前言
前面已经介绍了Android平台下两种解析XML的方法,SAX和PULL,这两个均为事件驱动,以流的形式解析XML文档。现在介绍一种新的方式DOM方式解析XML。
DOM是一种用于XML文档对象模型,可用于直接访问XML文档的各个部位,在DOM中文档被模拟成树状,其中XML语法的每一组成部分都表示一个节点,DOM允许用户遍历文档树,从父节点移动到子节点和兄弟节点。并利用某节点类型特有的属性(元素具有属性,文本节点具有文本数据)。
对于DOM而言,XML文档中每一个成分都是一个节点。
DOM是这样规定的:
- 整个文档是一个文档节点。
- 每一个XML标签是一个元素节点。
- 包含在XML元素中的文本是一个文本节点。
- 每一个XML属性是一个属性节点。
DOM解析XML
DOM解析XML也是需要一个工厂类DocumentBuilderFactory,这一点和SAX、PULL类似。工厂类也是单例模式,没有提供共有的构造函数,需要使用静态的newInstance()方法获得,并且需要工厂类来获取DOM解析器实例,使用DocumentBuilderFactory.newDocumentBuilder()获得的DocumentBuilder对象。
当获得Document之后,就可以使用parse()解析XML文档,parser多个重载,可以适用于不同的输入。
下面介绍一下在DOM解析XML过程中,会碰上几个对象,Element、NodeList、Node。说也不太好说清楚,画个图解释一下更直观。

从图上可以看出,Element为一个元素,可以通过这个元素获取到该元素的属性值(Attribute),以及它的子节点的集合NodeList。而NodeList作为一个装载平级节点的集合,可以通过NodeList获得它内装载的所有平级节点,可以通过索引获取。对于Node,表示最终的节点,根据图示说的,其实Jack文本也是一个文本节点(Node),Node可以获取其节点名称、其值、其属性。所以它们三个是可以相互嵌套的,也不存在说谁一定要在谁的外侧或是内层。
示例程序
既然已经说了那么多了,现在通过一个示例程序展示一下DOM解析XML。这是一个Android应用程序,为了模拟真实的环境,通过网络读取IIS上的一个静态XML文件内容。直接上代码,注释已经写的很清楚了。
IIS上的静态XML文档内容:
1 <?xml version="1.0" encoding="utf-8" ?> 2 - <persons> 3 - <person id="23"> 4 <name>Jack</name> 5 <age>21</age> 6 </person> 7 - <person id="20"> 8 <name>Dick</name> 9 <age>23</age> 10 </person> 11 </persons>
DomService,解析网络传输来的XML文档流:
package cn.bgxt.service; import java.io.InputStream; import java.util.ArrayList; import java.util.List; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import cn.bgxt.domain.Person; public class DomService { public DomService() { // TODO Auto-generated constructor stub } public static List<Person> getPersons(InputStream inputStream) throws Exception { List<Person> list=new ArrayList<Person>(); //获取工厂对象,以及通过DOM工厂对象获取DOMBuilder对象 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder=factory.newDocumentBuilder(); //解析XML输入流,得到Document对象,表示一个XML文档 Document document=builder.parse(inputStream); //获得文档中的次以及节点,persons Element element=document.getDocumentElement(); // 获取Element下一级的person节点集合,以NodeList的形式存放。 NodeList personNodes=element.getElementsByTagName("person"); for(int i=0;i<personNodes.getLength();i++) { //循环获取索引为i的person节点 Element personElement=(Element) personNodes.item(i); Person person=new Person(); //通过属性名,获取节点的属性id person.setId(Integer.parseInt(personElement.getAttribute("id"))); //获取索引i的person节点下的子节点集合 NodeList childNodes=personElement.getChildNodes(); for(int