渠道商用假量冒充真实用户:开发者求给条活路
【致敬原作者:http://www.leiphone.com/news/201406/0731-utlee-app-channel.html】
在移动互联网中是否存在作弊呢?答案显而易见。下面就描写了如何识别APP付费推广告作弊的。同样,重点来学习作者的思路。
正文开始:
创业者很苦憋的,苦于创意,苦于研发,苦于用户体验。
创业者很苦憋的,就算把产品做好了,不推广也很难获得用户。
创业者很苦憋的,遇上无量渠道商,花钱做推广,花时间做换量,可产品还是不见起色。
看看一个同样苦憋开发者的自述吧。
我做数据挖掘技术出身,并从事推广告工作,APP付费推广的作假现象已屡见不鲜,这次终于长见识了,见过作假的,没有见过那么扯淡的。
数万元推广费,获得上万激活量,只有7个真实用户。当然,还不排除这7个“真实”全是这个坑爹渠道的测试人员,产品、运营、商务的亲们千万小心了:
所在的公司长期做APP的换量及付费推广,最近上线一套智能算法用来甄别假量,发现某“渠道A”严重作弊刷假量。先来看看该渠道A最近一周的数据(注:因涉及产品机密数据,隐去了具体数值,仅表现大体趋势。下述所有图标均如此):
注册率
留存率
启动次数
(1)注册率
(2)一次留存用户
(3)启动次数(平均每人每日)
所有数据无明显异常,从数据上看,还是个“高质量渠道”。不甘心???!再多些深度数据(最近一周):
用户流失速度
用户回访间隔
铁杆用户比率
(1)用户流失速度
(2)用户回访间隔
(3)铁杆用户比率
常用的数据都查了,还是没有确凿的异常!好吧,不管愿意不愿意接受,苦逼的现实是:
传统的数据指标已经区分不出作假的渠道了。
怎么办?还有没有数据能够让作假无处遁形呢?有!比如用户的应用使用时长。
可以设想一下,刷假量的机器人毕竟不是真实用户,他们完成“制定”的操作任务后,不会再因为看到美女就猛点她的头像,也不会玩爽了再多玩会儿。那么来看一下用户使用时长曲线对比:
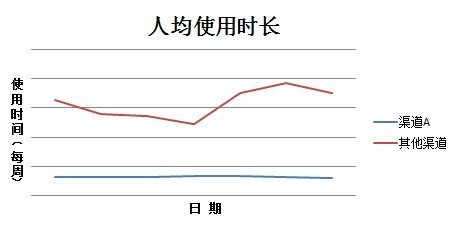
渠道A的使用时长远低于整体平均水平(其他渠道),且没有随着日期形成周期性规律震荡。总算是露马脚了,完全可以确定是机器人刷假量!
机器人刷假量,应该是能找出特征的,按以前的做法是对比IMEI号,但现在的刷量机器人却早就能伪造假IMEI了。
但依然可以根据IMEI寻找机器人特征,正常渠道的IMEI号极少重复,且重复的概率不随着时间推延而增大;而作弊渠道的IMEI重复率往往较高,且随着时间不短增长。
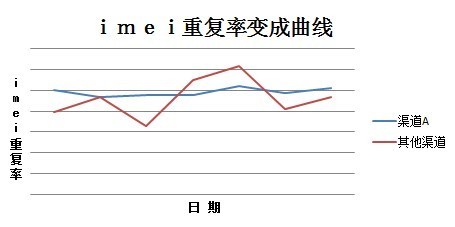
实际上IMEI数据还是不能看出异常,需要再想别的办法。不同的用户的手机,是用的不同通讯运营商(诸如移动、连通、电信)的电话卡,通过统计运营商游戏王找出机器人特征。为了作分析,抽样了一小撮用户,提取了他们的运营商信息,统计结果显示:

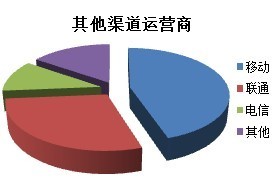
