进程
什么是进程?
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
进程调度
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
- 先来先服务算法
- 短时间优先调度算法
- 时间片轮转法
- 多级反馈队列
进程的并行与并发
并行 : 并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑;(资源够用,比如三个线程,四核的CPU )
并发 : 并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
同步,异步、阻塞与非阻塞
这张图很关键
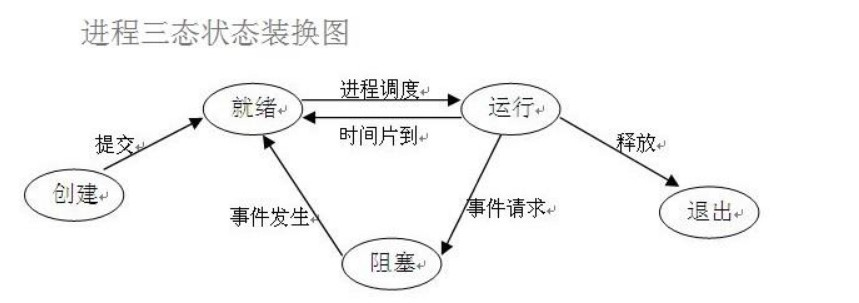

在了解其他概念之前,我们首先要了解进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
(1)就绪(Ready)状态 当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态 当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态 正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
同步与异步
所谓同步:就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。
所谓异步:是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
比如我去银行办理业务,可能会有两种方式:
第一种 :选择排队等候;
第二种 :选择取一个小纸条上面有我的号码,等到排到我这一号时由柜台的人通知我轮到我去办理业务了;
第一种:前者(排队等候)就是同步等待消息通知,也就是我要一直在等待银行办理业务情况;
第二种:后者(等待别人通知)就是异步等待消息通知。在异步消息处理中,等待消息通知者(在这个例子中就是等待办理业务的人)往往注册一个回调机制,在所等待的事件被触发时由触发机制(在这里是柜台的人)通过某种机制(在这里是写在小纸条上的号码,喊号)找到等待该事件的人。
阻塞与非阻塞
阻塞和非阻塞这两个概念与程序(线程)等待消息通知(无所谓同步或者异步)时的状态有关。也就是说阻塞与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的
进程的创建与结束
进程的创建
multiprocess.process模块介绍
1 Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 2 3 强调: 4 1. 需要使用关键字的方式来指定参数 5 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号 6 7 参数介绍: 8 1 group参数未使用,值始终为None 9 2 target表示调用对象,即子进程要执行的任务 10 3 args表示调用对象的位置参数元组,args=(1,2,'egon',) 11 4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} 12 5 name为子进程的名称
实例代码:
1 # 在python进程中开启一个子进程 2 import time 3 from multiprocessing import Process 4 5 6 def f(name): 7 print("hello", name) 8 print("我是子进程") 9 10 11 if __name__ == '__main__': 12 p = Process(target=f, args=("pontoon", )) 13 p.start() 14 time.sleep(1) 15 print("执行主进程的内容了") 16 17 >>>hello pontoon 18 我是子进程 19 执行主进程的内容了
1 import os 2 import time 3 from multiprocessing import Process 4 5 6 def func(): 7 print(54321) 8 time.sleep(1) 9 print("子进程:", os.getpid()) 10 print("子进程的父进程:", os.getppid()) 11 print(12345) 12 13 14 if __name__ == '__main__': 15 p = Process(target=func) 16 p.start() 17 print("*" * 20) 18 print("父进程:", os.getpid()) # 查看当前进程的进程号 19 print("父进程的父进程", os.getppid()) 20 21 22 >>>******************** 23 父进程: 2972 24 父进程的父进程 14060 25 54321 26 子进程: 13992 27 子进程的父进程: 2972 28 12345

多进程中的join()方法
进程中join()方法的用处,感知一个子进程的结束,将异步的程序变成同步的程序,在join()方法调用之前,子进程与主进程都是异步的,但是当调用了join()方法之后,那么下面的代码就变成了同步!
