起初是一个自动化测试工具;但是在爬虫上可以 用来解决 requests 无法直接执行 JavaScript 代码的问题。
本质:通过驱动浏览器,模拟浏览器的操作(跳转、点击、下拉等), 取到网页渲染之后的结果
注:支持多种浏览器;如:Chrome、Firefox、PhantomJS、Safari、Edge等
安装
pip3 install selenium 还需要下载 chromdriver.exe 配合使用,放在python安装路径的script目录即可
国内镜像网站地址:http://npm.taobao.org/mirrors/chromedriver/2.38/ 官网:https://sites.google.com/a/chromium.org/chromedriver/downloads
直接放在 Pycharm 的根目录下就可以
基本使用
from selenium import webdriver browser = webdriver.Chrome() # 以谷歌浏览器为例,生成一个浏览器对象 browser.get(url) browser.page_source # 返回的结果(HTML页面数据) browser.current_url # 页面当前的 url browser.get_cookies() # 加入是登录请求,可以取出返回来的所有 cookie 值 browser.get_cookie(key) # 加入是登录请求,可以取出返回来的cookie中key为key对应的值
无界面浏览器
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('window-size=1920x3000')
# 指定浏览器分辨率
chrome_options.add_argument('--disable-gpu')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars')
# 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 不加载图片, 提升速度
chrome_options.add_argument('--headless')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_options.binary_location = r"C:Program Files (x86)GoogleChromeApplicationchrome.exe"
# 手动指定使用的浏览器位置 browser = webdriver.Chrome(chrome_options=chrome_options) # 设置 chrome_options 参数 browser.get('https://www.baidu.com') print('hao123' in driver.page_source) browser.close() # 切记关闭浏览器,回收资源
进阶使用
# 1、find_element_by_id 根据具体的 id 查找 有且只有一个 browser.find_element_by_id('kw') # 2、find_element_by_link_text 根据带有链接的文本查找第一个 # 2.1、find_elements_by_link_text 根据带有链接的文本查找多个[列表形式返回结果] login = browser.find_element_by_link_text('登录') # 找到登录的 button 按钮 login.click() # 点击 # 3、find_element_by_partial_link_text 根据带有链接的部分文本内容查找第一个 # 3.1、find_elements_by_partial_link_text 根据带有链接的部分文本内容查找所有 login = browser.find_elements_by_partial_link_text('录')[0] login.click() # 4、find_element_by_tag_name 个根据标签名字查找第一个 # 4.1、find_elements_by_tag_name 个根据标签名字查找所有 browser.find_element_by_tag_name('a') # 5、find_element_by_class_name 根据类名查找第一个 # 5.1、find_elements_by_class_name 根据类名查找所有 button = browser.find_element_by_class_name('kkk') button.click() # 6、find_element_by_name 根据属性名查找第一个 # 