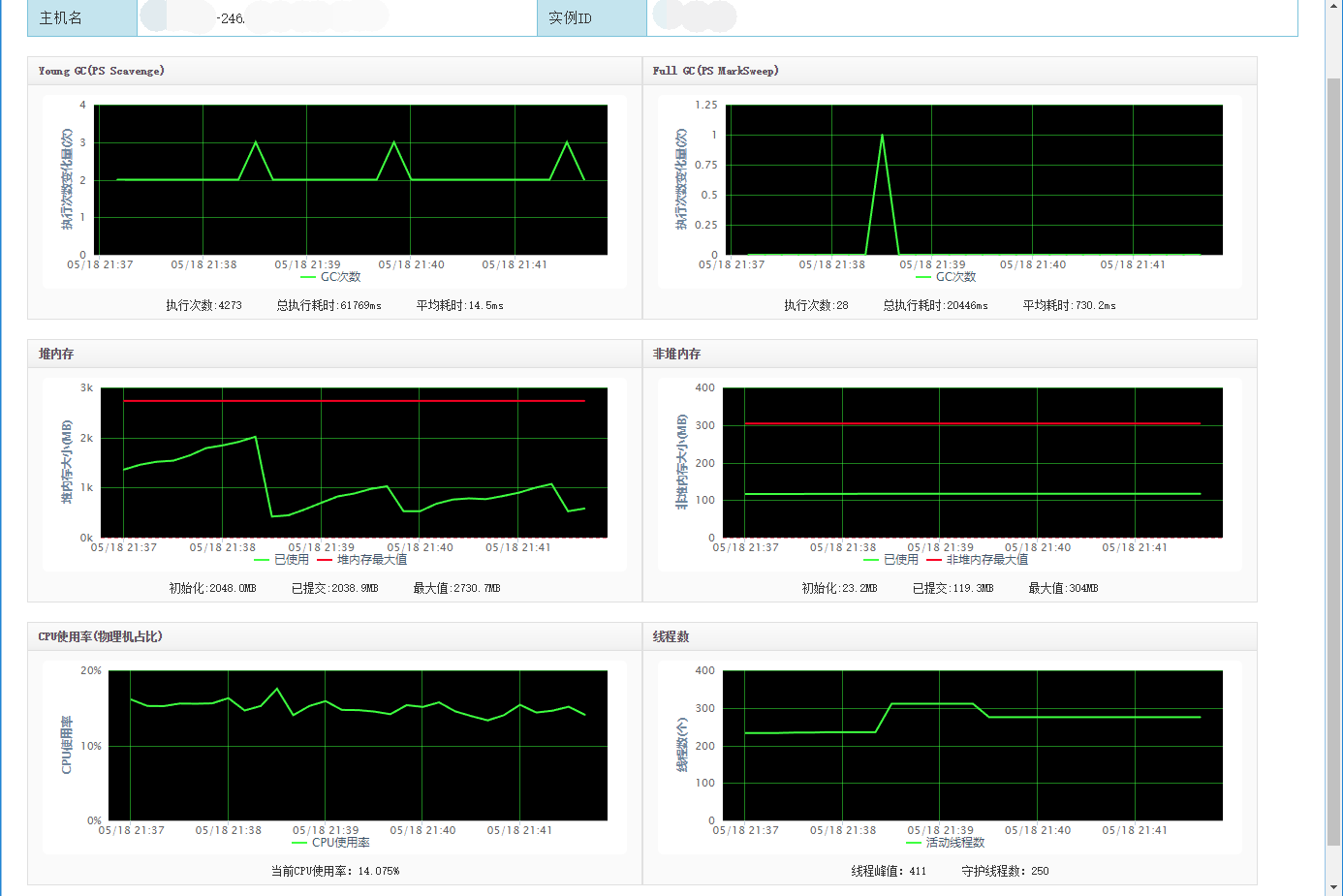
| 1 | JDK6、2G、PS | 4,273 | 15 | 28 | 730 | 82,215 | 99.90% | 15% |
| 2 | JDK6、4G、PS | 2,158 | 23 | 25 | 726 | 67,108 | 99.92% | 13% |
| 3 | JDK7、4G、G1+20 | 11,583 | 23 | 0 | 0 | 265,485 | 99.69% | 20% |
| 4 | JDK7、4G、G1 | 900 | 64 | 0 | 0 | 57,775 | 99.93% | 18% |
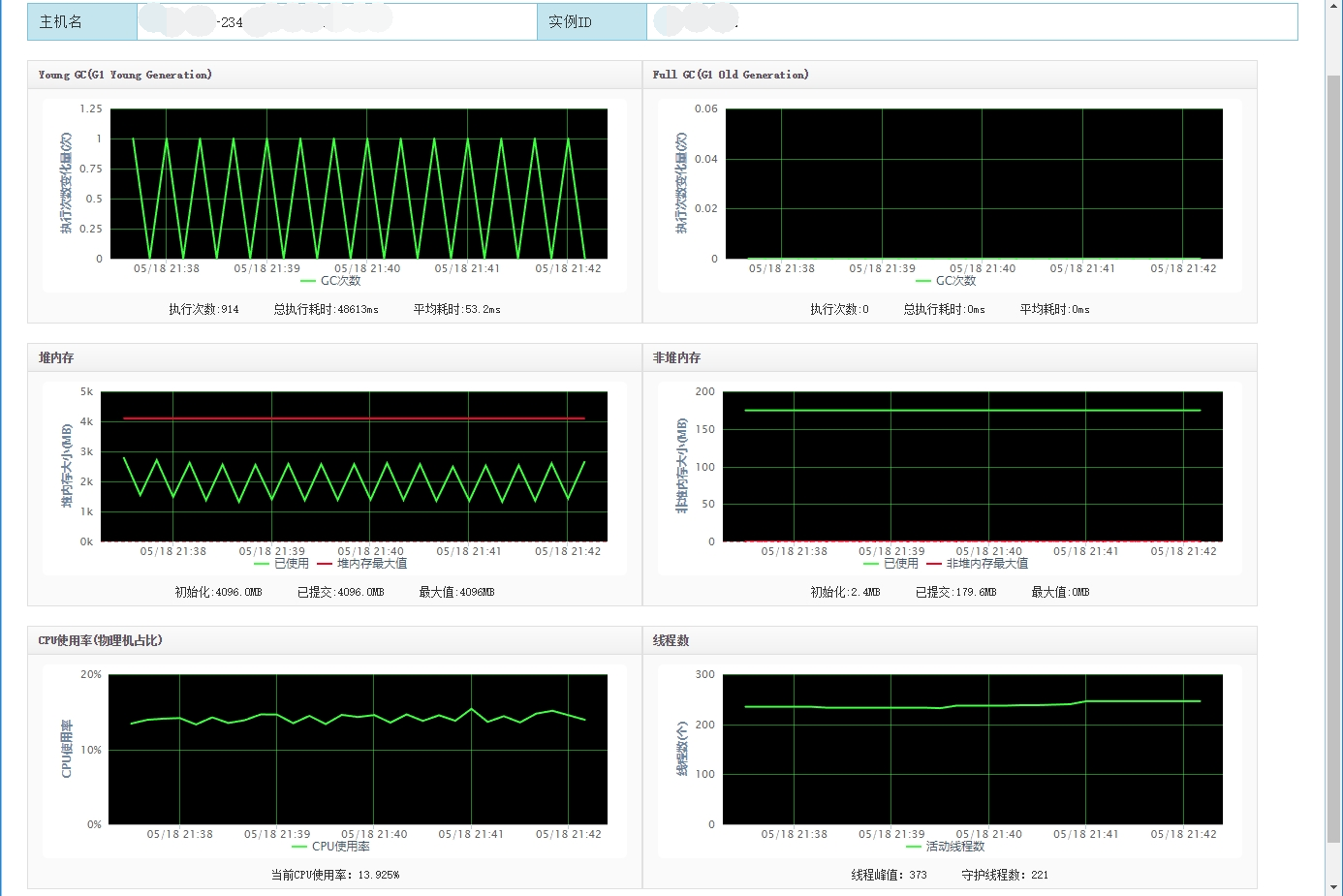