1 import os 2 import time 3 from multiprocessing import Process 4 5 6 def func(): 7 print(54321) 8 time.sleep(1) 9 print("子进程:", os.getpid()) 10 print("子进程的父进程:", os.getppid()) 11 print(12345) 12 13 14 if __name__ == '__main__': 15 p = Process(target=func) 16 p.start() 17 p.join() # 将异步的程序变成同步的 18 print("*" * 20) 19 print("进程结束了") # 查看当前进程的进程号 20 21 22 # 代码似乎这样执行才是正常的,这就是join()方法的作用 23 >>>54321 24 子进程: 10472 25 子进程的父进程: 8692 26 12345 27 ******************** 28 进程结束了
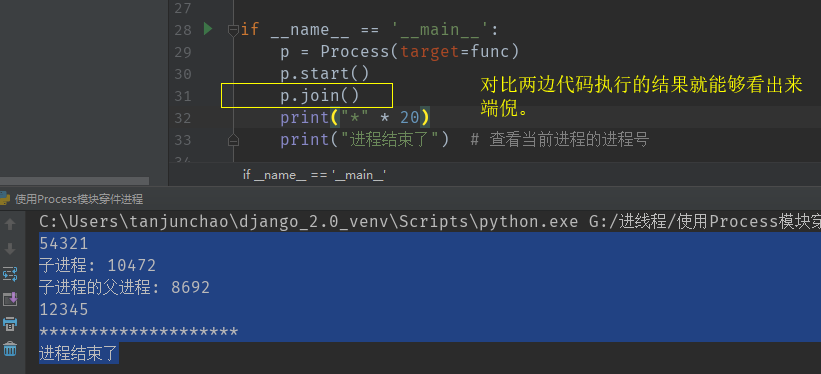
join()方法需要注意的地方


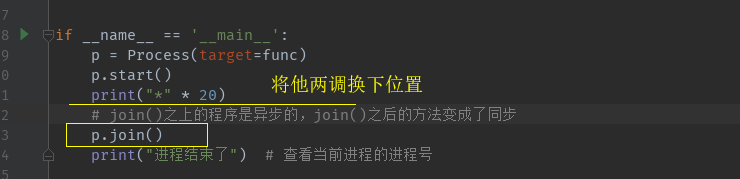

同时开启多个子进程
1 def func(a, b): 2 print(a) 3 time.sleep(3) 4 print(b) 5 6 7 if __name__ == '__main__': 8 p = Process(target=func, args=(10, 20)) 9 p.start() 10 p = Process(target=func, args=(11, 21)) 11 p.start() 12 p = Process(target=func, args=(12, 22)) 13 p.start() 14 p = Process(target=func, args=(13, 23)) 15 p.start() 16 17 print("*" * 20) 18 # join()之上的程序是异步的,join()之后的方法变成了同步 19 p.join() 20 print("进程结束了") # 查看当前进程的进程号 21 22 23 >>>******************** 24 10 25 11 26 12 27 13 28 20 29 21 30 22 31 23 32 进程结束了
使用for循环开启多个子进程
for 循环配合p.join()方法值得注意的地方
1 import os 2 import time 3 from multiprocessing import Process 4 5 6 def func(a, b): 7 print("*" * a) 8 time.sleep(3) 9 print("*" * b) 10 11 12 if __name__ == '__main__': 13 14 for i in range(10): 15 p = Process(target=func, args=(5, 10)) 16 p.start() 17 18 print("*" * 20) 19 # join()之上的程序是异步的,join()之后的方法变成了同步 20 p.join() 21 print("进程结束了") # 查看当前进程的进程号 22 23 >>>***** 24 ***** 25 ***** 26 ***** 27 ***** 28 ***** 29 ***** 30 ******************** 31 ***** 32 ***** 33 ***** 34 ********** 35 ********** 36 ********** 37 ********** 38 ********** 39 ********** 40 ********** 41 ********** 42 进程结束了 # 出问题了 43 ********** 44 **********
1 import time 2 from multiprocessing import Process 3 4 5 def func(a, b): 6 print("*" * a) 7 time.sleep(6) 8 print("*" * b) 9 10 11 if __name__ == '__main__': 12 p_list = [] 13 for i in range(5): 14 p = Process(target=func, args=(5, 10)) 15 p_list.append(p) 16 p.start() 17 [p.join() for p in p_list] 18 print("进程结束了") # 查看当前进程的进程号 19 20 >>>***** 21 ***** 22 ***** 23 ***** 24 ***** 25 ********** 26 ********** 27 ********** 28 ********** 29 ********** 30 进程结束了
[p.join() for p in p_list] 的引用场景
1 # 需求想500个文件里面写数据,用异步的方式实现 2 import os 3 from multiprocessing import Process 4 5 6 def func(file_name, contents): 7 with open(file_name, 'w') as f: 8 f.write(contents * '+') 9 10 11 if __name__ == '__main__': 12 p_list = [] 13 for i in range(5): 14 p = Process(target=func, args=("info{0}".format(i), i)) 15 p_list.append(p) 16 p.start() 17 [p.join() for p in p_list] 18 print([i for i in os.walk(r'G:进线程')])
