一、项目编码实现
- HDFS文件上传
- HDFS文件下载
- 定位文件读取
- 通过API操作HDFS
- 通过IO流操作HDFS
- HDFS写数据流程
- HDFS读数据流程
- 统计一堆文件中单词出现的个数(WordCount案例)
- 把单词按照ASCII码奇偶分区
- 统计手机号耗费的总上行流量、下行流量、总流量(序列化)
二、流程图及描述
- HDFS写数据流程
- HDFS读数据流程
- NameNode&Secondary NameNode工作机制
- 查看fsimage文件
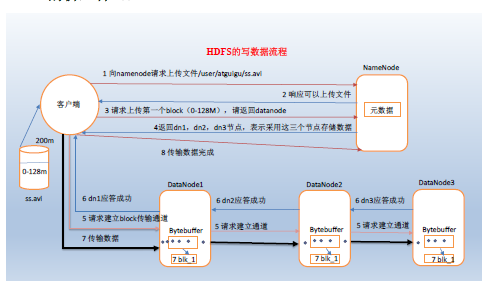
写数据流程
读数据流程

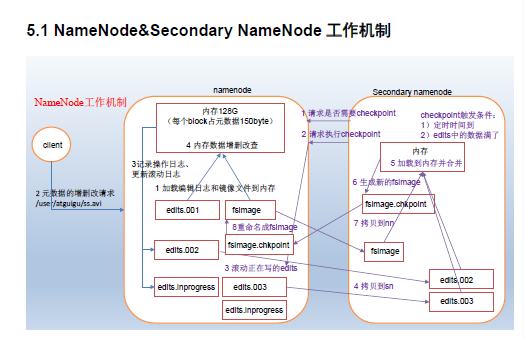
namenode和secondary namenode机制
查看镜像文件

查看编辑日志

DataNode工作机制

查看归档文件

(4)解归档文件
hadoop fs -cp har:///user/my/myhar.har/* /user/hadoop
- 查看edits文件
- 模拟namenode故障,并采用任一方法,恢复namenode数据
- 集群安全模式操作1
- DataNode工作机制
- 服役新数据节点
- 退役旧数据节点
- 回收站配置
- MapReduce程序运行流程分析
安全模式

回收站(参看hdfs,要与hdoop-site.xml里内容的刷新一致)
7.4 回收站
1)默认回收站
默认值fs.trash.interval=0,0表示禁用回收站,可以设置删除文件的存活时间。
默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。
要求fs.trash.checkpoint.interval<=fs.trash.interval。
2)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
3)查看回收站
回收站在集群中的;路径:/user/hadoop/.Trash/….
4)修改访问垃圾回收站用户名称进入垃圾回收站用户名称,默认是dr.who,修改为hadoop用户
[core-site.xml]
<property>
38 / 40
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
5)通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
6)恢复回收站数据
hadoop fs -mv /user/hadoop/.Trash/Current/user/hadoop/input /user/hadoop/input
7)清空回收站
hdfs dfs -expunge
服役新节点
6.5 服役新数据节点(参看hdfs学习)
0)需求:
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1)环境准备(1)克隆一台虚拟机(2)修改ip地址和主机名称(3)修改xcall和xsync文件,增加新增节点的同步(4)删除原来HDFS文件系统留存的文件
/home/hadoop/hadoop_home/dfs/name
2)服役新节点具体步骤(1)在namenode的~/hadoop_home /etc/hadoop目录下创建dfs.hosts文件
hadoop@master:~/hadoop_home/etc/hadoop$ pwd
/home/hadoop/hadoop_home/etc/hadoop
hadoop@master:~/hadoop_home/etc/hadoop$ touch dfs.hosts
hadoop@master:~/hadoop_home/etc/hadoop$ vi dfs.hosts
添加如下主机名称(包含新服役的节点)
node3
node4
node5 (2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/home/hadoop/hadoop_home/etc/hadoop/dfs.hosts</value>
</property> (3)刷新namenode
[hadoop@nod1:~/hadoop_home]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful (4)更新resourcemanager节点
[hadoop@nod1:~/hadoop_home]$ yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at node2/192.168.0.242:8033 (5)在namenode的slaves文件中增加新主机名称增加node 不需要分发
node1
node2
node3 (6)单独命令启动新的数据节点和节点管理器
hadoop@master:~/hadoop_home$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/hadoop_home/logs/hadoop-hadoop-datanode-node3.out
hadoop@master:~/hadoop_home$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /home/hadoop/hadoop_home/logs/yarn-hadoop-nodemanager-hadoop105.out (7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
[hadoop@node2 sbin]$ ./start-balancer.sh
starting balancer, logging to /home/hadoop/hadoop_home/logs/hadoop-hadoop-balancer-master.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
6.6 退役旧数据节点(参看hdfs学习)
1)在namenode的/home/hadoop/hadoop_home/etc/hadoop目录下创建dfs.hosts.exclude文件
33 / 40
[hadoop@node2 hadoop]$ pwd
/home/hadoop/hadoop_home/etc/hadoop
[hadoop@node2 hadoop]$ touch dfs.hosts.exclude
[hadoop@node2 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
node3
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop_home/etc/hadoop/dfs.hosts.exclude</value>
</property>
3)刷新namenode、刷新resourcemanager
[hadoop@nod1:~/hadoop_home]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[hadoop@nod1:~/hadoop_home]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at node/192.168.0.242:8033
4)检查web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点。

