【01】查询类型:

【02】基本查询和组合查询是参与打分的
1.创建映射:

注意事项:基于上面映射的创建:
"type": "keyword" # 如果某个字段的值被设置为keyword,那么这个值就不会被分析器所分析
"type": "text" # 这里设置类型为text,但我们没有设置分词器使用ik_max_word,因此ES会使用内置的分析器对中文进行分词,但是这种效果比不上ik_max_word
对于中文分词器,推荐去Github上搜索:
去github上去寻找这个插件:https://github.com/medcl/elasticsearch-analysis-ik
【02】在上面的基础上,我们来导入4条数据:
POST lagou/job/
{
"title":"python django 开发工程师",
"company_name": "美团科技有限公司",
"desc": "对django的概念熟悉,熟悉python基础知识",
"comments":20,
"add_time":"2017-4-1"
}
POST lagou/job/
{
"title":"python redis分布式爬虫基本",
"company_name": "百度科技有限公司",
"desc": "对scrapy的概念熟悉,熟悉redis基础知识",
"comments":5,
"add_time":"2017-4-15"
}
POST lagou/job/
{
"title":"elasticsearch打造搜索引擎系统",
"company_name": "阿里巴巴科技有限公司",
"desc": "熟悉数据结构算法,熟悉python的基本开发",
"comments":15,
"add_time":"2017-4-12"
}
POST lagou/job/
{
"title":"python打造推荐引擎系统",
"company_name": "阿里巴巴科技有限公司",
"desc": "熟悉推荐引擎的原理以及算法,掌握C语言",
"comments":66,
"add_time":"2017-4-12"
}
【001】重要查询之match查询,使用了分词查询:
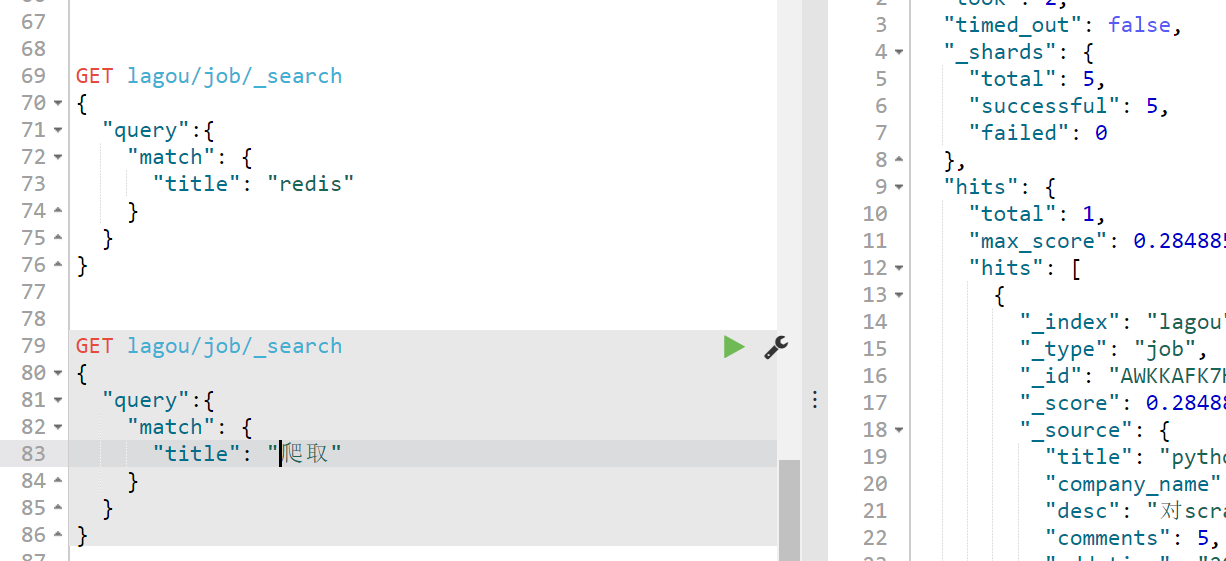