开启多进程的第二种方式 —— 继承
最简易的
1 import os 2 from multiprocessing import Process 3 4 5 # 开启多进程的第二种方式 6 class MyProcess(Process): 7 def run(self): 8 print(os.getpid()) 9 10 11 if __name__ == '__main__': 12 print("主:", os.getpid()) 13 p1 = MyProcess() 14 p1.start() 15 p2 = MyProcess() 16 p2.start() 17 18 >>>主: 7824 19 12324 20 14660
1 # Process 类中的属性一览 2 3 class Process(object): 4 def __init__(self, group=None, target=None, name=None, args=(), kwargs={}): 5 self.name = '' # 进程名 6 self.daemon = False # 7 self.authkey = None # 8 self.exitcode = None 9 self.ident = 0 10 self.pid = 0 # 进程号 11 self.sentinel = None 12 self.is_alive = '' # 判断子进程是否活着 13 self.terminate = '' # 结束一个子进程
升级,传参数
1 import os 2 from multiprocessing import Process 3 4 5 # 开启多进程的第二种方式 6 class MyProcess(Process): 7 def __init__(self, args1, args2): 8 super(MyProcess, self).__init__() 9 self.arg1 = args1 10 self.arg2 = args2 11 12 def run(self): 13 print(self.pid) 14 print(self.name) 15 print(self.arg1) 16 print(self.arg2) 17 18 19 if __name__ == '__main__': 20 print("主:", os.getpid()) 21 p1 = MyProcess(10, 20) 22 p1.start() 23 p2 = MyProcess(11, 22) 24 p2.start() 25 26 >>>主: 6916 27 9288 28 MyProcess-1 29 10 30 20 31 7412 32 MyProcess-2 33 11 34 22
多进程之间数据是隔离的
-
进程与进程之间数据是隔离的
-
父进程与子进程之间的数据也是隔离的
1 from multiprocessing import Process 2 3 def work(): 4 global n 5 n=0 6 print('子进程内: ',n) 7 8 9 if __name__ == '__main__': 10 n = 100 11 p=Process(target=work) 12 p.start() 13 p.join() # 执行玩子进程之后在执行父进程 14 print('主进程内: ',n) 15 16 >>>子进程内: 0 17 主进程内: 100 18 19 # 在子进程中设置了全局变量但是在主进程中的n的值并没有发生改变,得出结论:主进程与子进程之间的数据也是隔离的
使用socket实现聊天并发
# server端 from socket import * from multiprocessing import Process server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn,client_addr): while True: try: msg=conn.recv(1024) if not msg:break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': #windows下start进程一定要写到这下面 while True: conn,client_addr=server.accept() p=Process(target=talk,args=(conn,client_addr)) p.start()
# client端 from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
守护进程
什么是守护进程?
守护进程是一种新的进程,自己开的一个子进程转换成的。当在一个主进程中开启子进程的时候,想要子进程随着主进程的结束而结束,那么就要将子进程变成一个守护进程。
关键字子进程转换成的,那么该如何转换啦?
先看一个现象,代码如下
import time from multiprocessing import Process # 守护进程 def func(): while 1: time.sleep(0.5) print('2222') if __name__ == '__main__': p = Process(target=func) # p.deamon = True p.start() i = 0 while i < 4: print('11111111') time.sleep(1) i += 1 # 查看输出的结果 >>>11111111 2222 11111111 2222 2222 11111111 2222 2222 11111111 2222 2222 2222 2222 2222 ...
上面的2会一直执行下去。这显然不是我们希望看见的效果,我希望当主进程执行结束之后,子进程也会跟着结束。守护进程就是做这件事的。如何来设置守护进程 。很简单加上一段代码!