5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。·

hadoop@master:~/hadoop_home$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
hadoop@master:~/hadoop_home$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
6)从include文件中删除退役节点,再运行刷新节点的命令
34 / 40
(1)从namenode的dfs.hosts文件中删除退役节点hadoop105
node3
node4
node5
(2)刷新namenode,刷新resourcemanager
[hadoop@nod1:~/hadoop_home]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[hadoop@nod1:~/hadoop_home]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
7)从namenode的slave文件中删除退役节点node5
node3
node4
node5
8)如果数据不均衡,可以用命令实现集群的再平衡
[hadoop@nod1:~/hadoop_home]$ sbin/start-balancer.sh
starting balancer, logging to /home/hadoop/hadoop_home/logs/hadoop-hadoop-balancer-master.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
MapReduce核心思想




mapreduce框中的shuffle过程一定会对key进行排序




Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
面试提到的缓存就是提高效率
缓冲区的大小可以通过参数调整,参数:io.sort.mb 默认100M
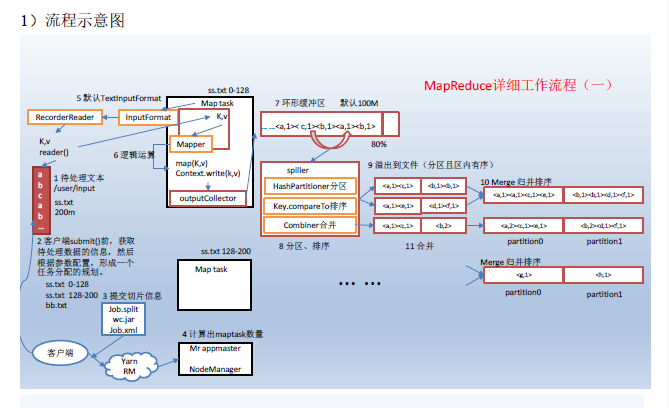
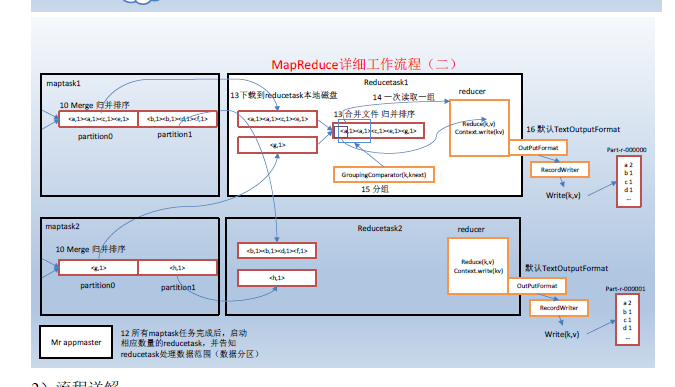

