深度学习 - 复习 6-25 下午 机电504
10道简答题
【平时作业】理论,网络原理的理解
0. 损失
损失对于单个样本而言是一个数值,反映了模型预测的准确度。
- 平方损失(又称为(L_2)损失)
- 单个样本的平方损失:((y-hat{y})^2)
- 均方误差(MSE)指的是样本的平均平方损失:(frac{1}{N}sum (y-pred(x))^2)
1. 几种最优化方法&过拟合分析
最优化方法:通过迭代方法降低损失。学习过程通常不断迭代,直到总体损失不再变化或至少变化极其缓慢为止,该模型已收敛。

最优化过程:以只有一个参数(w)为例,所产生的Loss与w的函数是一个凸函数,只有一个凸函数。
训练方式:首先初始化一个起点,然后迭代寻找最优点。

对于一组给定的参数(W),梯度描绘了(R^n)空间中的点下一次运动的趋势。




Mini-batch SGD 比 SGD 效果好很多,所以一般说SGD都是指的 Mini-batch gradient descent
- 两种数据划分方式
- 训练集 + 测试集
- 训练集 + 验证集 + 测试集

- Monmentum 动量法(动量随机梯度下降)



动量法的超参数为:学习率(epsilon),动量参数(alpha)。 动量法的学习率不变
即学习率由两部分组成,一个是超参数 (epsilon),另一个是历次梯度平方和

