实验一、词法分析实验
专业 :商业软件工程 姓名:许锦沛 学号:201506110238
一.实验目的
设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
二.实验内容和要求
实验内容:
1.语言的单词符号:
(1) 关键字:begin if then while do end (所有关键字都是小写的)
(2) 标识符:表示各种名字,如变量名,数组名,函数名等,如char ch, int syn, token, sum等。
(3) 常数:如123, 4587等。
(4) 运算符:如+,—,*,/,:=,<=,>,< >等。
(5) 界符: () : ; ,等。
2.词法分析的主要任务:
(1)I :对字符串表示的源程序。
(2)P :从左到右进行扫描和分解(根据词法规则)。
(3)O :识别出一个一个具有独特意义的单词符号(以供词法分析之用)。
(4)E :发现词法错误,则返回出错误信息,如-1。
3.各种单词符号对应的种别码:
表1 各种单词符号对应的种别码
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
bgin |
1 |
: |
17 |
|
If |
2 |
:= |
18 |
|
Then |
3 |
< |
20 |
|
wile |
4 |
<> |
21 |
|
do |
5 |
<= |
22 |
|
end |
6 |
> |
23 |
|
10 |
>= |
24 |
|
|
11 |
= |
25 |
|
|
+ |
13 |
; |
26 |
|
— |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
实验要求:
1.输入:源程序字符串。
2.输出:二元组(种别,单词本身)。
3.其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
三 . 实验方法、步骤及结果测试
1.源程序名:简单词法分析.c
可执行程序名:简单词法分析.exe
2.原理分析及流程图
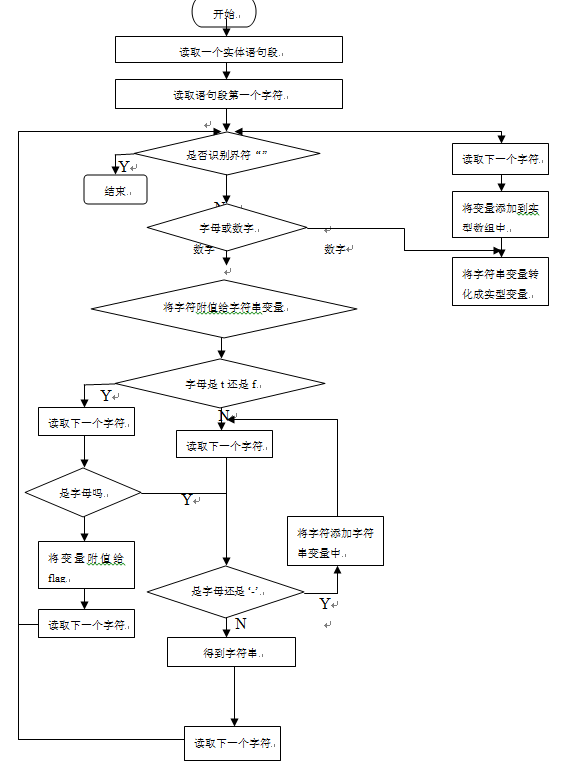
1.主要程序段及其解释:
10 void scaner() 11 { 12 /* 13 共分为三大块,分别是标示符、数字、符号,对应下面的 if else if 和 else 14 15 16 */ 17 for(n=0;n<8;n++) token[n]=NULL; 18 ch=prog[p++]; 19 while(ch==' ') 20 { 21 ch=prog[p]; 22 p++; 23 } 24 if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) //可能是标示符或者变量名 25 { 26 m=0; 27 while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) 28 { 29 token[m++]=ch; 30 ch=prog[p++]; 31 } 32 token[m++]='\0'; 33 p--; 34 syn=10; 35 for(n=0;n<6;n++) //将识别出来的字符和已定义的标示符作比较, 36 if(strcmp(token,rwtab[n])==0) 37 { 38 syn=n+1; 39 break; 40 } 41 } 42 else if((ch>='0'&&ch<='9')) //数字 43 { 44 { 45 sum=0; 46 while((ch>='0'&&ch<='9')) 47 { 48 sum=sum*10+ch-'0'; 49 ch=prog[p++]; 50 } 51 } 52 p--; 53 syn=11; 54 if(sum>32767) 55 syn=-1; 56 } 57 else switch(ch) //其他字符 58 { 59 case'<':m=0;token[m++]=ch; 60 ch=prog[p++]; 61 if(ch=='>') 62 { 63 syn=21; 64 token[m++]=ch; 65 } 66 else if(ch=='=') 67 { 68 syn=22; 69 token[m++]=ch; 70 } 71 else 72 { 73 syn=23; 74 p--; 75 } 76 break; 77 case'>':m=0;token[m++]=ch; 78 ch=prog[p++]; 79 if(ch=='=') 80 { 81 syn=24; 82 token[m++]=ch; 83 } 84 else 85 { 86 syn=20; 87 p--; 88 } 89 break; 90 case':':m=0;token[m++]=ch; 91 ch=prog[p++]; 92 if(ch=='=') 93 { 94 syn=18; 95 token[m++]=ch; 96 } 97 else 98 { 99 syn=17; 100 p--; 101 } 102 break; 103 case'*':syn=13;token[0]=ch;break; 104 case'/':syn=14;token[0]=ch;break; 105 case'+':syn=15;token[0]=ch;break; 106 case'-':syn=16;token[0]=ch;break; 107 case'=':syn=25;token[0]=ch;break; 108 case';':syn=26;token[0]=ch;break; 109 case'(':syn=27;token[0]=ch;break; 110 case')':syn=28;token[0]=ch;break; 111 case'#':syn=0;token[0]=ch;break; 112 case'\n':syn=-2;break; 113 default: syn=-1;break; 114 } 115 }
4.运行结果及分析
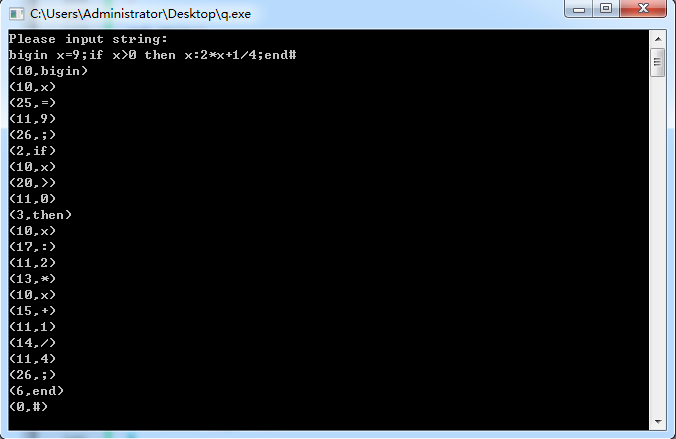
1).测试例子为;begin x=9;
If x>0 then x:2*x+1/4; end#
2).测试结果如下图所示;
四.实验总结
在这次的实验中,了解词法分析的操作过程以及编译原理中的一些词法规则,解决如何将程序代码转化为字符串等相关问题。但是,第一次接触编译原理,对编译原理的词法分析器还是不了解。比如说syn为单词种别码;token为存放的单词自身字符串等问题都不清楚。希望今后多加练习,提高自我编译水平。