1.将hive目录下面的jdbc的jar包 复制这个jar文件到Kettle的lib目录下E:kettle7.0data-integrationlib
[datalink@slave3 jdbc]$ sz hive-jdbc-3.1.2-standalone.jar
rz
zmodem trl+C ȡ
100% 70722 KB 3367 KB/s 00:00:21 0 Errorssone.jar...
2.修改plugin.properties文件(D:data-integrationpluginspentaho-big-data-plugin)
active.hadoop.configuration=hadoop312 ---可以忽略
3.kettle中添加hive的db连接
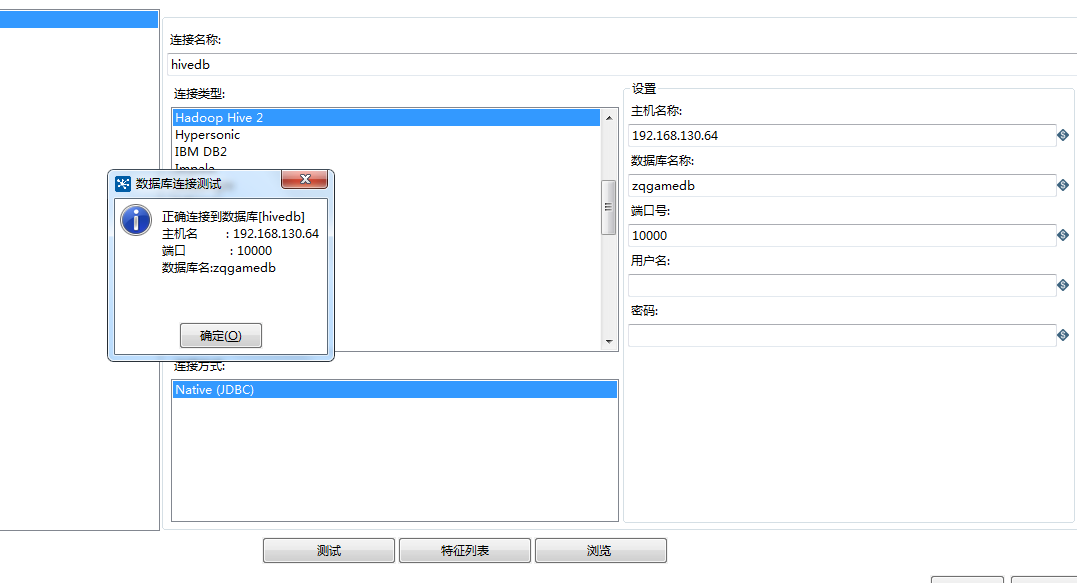
kettle对big data的支持还是有限,在关系型数据库之间进行集成推荐使用,简单方便。当然还有特别好用的就是各种数据清洗、数据过滤、数据转换任务。
sqoop用来迁移关系型到非关系型数据库,用于数据仓库的数据集成工作。
针对hive上的查询,kettle可以进行的很快,但是针对hive上插入,就变的十分慢。还只针对特定版本