j=0;j<childNodes.getLength();j++) { //循环遍历每个person下的子节点,如果判断节点类型是ELEMENT_NODE,就可以依据节点名称给予解析 if(childNodes.item(j).getNodeType()==Node.ELEMENT_NODE) { if("name".equals(childNodes.item(j).getNodeName())) { //因为文本也是一个文本节点, //所以这里读取到name节点的时候, //通过getFirstChild()可以直接获得name节点的下的第一个节点,就是name节点后的文本节点 //取其value值,就是文本的内容 person.setName(childNodes.item(j).getFirstChild().getNodeValue()); } else if("age".equals(childNodes.item(j).getNodeName())) { person.setAge(Integer.parseInt(childNodes.item(j).getFirstChild().getNodeValue())); } } } //把解析的person对象加入的list集合中 list.add(person); } return list; } }
从IIS服务器上获取XML的方式,在另外一篇博客:HTTP协议。中已经介绍了,如果不明白可以去看看,这里就不介绍了。
Activity的布局就是一个按钮,用于点击出发解析事件,因为是Android4.0+的环境,需要无法在主线程中访问网络,需要使用到多线程的技术,并且不要网了给Android应用增加访问网络的权限。
1 package cn.bgxt.xmlfordom; 2 3 import java.io.InputStream; 4 import java.util.List; 5 import cn.bgxt.domain.Person; 6 import cn.bgxt.http.HttpUtils; 7 import cn.bgxt.service.DomService; 8 import android.os.Bundle; 9 import android.app.Activity; 10 import android.util.Log; 11 import android.view.Menu; 12 import android.view.View; 13 import android.widget.Button; 14 15 public class MainActivity extends Activity { 16 17 private Button button; 18 19 @Override 20 protected void onCreate(Bundle savedInstanceState) { 21 super.onCreate(savedInstanceState); 22 setContentView(R.layout.activity_main); 23 24 button=(Button)findViewById(R.id.btn); 25 button.setOnClickListener(new View.OnClickListener() { 26 27 @Override 28 public void onClick(View v) { 29 // Android 4.0+不能在主线程中访问网络 30 Thread thread=new Thread(new Runnable() { 31 @Override 32 public void run() { 33 try { 34 String path="http://192.168.1.107:1231/persons.xml"; 35 InputStream inputStream=HttpUtils.getXML(path); 36 List<Person> list=DomService.getPersons(inputStream); 37 for(Person person:list) 38 { 39 //以日志的形式打印对象内容 40 Log.i("DOM", person.toString()); 41 } 42 } catch (Exception e) { 43 // TODO: handle exception 44 } 45 } 46 47 }); 48 thread.start(); 49 } 50 51 }); 52 53 54 } 55 56 }
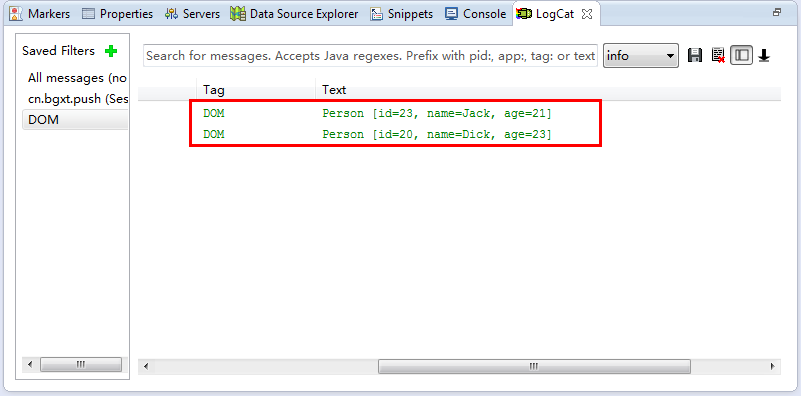
如果解析成功,可以在LogCat中查看到日志。
总结
现在已经讲解的常用的Android应用中解析XML的方法,DOM和PULL、SAX不一样,是文档模型形式的,在解析的时候会把整个XML的内容都读取到内存中,这样对于移动设备而言,是很消耗内存的。而PULL以及SAX都是事件驱动,逐行去解析XML的内容,相对而言保证了解析速度又不会很损耗内存。所以Android应用中一般不推荐使用DOM解析XML,还是偏向于使用SAX、PULL。但是DOM也有它的优点,正因为它是把整个文档都读取到内存中了,可以指定需要查找的数据而无需遍历所有的节点,对于内容比较少的XML而言,还是很方便的。所以解析XML的方法有很多,无法绝对的说明谁好谁坏,主要还是看需求设定的环境来取舍的。
请支持原创,尊重原创,转载请注明出处。谢谢。