- RMSProp => 遗忘过去版本的 AdaGrad
- Adam => 结合了动量法和自适应梯度
过拟合分析:
首先看是什么图:loss还是score
以loss图为例:train 、val 都高,说明高偏差。train低,val高说明高方差。
-
查准率,精准率 precision:(frac{TP}{TP+FP}) 预测为阳性的样本中,有多少预测对了
-
查全率,召回率 recall:(frac{TP}{TP+FN}) 真实为阳性的样本中,有多少被预测对了
-
准确率 accuracy: (frac{TP+TN}{TP+TN+FP+FN}) 全部样本中,预测正确了多少
-
F1-score:(F_1 = frac{2 * recall * precision}{recall + precision}) 只有recall和precision都高,F1-score才高
-
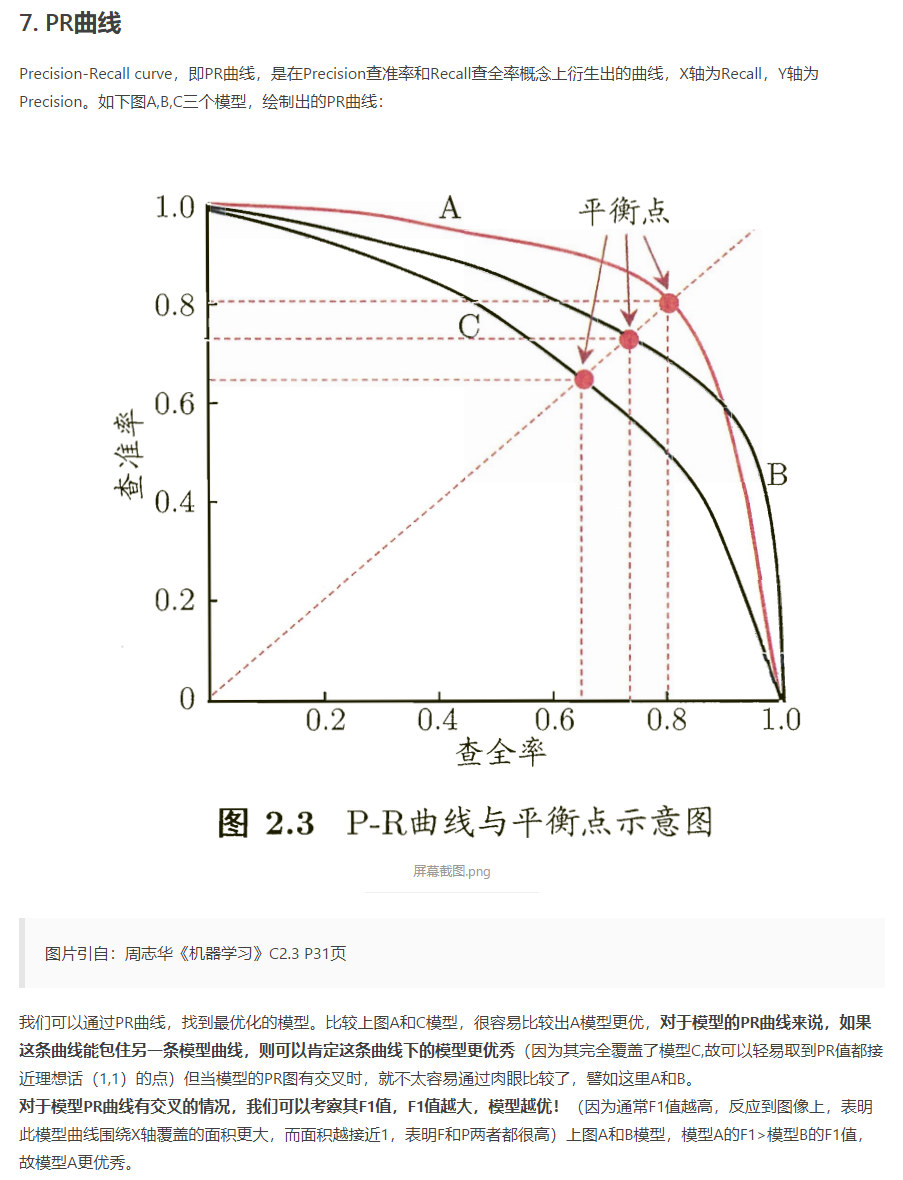
-