6.1、find_elements_by_name 根据属性名查找所有 input_user = browser.find_element_by_name('userName') input_pwd = browser.find_element_by_name('password') input_user.send_keys('账户') input_pwd.send_keys('密码') submit_button = browser.find_element_by_id('TANGRAM__PSP_10__submit') submit_button.click() # 7、find_element_by_css_selector 根据 css 选择器查找第一个 # 7、find_elements_by_css_selector 根据 css 选择器查找所有 browser.find_element_by_css_selector('#kw') # 根据 id browser.find_element_by_css_selector('.kw') # 根据 class
------------------------------------------------------------------------------------- # 8、find_element_by_xpath 根据 xpath 语法 进行查找第一个 # 8.1、find_elements_by_xpath 根据 xpath 语法进行查找所有
详细使用:https://www.w3school.com.cn/xpath/xpath_syntax.asp
基础语法:

通配符:
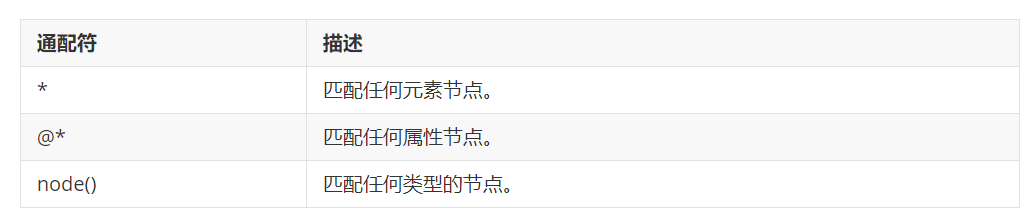
示例:
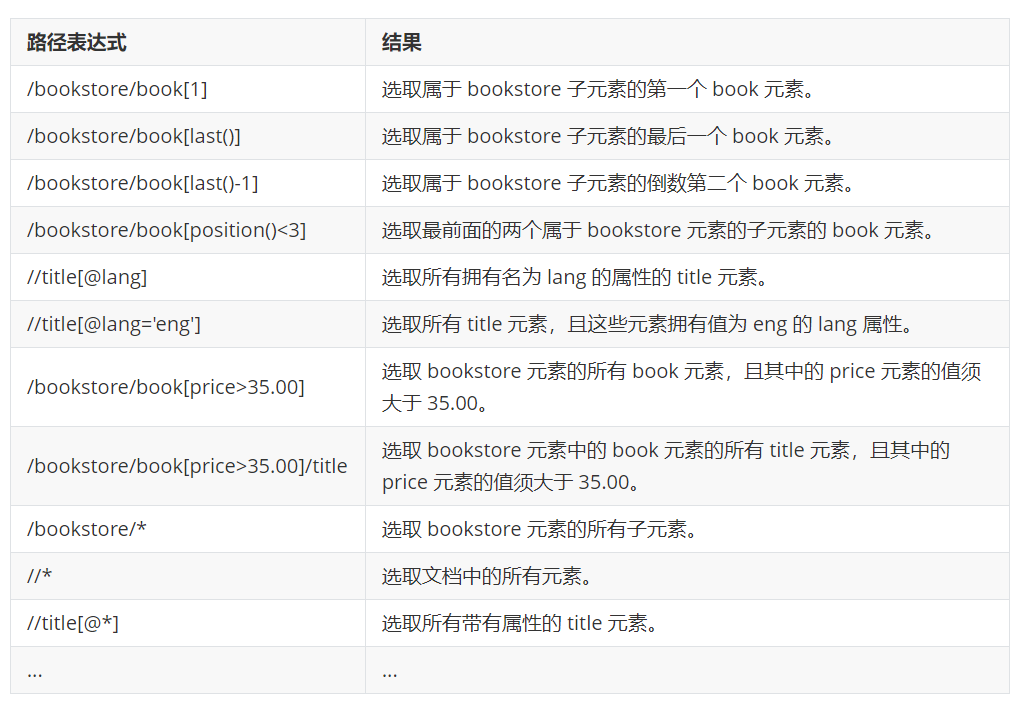
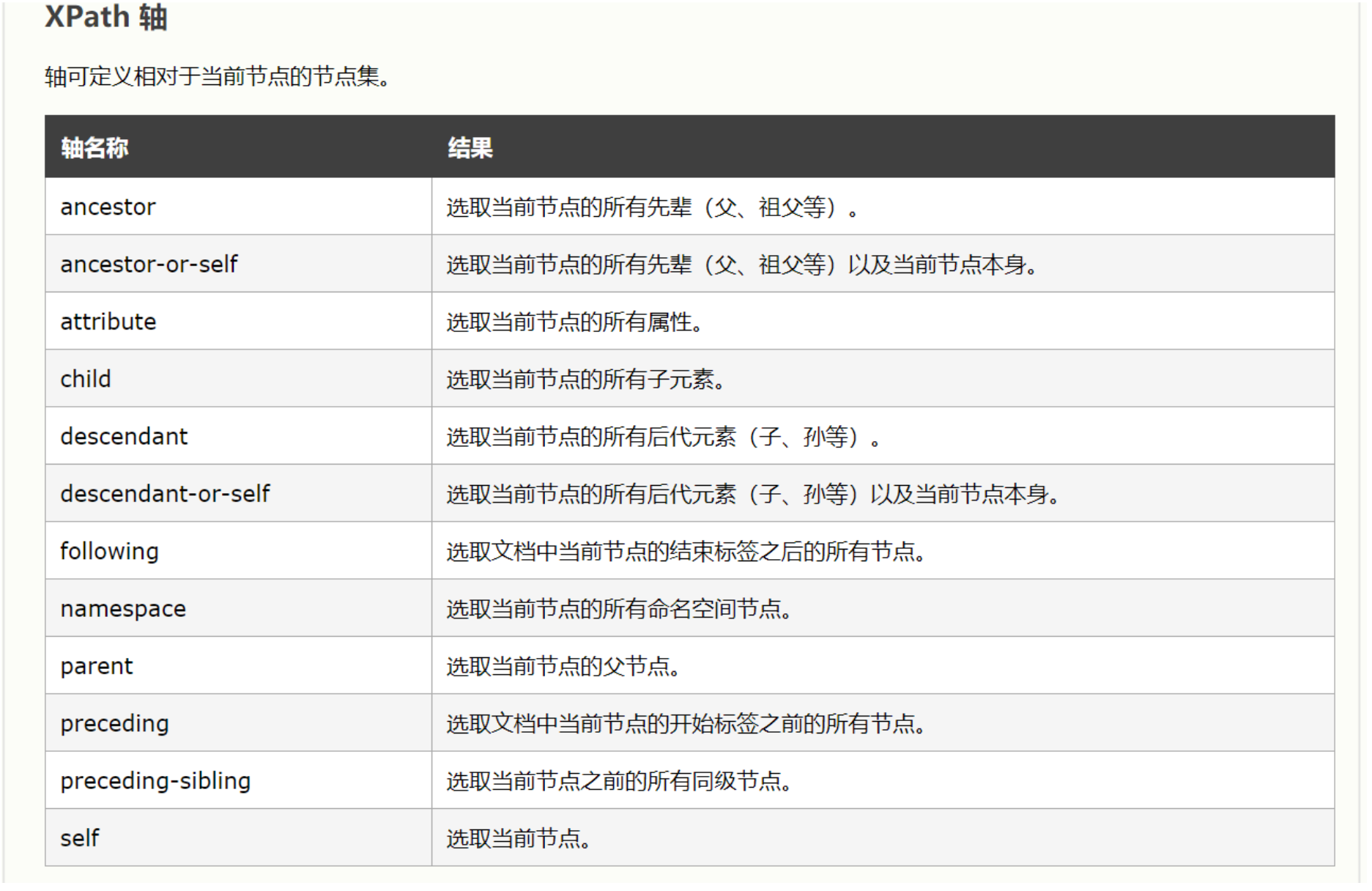

例子使用:https://www.cnblogs.com/xiaoyuanqujing/articles/11805718.html
获取标签属性
from selenium import webdriver from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID, By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser = webdriver.Chrome() browser.get('https://www.amazon.cn/') # tag = browser.find_element_by_css_selector('#cc-lm-tcgShowImgContainer img') 等同与下 tag = browser.find_element(By.CSS_SELECTOR, '#cc-lm-tcgShowImgContainer img') # 获取标签属性 print(tag.get_attribute()) # 获取标签 src 属性 print(tag.get_attribute('src')) # 获取标签 ID,位置,名称,大小(了解) print(tag.id) print(tag.location) print(tag.tag_name) print(tag.size) input_tag = browser.find_element_by_id('kw') input_tag.send_keys('美女') # python2 中输入中文错误,字符串前加个u input_tag.send_keys(Keys.ENTER) # 输入回车 browser.close()
''' selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js) 一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待 ''' # 等待的方式分两种: # 1、隐式等待:在 browser.get('xxx')前就设置,针对所有元素有效 --------------> 推荐使用 from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser = webdriver.Chrome() # 隐式等待:在查找所有元素时,如果尚未被加载,则等10秒(10秒内加载出来则直接查找,不是每次都10秒) browser.implicitly_wait(10) # get 之前 browser.get('https://www.baidu.com') # 再执行操作 # 2、显式等待:在 browser.get('xxx')之后设置,只针对某个元素有效 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser = webdriver.Chrome() browser.get('https://www.baidu.com') wait = WebDriverWait(browser, 10) # get 之后 wait.until(EC.presence_of_element_located((By.ID,'content_left'))) # 再执行操作