1 import time 2 from multiprocessing import Process 3 4 5 # 守护进程 6 def func(): 7 while 1: 8 time.sleep(0.5) 9 print('2222') 10 11 12 if __name__ == '__main__': 13 p = Process(target=func) 14 p.daemon = True # 在start之前加 15 p.start() 16 i = 0 17 while i < 4: 18 print('11111111') 19 time.sleep(1) 20 i += 1 21 22 >>>11111111 23 2222 24 11111111 25 2222 26 2222 27 11111111 28 2222 29 2222 30 11111111 31 2222 32 2222
改进:添加守护进程
1 import time 2 from multiprocessing import Process 3 4 5 def func(): 6 while 1: 7 time.sleep(0.5) 8 print('2222') 9 10 11 if __name__ == '__main__': 12 p = Process(target=func) 13 p.daemon = True # 在start之前加 14 p.start() 15 i = 0 16 while i < 4: 17 print('11111111') 18 time.sleep(1) 19 i += 1 20 21 >>>11111111 22 2222 23 11111111 24 2222 25 2222 26 11111111 27 2222 28 2222 29 11111111 30 2222 31 2222
有上面的现象引出结论:
- 主进程会随着子进程代码的结束而结束(子进程如果是个死循环,那么程序会一致执行下去)
- 守护进程会随着 主进程的代码的执行完毕,而结束。
- p.terminate() 结束一个子进程,并不会立即生效。
进程锁
什么叫做进程锁?
进程锁适用于多进程的程序,就是将异步的程序变成同步的
模拟一个现象来引出锁的概念。
春运到了大家都在抢火车票。100个人抢一张火车票(并发的过程)。但最后只能卖出去一张(心塞~)。
买票的过程用代码来表示就是这样的
#文件db的内容为:{"count":1} #注意一定要用双引号,不然json无法识别 #并发运行,效率高,但竞争写同一文件,数据写入错乱 from multiprocessing import Process,Lock import time,json,random def search(): dic=json.load(open('db')) print('�33[43m剩余票数%s�33[0m' %dic['count']) def get(): dic=json.load(open('db')) time.sleep(0.1) #模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(0.2) #模拟写数据的网络延迟 json.dump(dic,open('db','w')) print('�33[43m购票成功�33[0m') def task(): search() get() if __name__ == '__main__': for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task) p.start()
引出概念为子进程加锁
# 由并发变成了串行,牺牲了运行效率,但避免了竞争 import random from multiprocessing import Process,Lock def func(n, l): l.acquire() time.sleep(random.random()) print("为子线程加锁了%s" % n) l.release() if __name__ == '__main__': l = Lock() for i in range(3): p = Process(target=func, args=(i, l)) p.start() >>>为子线程加锁了0 为子线程加锁了1 为子线程加锁了2 # -------------------------------------------------------------- def func(n): time.sleep(random.random()) print("为子线程加锁了%s" % n) if __name__ == '__main__': for i in range(3): p = Process(target=func, args=(i)) p.start() >>>为子线程加锁了1 为子线程加锁了2 为子线程加锁了0 # 对比两段代码的执行结果——加锁使得子进程变成了‘有序’的状态了
加锁实现春运买票
1 #文件db的内容为:{"count":5} 2 #注意一定要用双引号,不然json无法识别 3 #并发运行,效率高,但竞争写同一文件,数据写入错乱 4 from multiprocessing import Process,Lock 5 import time,json,random 6 def search(): 7 dic=json.load(open('db')) 8 print('�33[43m剩余票数%s�33[0m' %dic['count']) 9 10 def get(): 11 dic=json.load(open('db')) 12 time.sleep(random.random()) #模拟读数据的网络延迟 13 if dic['count'] >0: 14 dic['count']-=1 15 time.sleep(random.random()) #模拟写数据的网络延迟 16 json.dump(dic,open('db','w')) 17 print('�33[32m购票成功�33[0m') 18 else: 19 print('�33[31m购票失败�33[0m') 20 21 def task(lock): 22 search() 23 lock.acquire() 24 get() 25 lock.release() 26 27 if __name__ == '__main__': 28 lock = Lock() 29 for i in range(100): #模拟并发100个客户端抢票 30 p=Process(target=task,args=(lock,)) 31 p.start()
锁的总结
1 #加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 2 虽然可以用文件共享数据实现进程间通信,但问题是: 3 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 4 2.需要自己加锁处理 5 6 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 7 队列和管道都是将数据存放于内存中 8 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 9 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
多进程中的组件
信号量(规定了锁的个数)
互斥锁同时只允许一个线程更改数据,而信号量Semaphore是同时允许一定数量的线程更改数据 。
1 import time 2 import random 3 from multiprocessing import Process 4 from multiprocessing import Semaphore 5 6 7 # 信号量 8 def ktv(i, sem): 9 sem.acquire() # 获取钥匙 10 print('%s走进KTV' % i) 11 time.sleep(random.randint(1, 5)) 12 print('%s走出了KTV' % i) 13 sem.release() 14 15 16 if __name__ == '__main__': 17 sem = Semaphore(4) # 设置4个锁 18 for i in range(20): 19 p = Process(target=ktv, args=(i, sem)) 20 p.start() 21 22 >>>0走进KTV 23 1走进KTV 24 2走进KTV 25 3走进KTV 26 1走出了KTV 27 4走进KTV 28 2走出了KTV 29 6走进KTV 30 0走出了KTV 31 ...