【002】【02】term查询与get查询的区别:term查询传递进来的关键词是不会做任何处理的,也就是说不会进行分词,如下查询python爬虫是查询不到的:
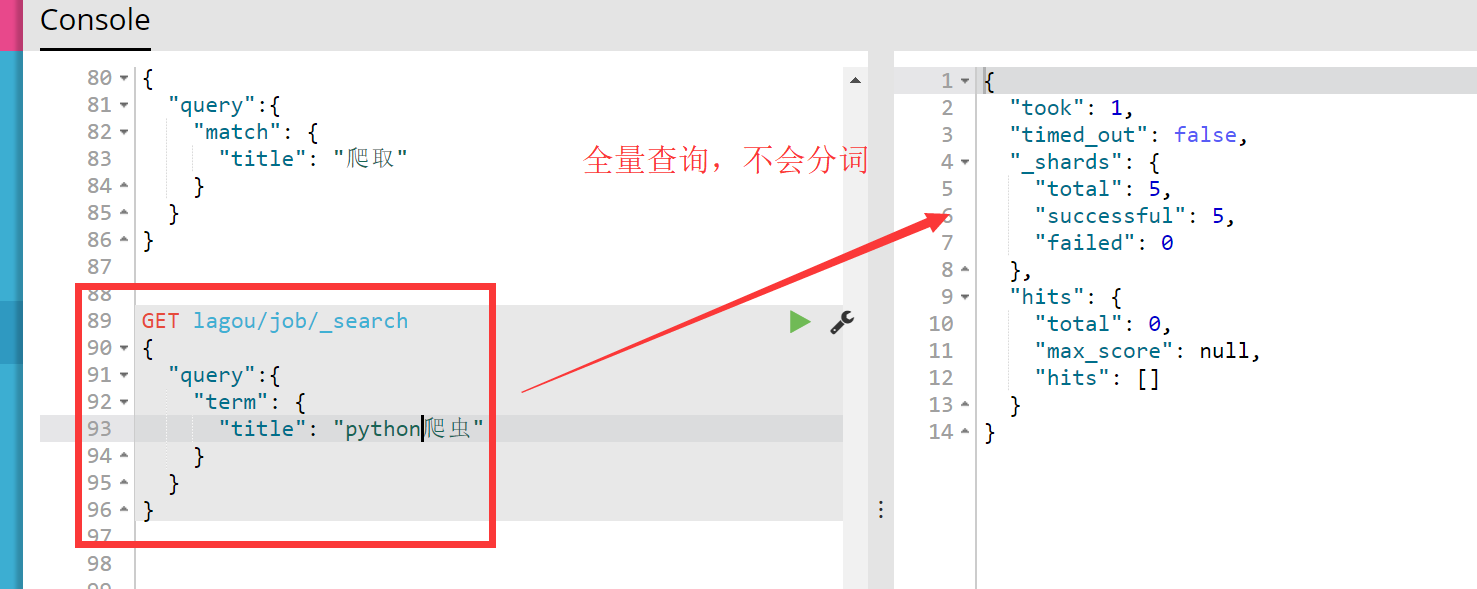
term查询查询不到,但是match查询却可以,如下:
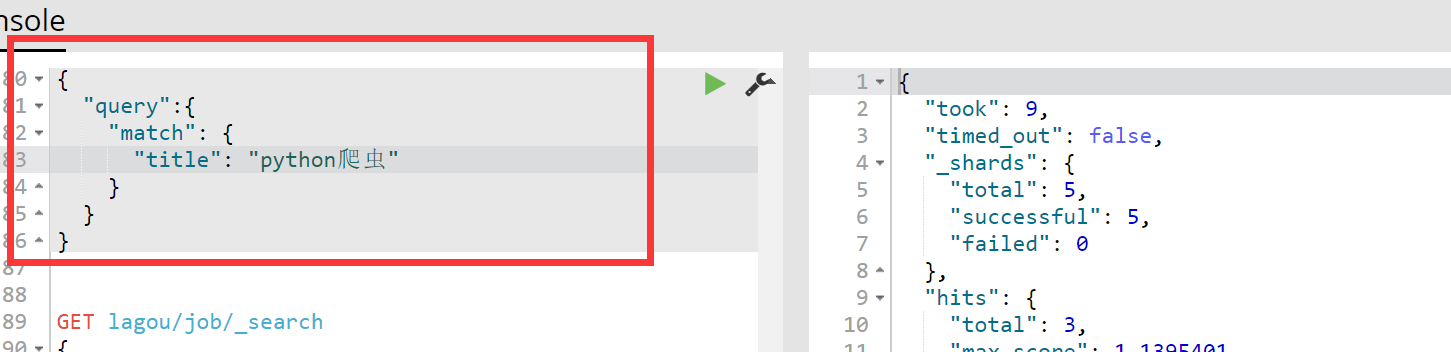
company_name是keyword类型,因此不会被分词器分析,只有完全匹配:
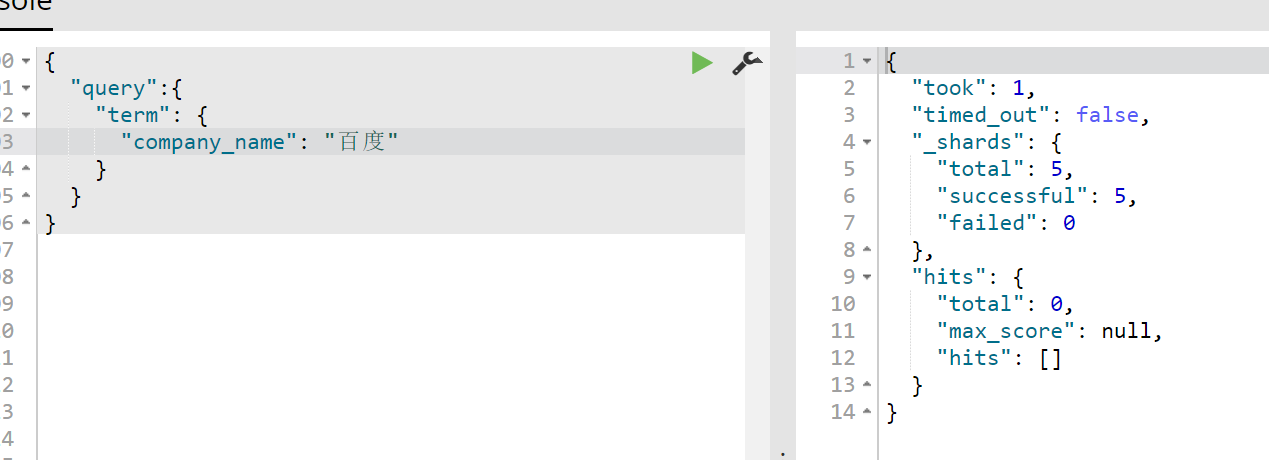
同样的道理,即使match查询可以分词,但是company_name是key_word类型,因此也是查询不到的,如下:
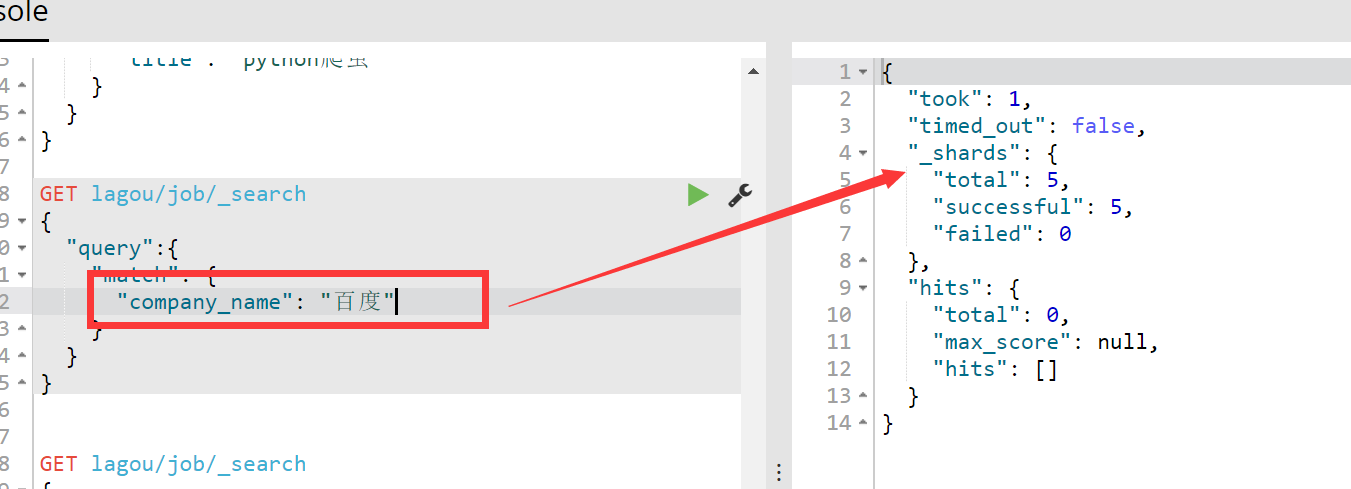
terms查询:只要满足了数组里面的任何一个值都可以查询出来

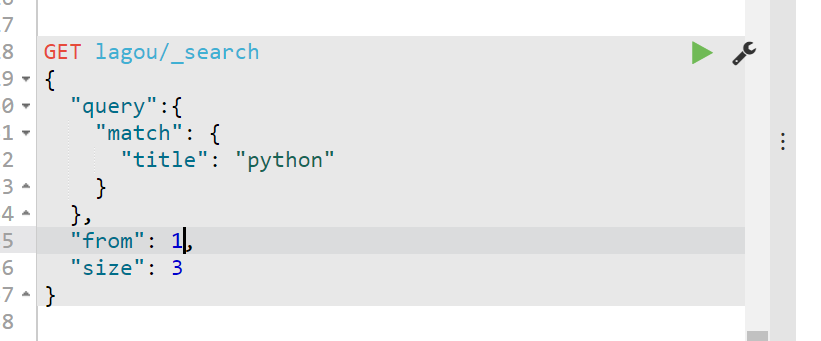
基于From和size来完成分页——# 控制查询的返回数量,主要用来做分页
未完待续