推荐算法:
推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西,目前应用推荐算法比较好的地方主要是网络,其中淘宝做的比较好。
发展背景:
推荐算法的研究起源于20世纪90年代,由美国明尼苏达大学 GroupLens研究小组最先开始研究,他们想要制作一个名为 Movielens的电影推荐系统,从而实现对用户进行电影的个性化推荐。首先研究小组让用户对自己看过的电影进行评分,然后小组对用户评价的结果进行分析,并预测出用户对并未看过的电影的兴趣度,从而向他们推荐从未看过并可能感兴趣的电影。此后, Amazon开始在网站上使用推荐系统,在实际中对用户的浏览购买行为进行分析,尝试对曾经浏览或购买商品的用户进行个性化推荐。根据 enture Beat的统计,这一举措将该网站的销售额提高了35%自此之后,个性化推荐的应用越来越广泛。
推荐算法分类:
基于内容:项目或对象是通过相关特征的属性来定义的,系统基于用户评价对象的特征、学习用户的兴趣,考察用户资料与待预测项目的匹配程度。用户的资料模型取决于所用的学习方法,常用的有决策树、神经网络和基于向量的表示方法等。基于内容的用户资料需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。
基于协同:基于协同过滤的推荐算法( Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度来对目标用户进行推荐。
基于关联规则:以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集y,其直观的意义就是用户在购买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会购买面包。
基于效用:基于效用的推荐(Utility-based Recommendation)是建立在对用户使用项目的效用情况上计算的,其核心问题是怎样为每一个用户去创建一个效用函数,因此,用户资料模型很大程度上是由系统所采用的效用函数决定的。
基于知识:基于知识的方法因它们所用的功能知识不同而有明显区别。效用知识( FunctionalKnowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
组合推荐:由于各种推荐方法都有优缺点,所以在实际中,组合推荐( Hybrid Recommendation)经常被采用。研究和应用最多的是内容推荐和协同过滤推荐的组合。

协同过滤推荐:
1.启发式推荐算法(Memory-based algorithms)
启发式推荐算法易于实现,并且推荐结果的可解释性强。启发式推荐算法又可以分为两类:
基于用户的协同过滤(User-based collaborative filtering):主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。举个例子,李老师和闫老师拥有相似的电影喜好,当新电影上映后,李老师对其表示喜欢,那么就能将这部电影推荐给闫老师。
基于物品的协同过滤(Item-based collaborative filtering):主要考虑的是物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。举个例子,如果用户A、B、C给书籍X,Y的评分都是5分,当用户D想要买Y书籍的时候,系统会为他推荐X书籍,因为基于用户A、B、C的评分,系统会认为喜欢Y书籍的人在很大程度上会喜欢X书籍。
2.基于模型的推荐算法(Model-based algorithms)
基于模型的推荐算法利用矩阵分解,有效的缓解了数据稀疏性的问题。矩阵分解是一种降低维度的方法,对特征进行提取,提高推荐准确度。基于模型的方法包括决策树、基于规则的模型、贝叶斯方法和潜在因素模型。
推荐框架:tensorflow,pytorch
推荐系统的目的:
1.帮助用户快速找到想要的商品,提高用户对网站的忠诚度;
2.提高网站交叉销售能力、成交转化率;
流程
首先,找到User1 喜欢的商品;
找出与User1具有相同的商品兴趣爱好的人群;
找出该人群喜欢的其他商品;
将这些商品推送给User1。
例子
两名用户都在某电商网站购买了A、B两种产品。当他们产生购买这个动作的时候,两名用户之间的相似度便被计算了出来。其中一名用户除了购买了产品A和B,还购买了C产品,此时推荐系统会根据两名用户之间的相似度会为另一名用户推荐项目C。
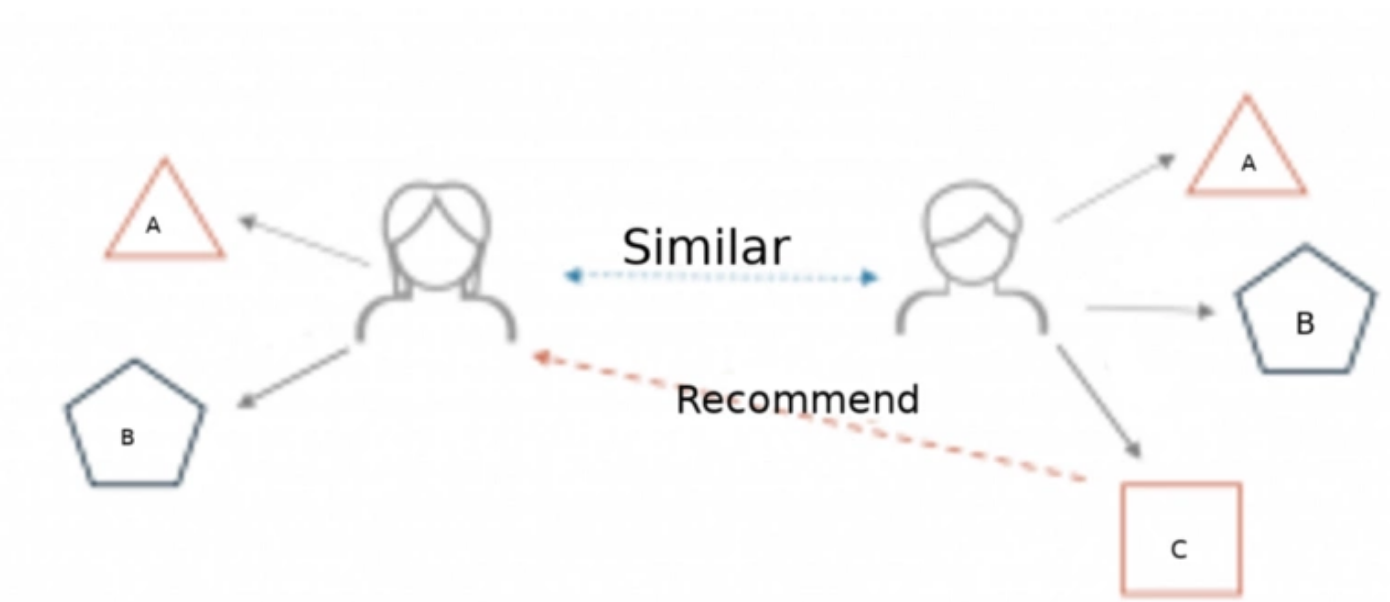
难点1:如何获取兴趣相似的用户
思路:通过购买过相同商品为介质,关联用户的关系
难点2:计算相似度
欧氏距离计算(计算两个点之间的直线距离)
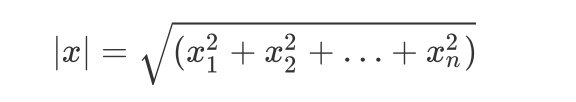
import math # 计算两点之间的距离 def eucliDist(A,B): return math.sqrt(sum([(a - b)**2 for (a,b) in zip(A,B)])) X = [1,2,3,4] Y = [0,1,2,3] print(eucliDist(X,Y))
根据用户的购买/收藏关系推荐商品


data = { "1":{"诺基亚":4.8,'iphone':5.0,"联想":0.1}, "2":{"诺基亚":3.0,"vivo":5.0,"htc":0.2}, "3":{"锤子":0.1,"魅族":0.3,"一加":5.0} } #| x | = √(x[1]2 + x[2]2 + … + x[n]2) from math import * #pow返回 xy(x的y次方) 的值 #sqrt返回数字x的平方根 #计算用户之间的相似度 def Euclid(user1,user2): #根据key获取value user1_data = data[user1] user2_data = data[user2] distance = 0 for key in user1_data.keys(): if key in user2_data.keys(): distance += pow(float(user1_data[key]) - float(user2_data[key]),2) #变成小数便于比较,值越小相似度越高 return 1/(1+sqrt(distance)) print(Euclid("1","2")) #构建最相似的用户top_people def top_user(user): res = [] for uid in data.keys(): if not uid == user: simliar = Euclid(user,uid) res.append((uid,simliar)) res.sort(key=lambda val:val[1]) return res print(top_user('1')) #构建推荐商品 def recommend(user): top_people = top_user(user)[0][0] #获取当前相似度最高的用户的商品列表 items = data[top_people] recommed_list = [] for item in items.keys(): #当这个商品不存在于目标用户的商品列表中,添加到推荐列表中 if item not in data[user].keys(): recommed_list.append((item,items[item])) #根据推荐列表里的打分请款从小到大排序,然后反转 recommed_list.sort(key=lambda val:val[1],reverse=True) #取出top10推荐 return recommed_list[:10] print(recommend("1"))