看来通过运营商的情况使分析不出机器人特征的。而我又抽样部分用户IP地址,不管是IP分布还是IP跨省概率都与正常用户一致。
一个血淋淋的事实摆在了眼前:
假用户的仿真度越来越高,识别它越来越难,而提取作假特征几乎已不可能。
当然,没有苦憋青年走不通的路,最终我们公司还是完成了取证。
抽样提取了该渠道部分Android用户所安装的APP列表,发现很多用户安装的APP是一样的。再深挖这个猫腻,结果得知:A渠道,一共制作了4组机器人,每组机器人数量若干,同组内机器人所安装的所有APP一模一样,且不增不减。
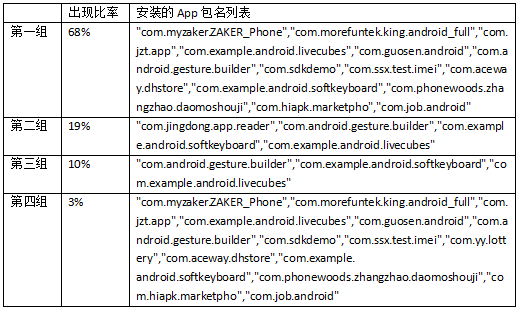
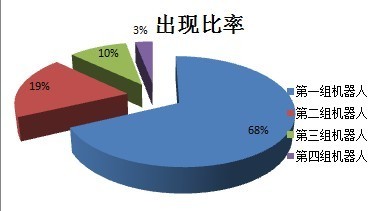
总算是把A渠道的机器人揪出来了,但是因为法律法规的问题,我们并不能把该渠道怎么样,只能是不给钱结算,然后将造假消息告诉认识的朋友。而且,时间的结果并没有像童话故事一样美满,苦憋的是我们又遇到了更无敌的机器人刷量,而且上述的所有判断方式全部失效(是否是机器人方式,保留观点)。真是道高一尺,魔高一丈。
至今为止,与我所在公司合作的渠道,有近3成查出了刷假量作弊,从2010年最简单的弱智关税;到2011年出现智能机器人,开始会模拟真实用户进行注册,还能够回访;再到2012年,机器人已经能做到个性化的高仿真。
而事后想想,这样的渠道能够提供如此高仿的假用户,让普通的开发者完全没办法区分,最大的原因就是因为暴力的驱使,花费数万元获得的上万激活却只有7个真实用户,这黑心钱也挣的太犀利了。这几乎是零成本的获利。
而且现在并没有多少家公司在查作弊,作弊的风险低,且无相关法规约束,作假也变得理所当然了。
此外,就我所知,做假量的激活CPA。单价仅仅在1角到7角之间,远低于真量的单价。中间巨大的差价带来了巨大的回扣空间。推广的负责人也许已经发现了作弊,但是受回扣驱使或者业绩压力,故意隐而不发也是由可能的。
总结,通过本文,我们可以看到作者的分析思路和指标及各指标可能的公司如下:
| 排查的顺序 | 排查的指标 | 可能的公式 | 维度 |
| 1 | 注册率 | 注册量/下载量 | 每天 |
| 2 | 留存率 | 开机量/注册量 | 每天 |
| 3 | 平均启动次数 | 启动总次数/启动唯一用户量 | 每天 |
| 4 | 用户流失曲线 | 符合流失标准的用户数/注册量 | 每天 |
| 5 | 回访平均间隔 | 回访间隔总时长/回访总次数 | 每版本 |
| 6 | 铁杆用户比率 | 符合铁杆标准的用户数/注册量 | 每天 |
| 7 | 人均使用时长 | 使用总时长/使用唯一用户量 | 每天 |
| 8 | IMEI重复率曲线 | 每日与之前所有IMEI重复总量/每日IMEI量 | 每天 |
| 9 | 运营商分布 | 注册量中某运营商总量/注册量 | 每天 |
| 10 | APP安装包出现比率 | 注册量中相同APP总量/注册量 | 每天 |