感觉有点意思
事件
1 from multiprocessing import Event 2 3 4 # 一个信号可以使所有的进程都进入阻塞状态,也可以控制所有的进程接触阻塞。 5 # 一个事件被创建之后默认是阻塞状态 6 e = Event() # 创建了一个事件 7 print(e.is_set()) # 查看是否阻塞,默认是阻塞状态的 8 e.set() # 设置阻塞 9 print(e.is_set()) 10 e.wait() # 根据e.is_set()的值决定是否阻塞 11 print("wahaha") 12 e.clear() # 清除阻塞 13 print(e.is_set()) 14 e.wait() 15 print('shuangwaiwai') # 阻塞了就不会在打印了
案例:红绿灯事件
1 from multiprocessing import Event 2 3 4 def cars(e, i): 5 if not e.is_set(): 6 print('car%i在等待' % i) 7 e.wait() 8 print("car%i通过" % i) 9 10 11 # 红绿灯事件 12 def light(e): 13 while True: 14 if e.is_set(): 15 e.clear() 16 print("红灯亮了") 17 else: 18 e.set() 19 print('绿灯亮了') 20 time.sleep(2) 21 22 23 if __name__ == '__main__': 24 e = Event() 25 traffic = Process(target=light, args=(e, )) 26 traffic.start() 27 for i in range(20): 28 car = Process(target=cars, args=(e, i)) 29 car.start() 30 time.sleep(random.random())
进程之间的通信——队列和管道
队列
1 from multiprocessing import Queue, Process 2 3 4 def produce(q): 5 q.put("hello") # 向对列中放入数据 6 7 8 def consume(q): 9 print(q.get()) # 向队列中取数据 10 11 12 if __name__ == '__main__': 13 q = Queue() 14 p = Process(target=produce, args=(q,)) 15 p.start() 16 c = Process(target=consume, args=(q, )) 17 c.start()
生产者消费者模型
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
1 from multiprocessing import Process, Queue 2 import random 3 import time 4 5 6 def consumer(q, name): 7 # 定义消费者 8 while True: 9 food = q.get() 10 if food is None: 11 print("%s获取到了一个空" % name) 12 break 13 print("%s消费了%s" % (name, food)) 14 time.sleep(random.randint(1, 3)) 15 16 17 def produce(name, food, q): 18 # 定义生产者 19 for i in range(10): 20 time.sleep(random.randint(1, 3)) 21 f = "{0}生产了{1}{2}".format(name, food, i) 22 print(f) 23 q.put(f) 24 25 26 if __name__ == '__main__': 27 q = Queue(10) 28 p1 = Process(target=produce, args=("lee", "包子", q)) 29 p2 = Process(target=produce, args=("dan", "泔水", q)) 30 c1 = Process(target=consumer, args=(q, 'pon')) 31 c2 = Process(target=consumer, args=(q, 'toon')) 32 p1.start() 33 p2.start() 34 c1.start() 35 c2.start() 36 p1.join() 37 p2.join() 38 q.put(None) 39 q.put(None)
使用JoinableQueue改进代码
