普通的一致性哈希(consistent hashing)是这样,在哈希环上为client顺时针选取最近一个server:
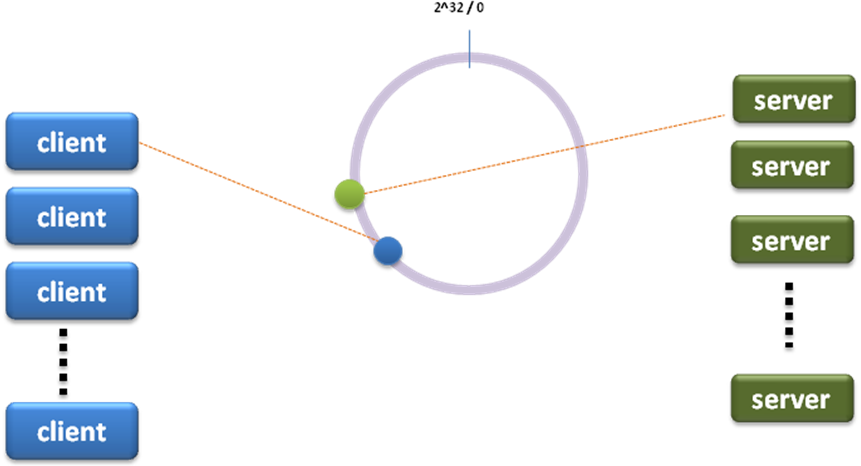
在某个paper上看到一种变形,具体哪个paper忘了,它是这么做的,就是选取前后两个server,每个client对应两个server,而不是一个:
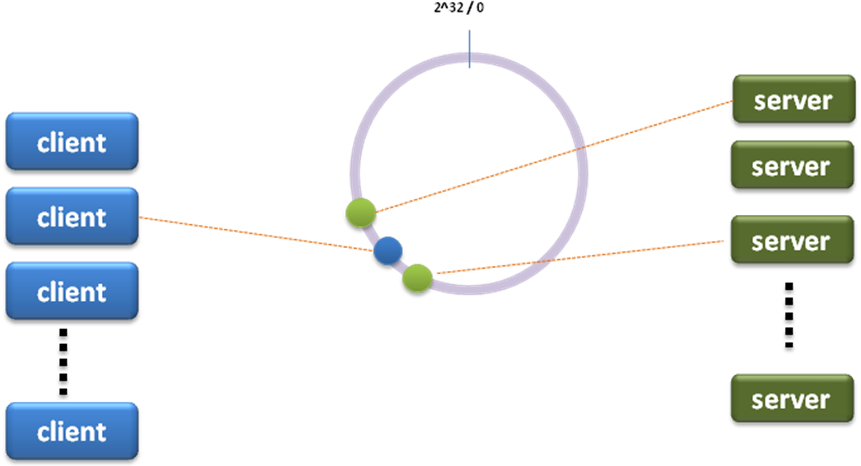
为了写代码方便,最后实现的是这种:
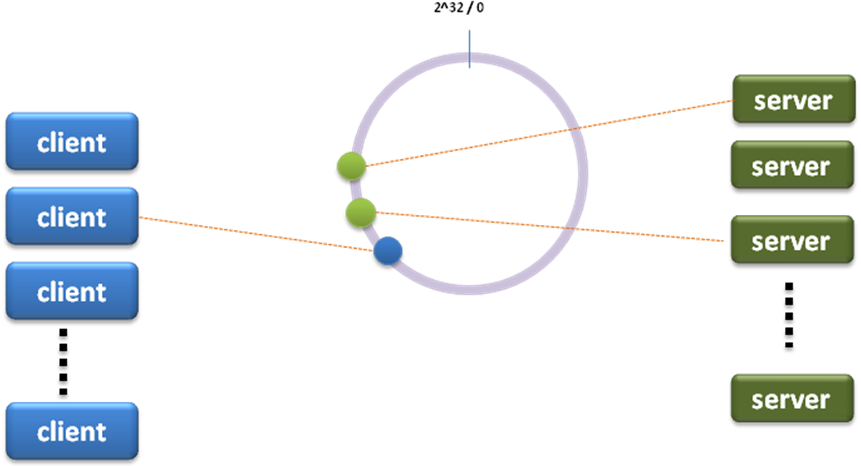
为一个client配两个server,是为了提高可用性,万一连一个连不上,可以连第二个。
一开始还担心分布不均衡,不过试了一下,最后效果还比较满意,挺均衡的。
用了之后明显感受到以下好处:
- 多个独立进程可以得到相同的哈希结果。
- server的CPU负载更轻,因为缓存命中率高了。
- server对后端存储压力减小,减少很多重复读取。
- 定位问题更容易,因为可以确定client上的东西 会分布到哪两个server上。
有一点注意的是,最好不要使用随机生成的ID作为key哈希,而使用相对比较固定的,比如IP,或者IP+端口这些。可以让集群的数据和负载分布保持稳定。不然,随机生成的ID一变,可能就会有比较大的波动,造成负载高或是对后端存储压力高。
文章来源:http://blog.csdn.net/yanghehong/article/details/6171503