功能补充
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.baidu.com') browser.back() # 模拟浏览器的后退 browser.forward() # 模拟浏览器的前进 browser.get_cookies() # 获取 cookies browser.add_cookie('字典形式') # 添加 cookie browser.delete_all_cookies() # 删除所有 cookies browser.window_handles # 获取所有的选项卡 browser.switch_to_window(browser.window_handles[1]) # 移动到底1个选项卡 # 在交互动作比较难实现时候可以自己写 JS ---> execute_script browser.execute_script('alert("hello world")') # 打印警告 browser.close()
异常处理
from selenium import webdriver from selenium.common.exceptions import TimeoutException, NoSuchElementException, NoSuchFrameException try: browser = webdriver.Chrome() browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') browser.switch_to.frame('iframssseResult') except TimeoutException as e: print(e) except NoSuchFrameException as e: print(e) finally: browser.close()
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 import time def get_goods(driver): try: goods = driver.find_elements_by_class_name('gl-item') for good in goods: detail_url = good.find_element_by_tag_name('a').get_attribute('href') p_name = good.find_element_by_css_selector('.p-name em').text.replace(' ','') price = good.find_element_by_css_selector('.p-price i').text p_commit = good.find_element_by_css_selector('.p-commit a').text msg = ''' 商品 : %s 链接 : %s 价钱 :%s 评论 :%s ''' % (p_name, detail_url, price, p_commit) print(msg, end=' ') button = driver.find_element_by_partial_link_text('下一页') button.click() time.sleep(1) get_goods(driver) except Exception: pass def spider(url,keyword): driver = webdriver.Chrome() driver.get(url) driver.implicitly_wait(3) # 使用隐式等待 try: input_tag=driver.find_element_by_id('key') input_tag.send_keys(keyword) input_tag.send_keys(Keys.ENTER) get_goods(driver) finally: driver.close() if __name__ == '__main__': spider('https://www.jd.com/',keyword='iPhone8手机')