1 # 升级版 2 from multiprocessing import Process, JoinableQueue 3 import random 4 import time 5 6 7 def consumer(q, name): 8 while True: 9 food = q.get() 10 print("%s消费了%s" % (name, food)) 11 time.sleep(random.randint(1, 3)) 12 q.task_done() # 使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。 13 14 15 def produce(name, food, q): 16 # 定义生产者 17 for i in range(10): 18 time.sleep(random.randint(1, 3)) 19 f = "{0}生产了{1}{2}".format(name, food, i) 20 print(f) 21 q.put(f) 22 q.join() # 当队列中所有的包子都被消费玩了,程序执行完 23 24 25 if __name__ == '__main__': 26 q = JoinableQueue(20) 27 p1 = Process(target=produce, args=("lee", "包子", q)) 28 p2 = Process(target=produce, args=("dan", "泔水", q)) 29 c1 = Process(target=consumer, args=(q, 'pon')) 30 c2 = Process(target=consumer, args=(q, 'toon')) 31 p1.start() 32 p2.start() 33 c1.daemon = True # 创建一个守护进程 循环的案例中,随着主进程的结束,子进程也会跟着结束 所以他的作用是判断 主进程是否结束 34 c2.daemon = True # 创建一个守护进程 循环的案例中,随着主进程的结束,子进程也会跟着结束 35 c1.start() 36 c2.start() 37 p1.join() # join执行完,那么主进程就执行完 38 p2.join() # join执行完,那么主进程就执行完
管道
管道是什么?
Linux进程间通信方式的一种,管道有两端,读端和写端。创建管道,然后从父进程fork出子进程,
父进程和子进程拥有共同的读写文件描述符,可以实现子进程写文件,父进程读文件的操作。
1 # 管道 2 from multiprocessing import Pipe, Process 3 4 5 def func(conn1, conn2): 6 conn2.close() 7 while True: 8 try: 9 msg = conn1.recv() 10 print(msg) 11 except EOFError: 12 conn1.close() 13 break 14 15 16 if __name__ == '__main__': 17 conn1, conn2 = Pipe() 18 Process(target=func, args=(conn1, conn2)).start() 19 conn1.close() 20 for i in range(20): 21 conn2.send("吃了么") 22 conn2.close()
进程之间的数据共享Manager模块

1 from multiprocessing import Manager, Process 2 3 4 def main(dic): 5 dic['count'] -= 1 6 print(dic) 7 8 9 if __name__ == '__main__': 10 m = Manager() 11 dic = m.dict({'count': 100}) 12 p_lst = [] 13 p = Process(target=main, args=(dic, )) 14 p.start() 15 p.join() 16 print('主线程:', dic) 17 18 19 >>>{'count': 99} 20 主线程: {'count': 99}
上面的做到了数据共享,but:
1 from multiprocessing import Manager, Process 2 3 4 def main(dic): 5 dic['count'] -= 1 6 7 8 if __name__ == '__main__': 9 m = Manager() 10 dic = m.dict({'count': 100}) 11 p_list = [] 12 for i in range(30): 13 p = Process(target=main, args=(dic,)) 14 p.start() 15 p_list.append(p) 16 for i in p_list: p.join() 17 print('主程序', dic) 18 19 >>>主程序 {'count': 70}
1 from multiprocessing import Manager, Process, Lock 2 3 4 def main(dic, lock): 5 lock.acquire() 6 dic['count'] -= 1 7 lock.release() 8 9 10 if __name__ == '__main__': 11 m = Manager() 12 lock = Lock() 13 dic = m.dict({'count': 100}) 14 p_list = [] 15 for i in range(30): 16 p = Process(target=main, args=(dic, lock)) 17 p.start() 18 p_list.append(p) 19 for i in p_list: p.join() 20 print('主程序', dic) 21 22 >>>主程序 {'count': 70}


好 这个时候来一波总结
进程池
什么是进程池?为什么要用进程池?
