阿里电面问到了相关的知识,在网上找到这方面的文章。
这几个关键字是查询递归数据的,形成一个树状结构。目前只有oracle支持,其他数据都要结合存储过程实现
语法:
select * from some_table
[where 条件1]
connect by [条件2]
start with [条件3];
其中 connect by 与 start with 语句摆放的先后顺序不影响查询的结果,[where 条件1]可以不需要。
[where 条件1]、[条件2]、[条件3]各自作用的范围都不相同:
[where 条件1]是在根据“connect by [条件2] start with [条件3]”选择出来的记录中进行过滤,是针对单条记录的过滤, 不会考虑树的结构;
[条件2]指定构造树的条件,以及对树分支的过滤条件,在这里执行的过滤会把符合条件的记录及其下的所有子节点都过滤掉;
[条件3]限定作为搜索起始点的条件,如果是自上而下的搜索则是限定作为根节点的条件,如果是自下而上的搜索则是限定作为叶子节点的条件;
看下面的例子
TEST
| EMPNO | ENAME | DPT | MAR | SAL |
| 0075 | XU | D1 | 0082 | 3000 |
| 0082 | BAO | D1 | 0096 | 4000 |
| 0096 | ZHAO | D2 | NULL | 5000 |
| 0111 | MU | D2 | 0082 | 4000 |
| 0056 | ZHANG | D3 | 0111 | 3000 |
| 0923 | WANG | D3 | 0075 | 2000 |
select* from test start with EMPNO = '0111' connect by EMPNO = prior MAR
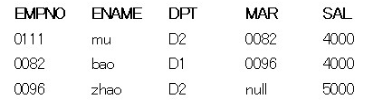
select* from test start with EMPNO = '0111' connect by prior EMPNO = MAR

对prior的说明:
prior存在于[条件2]中,可以不要,不要的时候只能查找到符合“start with [条件3]”的记录,不会在寻找这些记录的子节点。
要的时候有两种写法:connect by prior empno=mgr 或 connect by empno=prior mgr,
前一种写法表示采用自上而下的搜索方式(先找父节点然后找子节点),
后一种写法表示采用自下而上的搜索方式(先找叶子节点然后找父节点)。
[执行原理] :
遍历表中的每条记录,对比是否满足start with后的条件,如果不满足则继续下一条, 如果满足则以该记录为根节点.
然后递归寻找该节点下的子节点, 查找条件是connect by后面指定的条件,比如上面的例子,是当前记录的empno等于其子节点的mgr,如此循环直到遍历完整个表的所有记录.
如果数据有问题,出现循环,即a是b的经理,b是c的经理,c又是a的经理,查询会出现ORA-01436: 用户数据中的 CONNECT BY 循环 的错误,可在connect by后面添加nocycle 解决这个问题。