| 5 | JDK8、4G、G1 | 914 | 53 | 0 | 0 | 48,613 | 99.94% | 14% |
| 6 | JDK8、4G、PS | 1,932 | 66 | 28 | 515 | 141,375 | 99.83% | 14% |
其中耗时均为毫秒单位,应用启动总运行时间大约为24小时,根据公式:吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间),由此计算出吞吐量信息。在线上正常运行一天后还进行了查询接口压力测试,总机器数量为92台,压测时总TPS为3W左右,依次压测两个不同接口共持续20分钟,以上信息均为压测进行时截取虚拟机状态信息。
根据不同配置对比结果,我们可以得到以下信息:
- G1收集器没有进行Full GC,根据资料G1通过Young GC和Mixed GC回收年轻代和老年代中的内存,只有当内存分配过快Mixed GC回收无法跟得上分配速度时才会触发一次Full GC,实际上后续经过长期运行我们也没有监测到一次Full GC。
- G1收集器通过MaxGCPauseMillis参数减少停顿时间的代价是吞吐量下降和更多资源使用,由于目标停顿20ms设置过低导致该配置表现最差。
- G1收集器在JDK1.7时较为不成熟,停顿时间和吞吐量提高优势也不明显,CPU使用率较高。
- G1收集器在JDK1.8中停顿时间减少和吞吐量提高都有显著提高,CPU使用率也降低了,实际上在JDK1.9中它已被指定为默认的垃圾收集器。
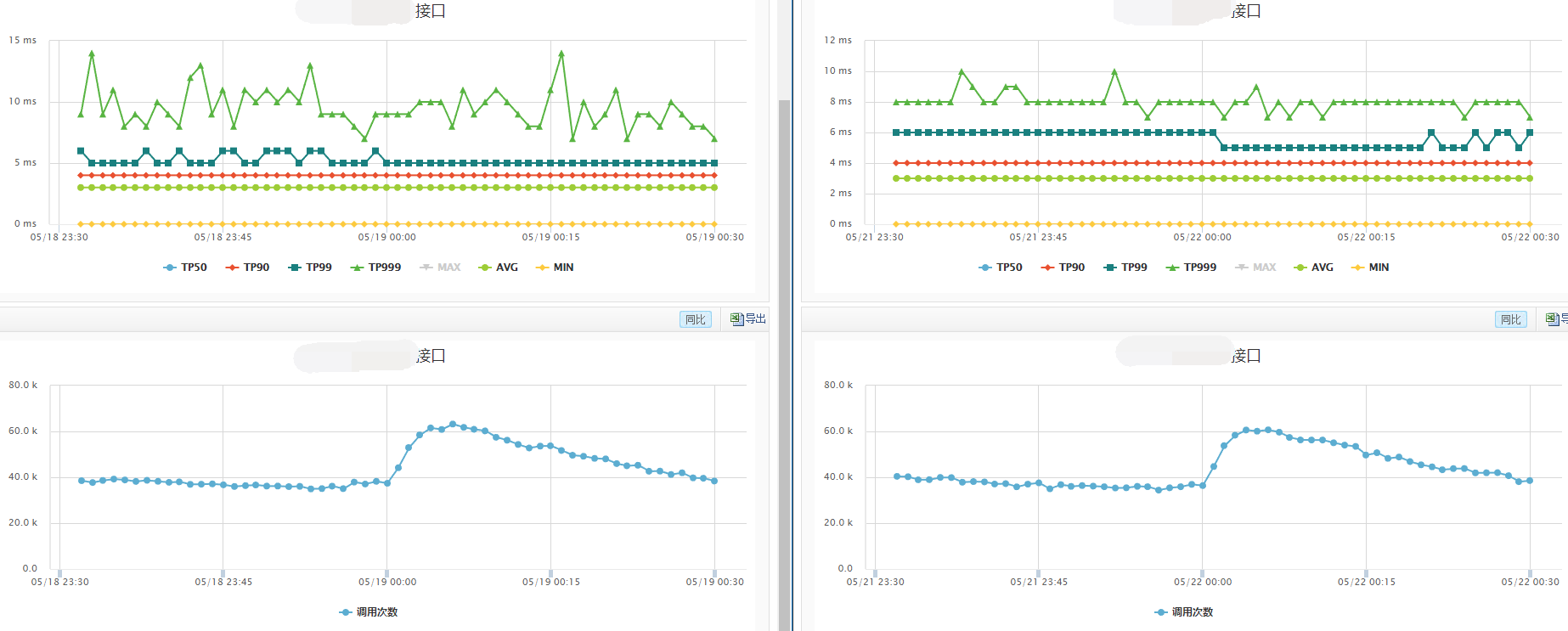
下面列出表现最佳的JDK1.8 G1和原始JDK1.6的监控图对比:
优化过程 - 不同配置对比 - 接口性能监控
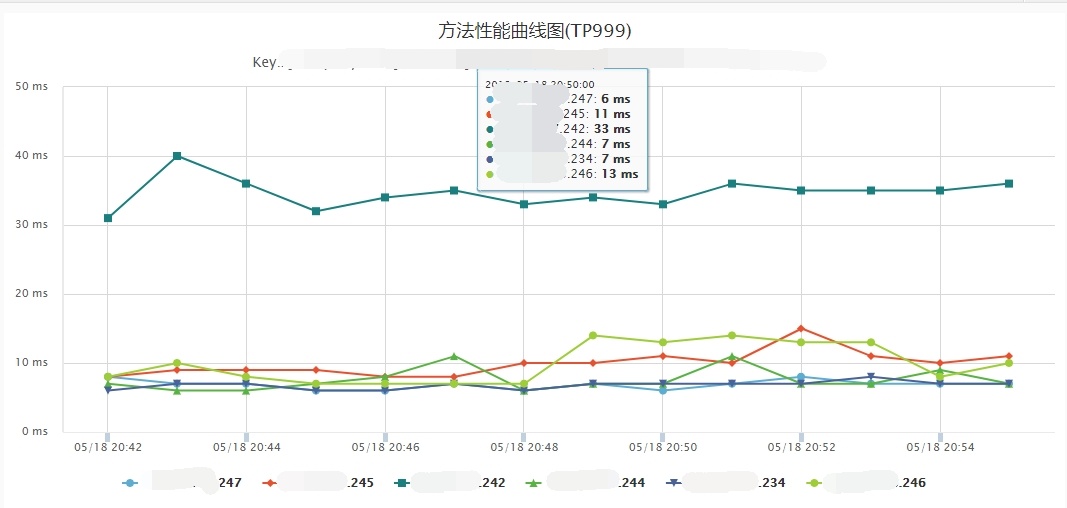
虚拟机不同运行状态还会影响接口性能,在相同压测TPS下,监控显示这几台机器接口性能在TP90和更低指标时都保持一致,但是TP99尤其是TP999有了较明显的性能差异。其中表现最差的是JDK1.7+G1+20ms停顿目标的实例,表现最好的是JDK1.8+G1,同时使用了原Parallel Scavenge收集器的实例TP999波动较大。
下面分别是两个接口不同配置实例的性能监控:

优化过程 - 生产部署和验证
以上对比和测试并不能充分得出什么配置是最优的结论,不管是测试类别还是测试样例都很少,不同配置仅一个实例,同时测试过程简单,缺少多次测试和统计性分析。但是这次简单对比还是得到了可选目标,并且验证其生产环境可用性。