ROC 与 AUC
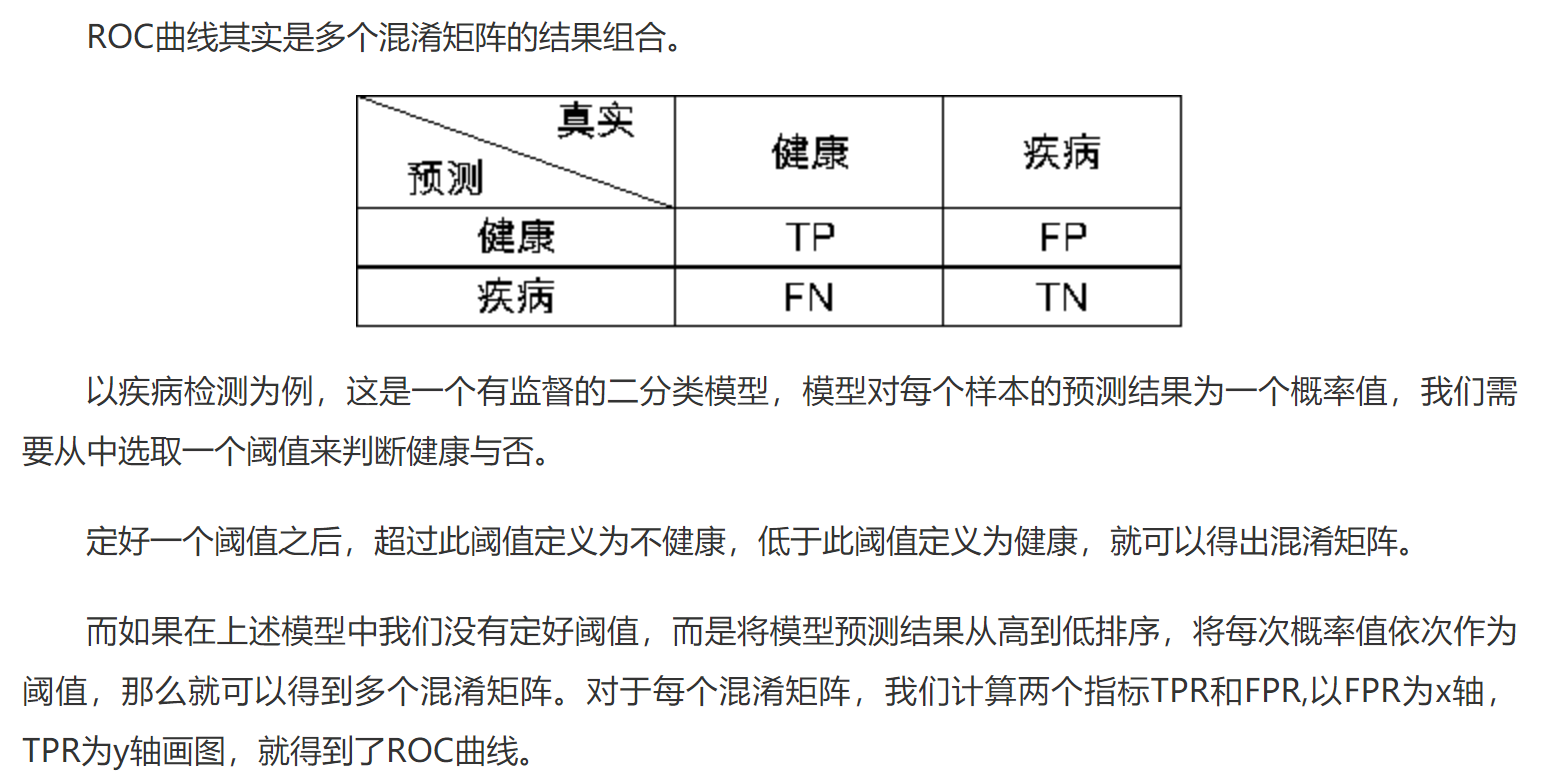 [TPR= frac{TP}{TP+FN} ext{所有阳性样本中,正确预估的概率}\ FPR= frac{FP}{TN+FP} ext{所有阴性样本中,错误预估的概率} ]
[TPR= frac{TP}{TP+FN} ext{所有阳性样本中,正确预估的概率}\ FPR= frac{FP}{TN+FP} ext{所有阴性样本中,错误预估的概率} ]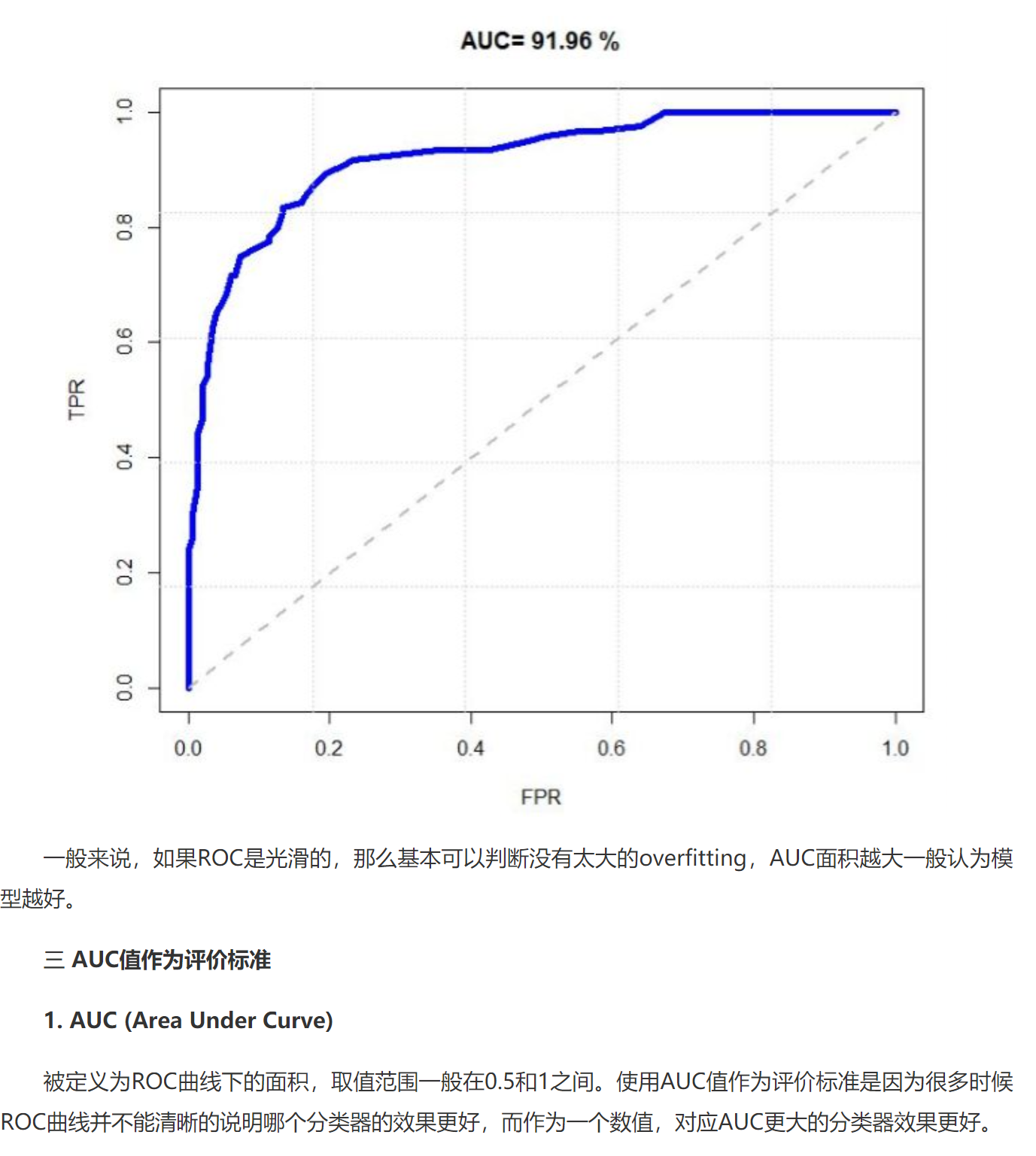
AUC 越高越好
2. 卷积神经网络
计算方式:
原图像 (n*n)
单个卷积核 (f*f)
padding (p)
步长(stride) (s)
结果:
[(lfloorfrac{n+2p-f}{s}+1 floor)*(lfloorfrac{n+2p-f}{s}+1 floor) * 1 ]其中最后一个1表示单个卷积核
三维的情况:

