
![]()
大家好 我是阿喵
今天教大家用如何用爬虫爬取可爱小姐姐的美照
第一步:现将python环境搭建好,工欲利其事必先利其器!
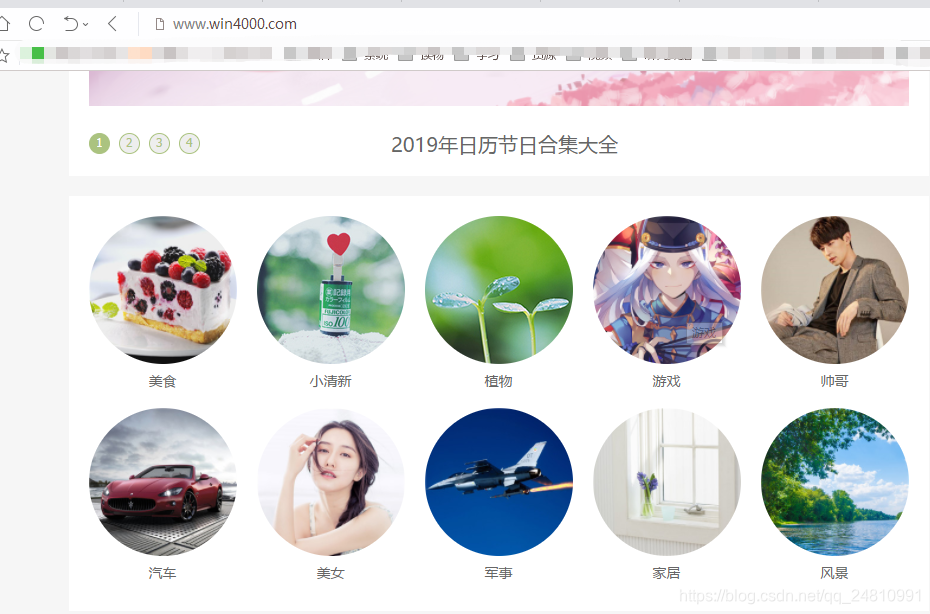
第二步:寻找目标网站,我选择的网站是http://www.win4000.com,里面有一个美女板块,里面有各种小姐姐的照片(你懂的)![]()
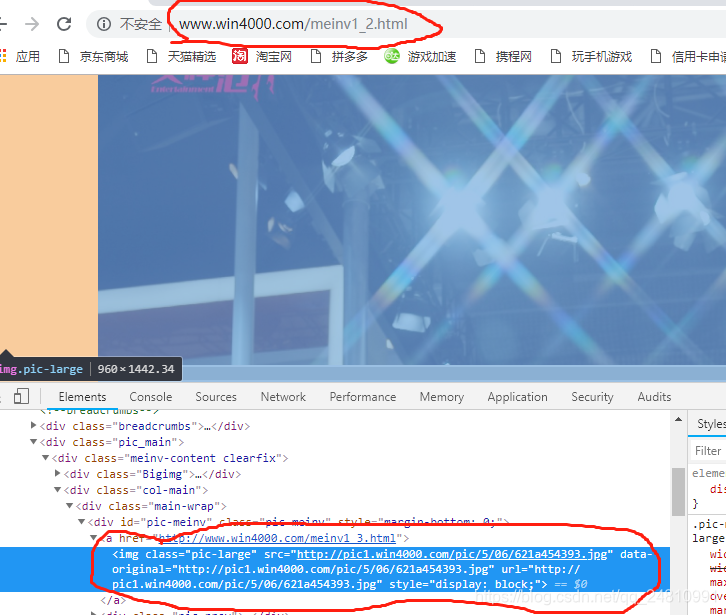
第三步:分析目标网站的html源码及网页规则
通过分析我发现,该网页每个人物的每个图片都是
http://www.win4000.com/meinv1_2.html
http://www.win4000.com/meinv1_3.html
http://www.win4000.com/meinv2_1.html
http://www.win4000.com/meinv2_2.html
并且所有图片地址都存放在一个中![]()
# coding:utf-8
from bs4 import BeautifulSoup #引用BeautifulSoup库
import requests #引用requests
import os #os
root = 'D://img//' #配置存储路径,我配置的是自己电脑中的D:/img文件夹
for page in range(1,1000): #配置爬取页码,我这边配置的是1000个人的图片
for p in range(1,20): #配置爬取每个人多少张的参数,我这边配置的是每个人20张
url = 'http://www.win4000.com/meinv'+str(page)+'_'+str(p)+'.html'
r = requests.get(url) #使用requests中的get方法获取整个网页
r.encoding='utf-8' #设定网页所使用的编码方式,错误的编码方式会导致乱码
if r.status_code!=404: #判断生成后的链接是不是能访问,只有能访问才能爬取下载
demo = r.text #将爬取后的对象通过text方法提取出所有的html
soup = BeautifulSoup(demo, "html.parser")#使用BeautifulSoup库进行整合,第二个参数使用lxml一样的,lxml兼容性好较好,速度较快
text = soup.find_all('img',class_ = 'pic-large')#选取整合后我们需要的部分内容,选取后的数据为list数组
for img in text:
imagr_url = img.get('data-original') #取出img标签中data-original中的值
file_name = root + imagr_url.split('/')[-1] #取出图片地址中文件及文件扩展名与本地存储路径进行拼接
try:
if not os.path.exists(root): #判断文件夹是否存在,不存在则创建文件夹
os.mkdir(root)
if not os.path.exists(file_name): #判断图片文件是否存在,存在则进行提示
s = requests.get(imagr_url) #通过requests.get方式获取文件
# 使用with语句可以不用自己手动关闭已经打开的文件流
with open(file_name, "wb") as f: # 开始写文件,wb代表写二进制文件
f.write(s.content)
print("爬取完成")
else:
print("文件已存在")
except Exception as e:
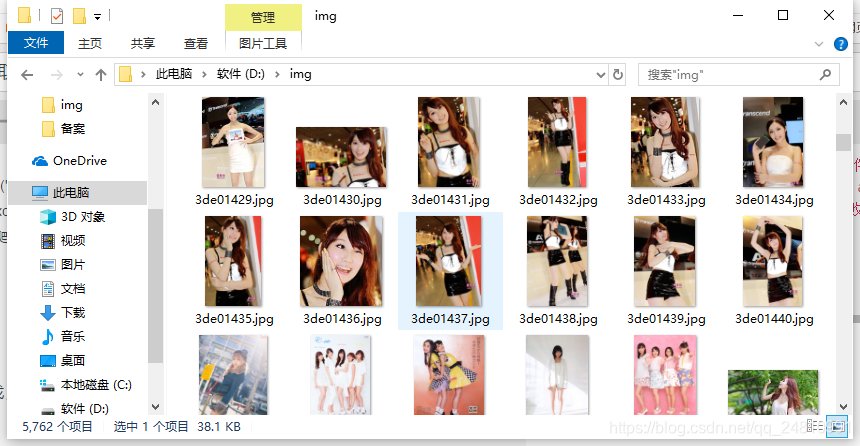
print("爬取失败:" + str(e))哈哈哈哈大功告成,以下是成果展示![]()
总结:
1、该方式爬取为单进程爬取,只能一张一张爬取
2、进行图片请求时一定要注意不要使用之前使用过的变量
3、细心、认真、不浮躁
看完文章如果大家觉得有帮助,记得一键三连哦,非常感谢,在这里还是要推荐下我自己建的Python学习群:609616831,群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2020最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!

![]()