为了满足进度需要,直接将生产环境整体升级为JDK1.8、G1收集器、5.5G堆内存的配置(逐步上线切换),之后再次进行整体压测,并和升级前的压测进行性能对比。压测结果说明接口TP999性能指标数值下降明显,性能提高幅度约为36%,以下分别是升级前后两次压测性能对比信息:
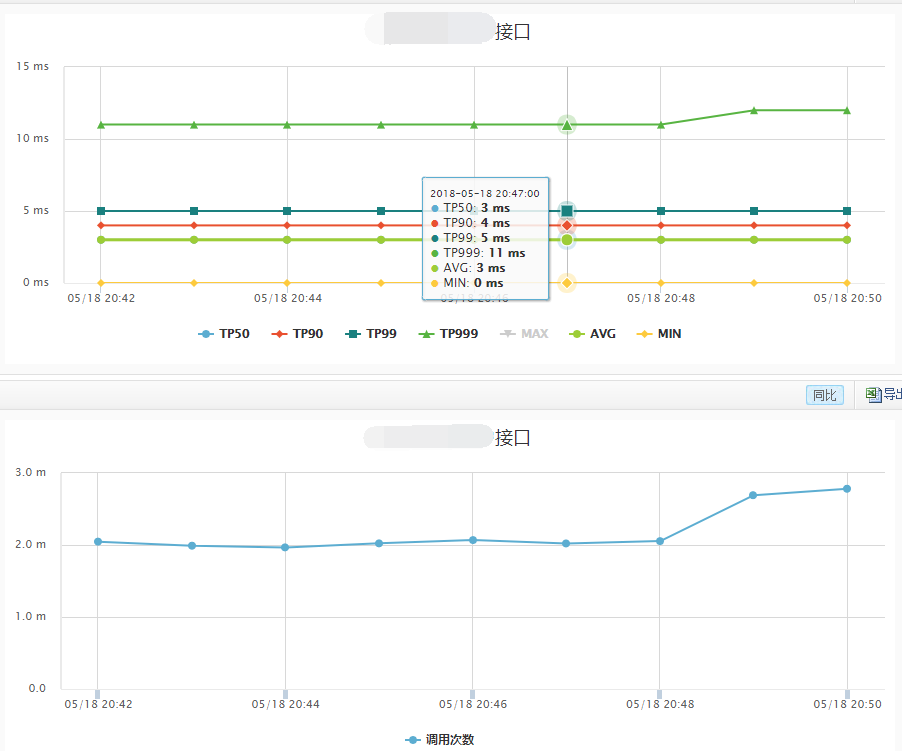
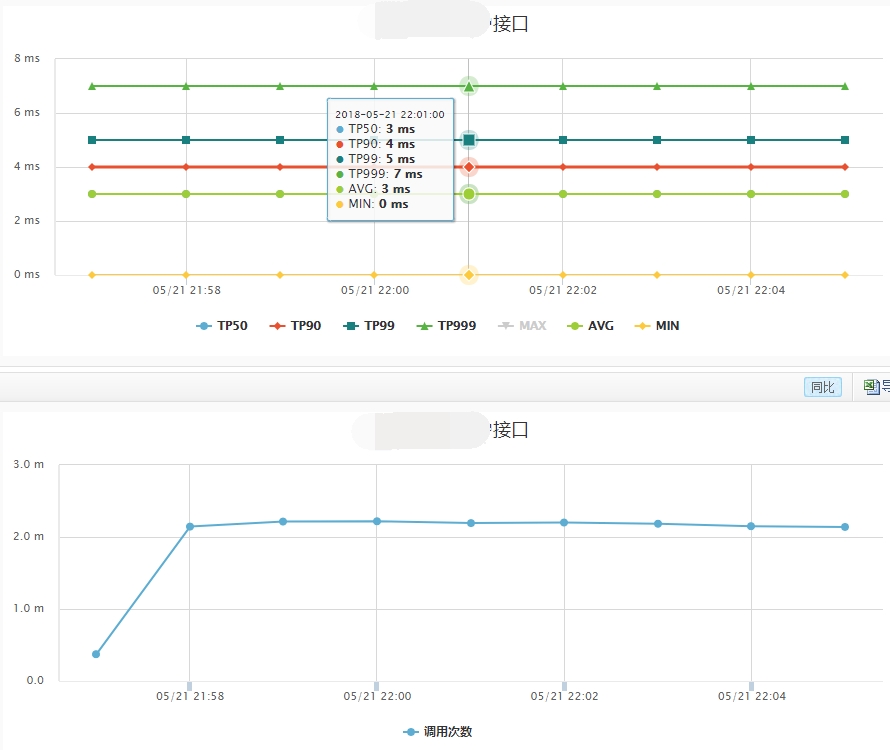
在非压测时接口性能提升为20%,以下是接口性能对比(稳定性也明显提高):
结论
这次升级和调整不仅达到了目标需求(减少GC停顿、提高TP999性能),同时获得了更多升级福利(吞吐量提高、响应更稳定),其他提供微服务的OLTP类应用也可以参考这此升级,使用JDK1.8和G1收集器。