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
1 # 进程池 2 import time 3 from multiprocessing import Pool, Process 4 5 6 def func(n): 7 for i in range(5): 8 print(n+1) 9 10 11 if __name__ == '__main__': 12 start = time.time() 13 pool = Pool(5) 14 pool.map(func, range(100)) 15 t1 = time.time() - start 16 17 start = time.time() 18 p_List = [] 19 for i in range(100): 20 p = Process(target=func, args=(i, )) 21 p_List.append(p) 22 p.start() 23 for p in p_List: 24 p.join() 25 t2 = time.time() - start 26 print(t1, t2) 27 28 29 >>>0.22115707397460938 6.861854076385498 # 差距是相当的明显


1 import os, time 2 from multiprocessing import Pool 3 4 5 def func(n): 6 print('start func%s' % n, os.getpid()) 7 time.sleep(3) # 模拟代码执行 8 print('end func%s' % n, os.getpid()) 9 10 11 if __name__ == '__main__': 12 p = Pool(5) 13 for i in range(10): 14 p.apply_async(func, args=(i, )) 15 p.close() # 结束进程池接收任务 16 p.join() # 感知进程池中的任务执行结束 17 18 >>>start func0 17124 19 start func1 14436 20 start func2 8872 21 start func3 7396 22 start func4 1268 23 end func0 17124 24 start func5 17124 25 end func1 14436 26 start func6 14436 27 end func2 8872 28 start func7 8872 29 end func3 7396 30 start func8 7396 31 end func4 1268 32 start func9 1268 33 end func5 17124 34 end func6 14436 35 end func7 8872 36 end func8 7396 37 end func9 1268
实现一个基于进程池的TCP
1 # 基于进程池的tcp 2 # client 端 3 import socket 4 5 6 sk = socket.socket() 7 sk.connect(('127.0.0.1', 8080)) 8 9 ret = sk.recv(1024).decode('utf-8') 10 print(ret) 11 msg = input('>>>').encode('utf-8') 12 sk.send(msg) 13 sk.close()
1 # server 端 2 import socket 3 4 5 sk = socket.socket() 6 sk.bind(('127.0.0.1', 8080)) 7 sk.listen() 8 while True: 9 conn, addr = sk.accept() 10 conn.send(b'hello') 11 print(conn.recv(1024).decode('utf-8')) 12 conn.close() 13 sk.close()

1 # server 端 2 import socket 3 from multiprocessing import Pool 4 5 6 def func(conn): 7 conn.send(b'hello') 8 print(conn.recv(1024).decode('utf-8')) 9 conn.close() 10 11 12 if __name__ == '__main__': 13 p = Pool(5) 14 sk = socket.socket() 15 sk.bind(('127.0.0.1', 8080)) 16 sk.listen() 17 while True: 18 conn, addr = sk.accept() 19 p.apply_async(func, args=(conn, )) 20 sk.close()
进程池的返回值
1 # 进程池的返回值 2 from multiprocessing import Pool 3 def func(i): 4 return i*i 5 6 7 if __name__ == '__main__': 8 p = Pool(5) 9 ret_list = [] 10 for i in range(10): 11 ret = p.apply_async(func, args=(i, )) 12 # print(ret) 得到的是对象 13 ret_list.append(ret) 14 for ret in ret_list: print(ret.get()) # 等着func的计算结果 15 16 >>>0 17 1 18 4 19 9 20 16 21 25 22 36 23 49 24 64 25 81
进程池的回调函数
1 # 进程池的回调函数 2 from multiprocessing import Pool 3 4 5 def func1(i): 6 print('in func1') 7 return i*i 8 9 def func2(n): 10 print('in func2' ) 11 print(n) 12 13 14 if __name__ == '__main__': 15 p = Pool(5) 16 p.apply_async(func1, args=(10, ), callback=func2) 17 p.close() 18 p.join() 19 20 >>>in func1 21 in func2 22 100
进程池的执行位置
1 # 进程池的回调函数 2 import os 3 from multiprocessing import Pool 4 5 6 def func1(i): 7 print('in func1', os.getpid()) 8 return i*i 9 10 11 def func2(n): 12 print('in func2', os.getpid()) 13 print(n) 14 15 16 if __name__ == '__main__': 17 print('主进程:', os.getpid()) 18 p = Pool(5) 19 p.apply_async(func1, args=(10, ), callback=func2) # 注意这里回调函数的执行位置,实在主进程中执行的 20 p.close() 21 p.join() 22 23 >>>主进程: 13732 24 in func1 5292 25 in func2 13732 26 100