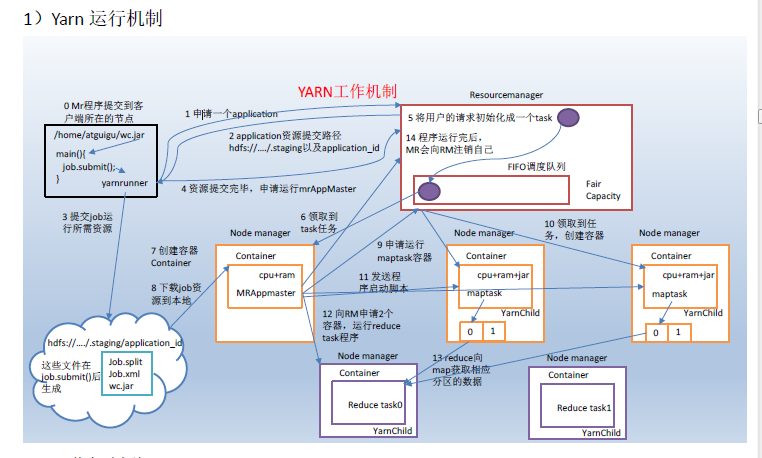
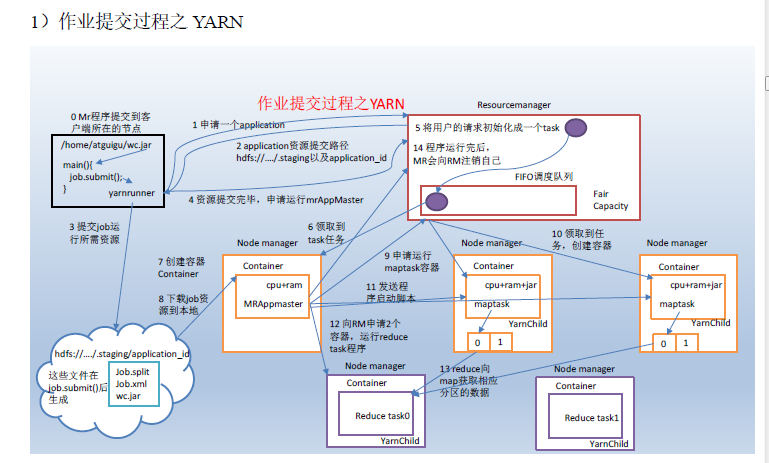
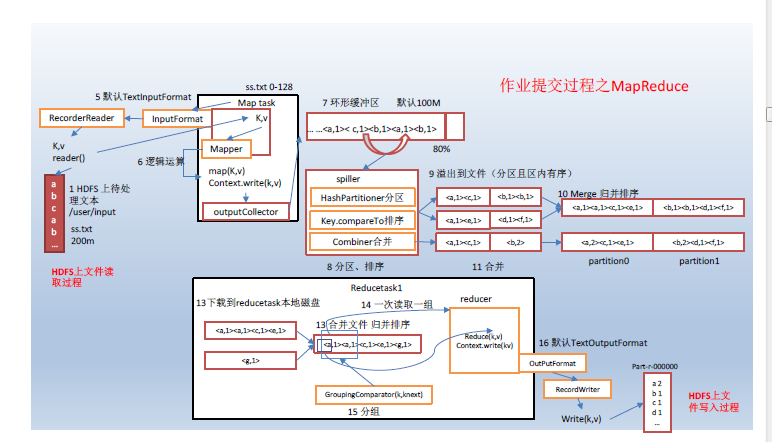
上图之所以缓存区是因为提高效率,当缓存区满了之后再写入文件,这样会提高效率,而且写入缓存,效率也高