输入图片:(n*n*n_c)
padding:(p=0)
Stride: s = 1
k个卷积核: (f*f*n_c)
结果:
[(n-f+1)*(n-f+1)*k ]单个卷积核只能得到一层,如果要检测多个边缘就应该用多个卷积核。
https://www.cnblogs.com/hejunlin1992/p/7624807.html
3. 目标检测
滑动窗口:基本思路是首选确定一个矩形窗口,然后将这个窗口按照一定的步幅遍历裁剪图片,分别对每一张裁剪得到的图片做图片分类。
缺点:
- 计算成本过大 => 已解决,通过设置与所选矩形窗口同等大小的卷积核,来实现滑动窗口的卷积实现
- 边界框的位置可能不准确

Bounding Box 预测:
- 将原图像划分为(n*n)个小格。
- 对于每一个对象,我们在标注的时候分析出其中点(b_x,b_y),然后将这个对象的中点分配到对应的小格子中。因此一个对象最多被分配到一个小格子中。
- 对于每一个小格子,输出将是一个 (5+K)的向量。([P_c, B_x,B_y,B_w,B_h, .....]) 其中 (K)为类别数量。
如何定义Label?

(b_x,b_y) 是相对于单个小方格的位置。它一定是([0,1])
(b_h,b_w)是相对于单个小方格边长的长度。它可能>1(可能很长,超过单个小方格的边长)
交并比IoU(Intersection over Union):预测的边框和真实的边框的交集和并集的比值。

非极大值抑制:
- 首先去除(P_c)小于某个置信度的bounding box。然后 while true:找到当前的(P_c)最大的bounding box,去除所有与其IoU超过阈值的bounding box。防止一个物体被多次检验。

如果有多种类物体待检验,则应该对每种类别单独进行一次非极大值抑制。
如果一个bounding box内部有多个物品,则应该设置更小的bounding box。
Anchor Boxes:一个格子检测多个对象。其基本思路是,对不同种类的对象设置不同形状的anchor box,对于一个格子,其输出标签不再是[1+4+k],而是 [1+4+k] * number of anchor boxes。在打标时,一个物品具体属于哪一个anchor box,需要根据 IOU计算。
YOLO算法:anchor boxes +
4. RNN & 情感分析
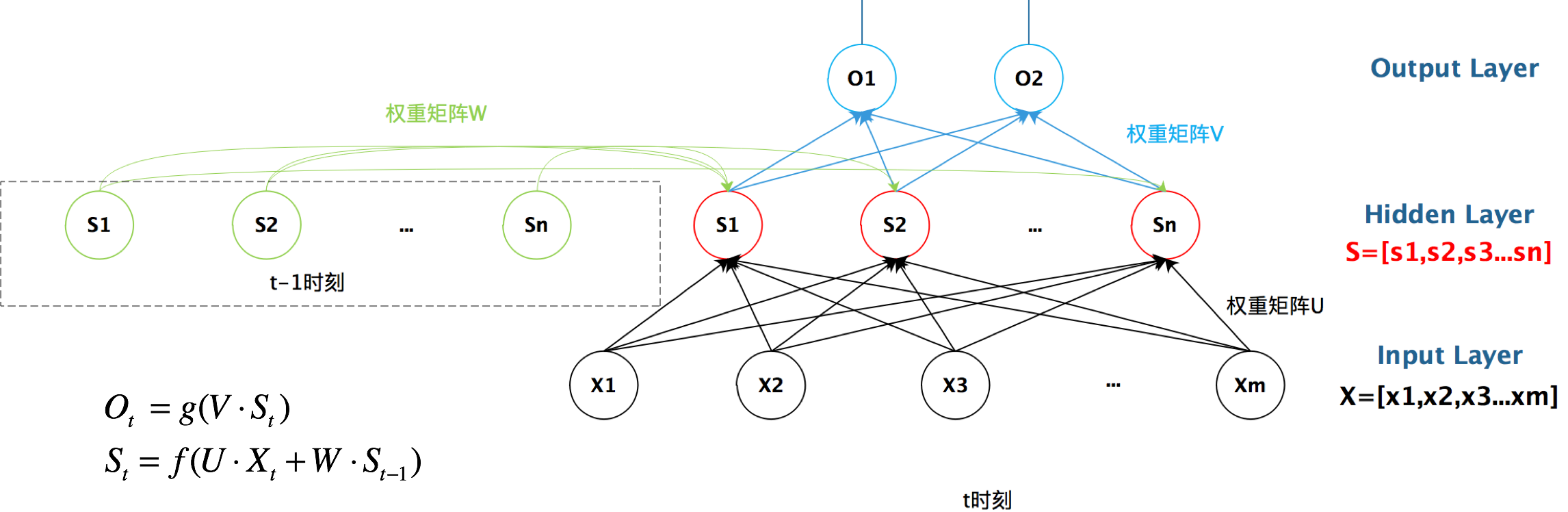
循环神经网络能够提取时间序列的信息,是专门用来处理 时间序列 问题的。
循环神经网络的循环体现在:
(S_t = f(U * X_t + W * S_{t-1}))
(W = S_{t-1})

https://zhuanlan.zhihu.com/p/30844905
RNN在处理序列问题的表现由于传统CNN。这是因为,RNN每一次输入都会参考上一次输入值的信息。
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。

处理情感分析:

5. AE
自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。作为无监督学习模型,自动编码器还可以用于生成与训练样本不同的新数据,这样自动编码器(变分自动编码器,Variational Autoencoders)就是生成式模型。(传统的AE不能作为生成模型)
一个变分自动编码器是一种特殊的自动编码器,它的训练过程加入了正则项,避免训练过程的过拟合并且能确保其隐空间具有良好的能生成新样本的性质。变分自动编码器对数据在隐空间中以某种特定分布进行编码。
6. GAN
训练基本流程:
