一、Series
pd.Series(data=None, index=None, dtype=None): 用于创建一个一维的带“轴标签”的ndarray数组
data:可以是列表,字典,标量值,numpy创建的一维数组
index:data的“标签”,默认从0开始分配,index长度和data的长度要相同;如果data为字典并且给定index,则index会取代字典的key,成为value的标签;默认标签和给定标签共存。
import pandas as pd import numpy as np
#列表创建 a1 = pd.Series([1,2,3], index=['a','b','c']) print(a1) #标量值创建 a2 = pd.Series(10, index=list('12345')) print(a2) #字典创建 a3 = pd.Series({'a':1, 'b':2, 'c':3}) print(a3) a4 = pd.Series({'a':1, 'b':2, 'c':3}, index=['e','b','a']) #index自动与dict的key匹配 print(a4) #numpy创建 a5 = pd.Series(np.arange(1,5), index=np.arange(1,5)) print(a5)
常用属性:
index:返回数组的标签
values:返回数组的值
name:返回Series的名称,也可以用来修改Series的名称
size:返回数组的元素数
常用方法:
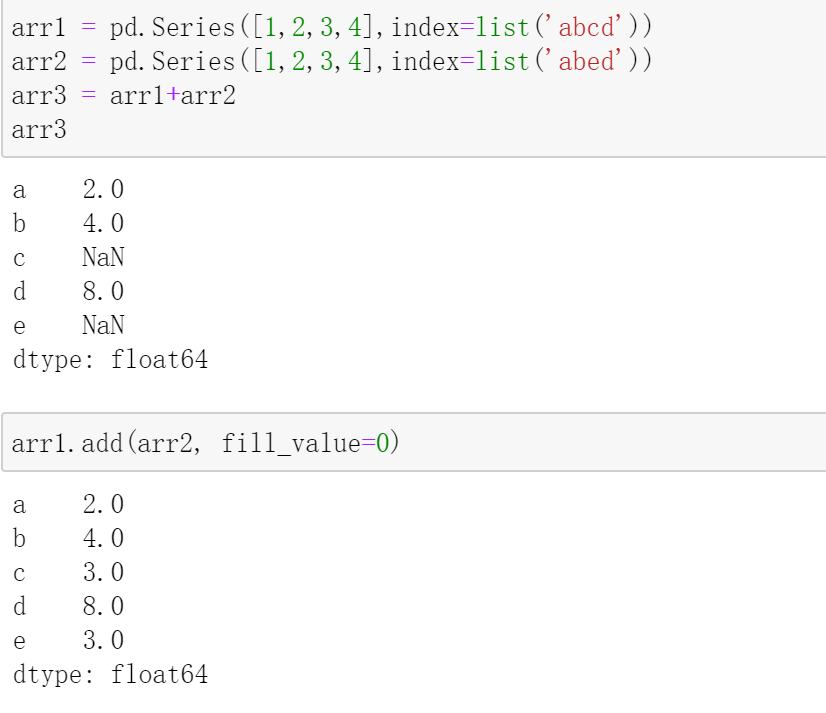
pd.Series.add(self, other, fill_value=None)
标签相同的相加,标签不同返回NaN;如果给定fill_value,则缺失值填充为fill_value
pd.Series.copy(self, deep=True)
数组的拷贝,默认为深拷贝。
import pandas as pd import numpy as np a = pd.Series(np.arange(1,5), index=list('abcd')) b = a.copy() c = a.copy(deep=False) a['a'] = 10 print(a) #10, 2, 3, 4 print(b) #1, 2, 3, 4 print(c) #10, 2, 3, 4
pd.Series.get(self, key, default=None)
获取数组中key对应的值(例如:DataFrame的column),如果未找到,则返回默认值
索引与切片:当给定index时,既可以通过给定的index索引,又可以通过默认的index索引;可以通过自定义索引列表进行切片
import pandas as pd a = pd.Series([1,2,3], index=list('abd')) #DataFrame上不能这样索引 print(a[0]) #1 print(a['a']) #1 #下面两种方法都可用于切片 print(a['a':'d']) print(a[['a','b','d']])
pd.Series.unique() 返回唯一值
pd.Series.value_counts(self, normalize=False, sort=True, ascending=True, bins=None, dropna=True): 返回各个元素的个数。normalize为True时,统计每个元素的占比;bins为整数时,根据整数值将数组离散化为该整数个段;dropna为False时,会统计数组中NaN的个数
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False): 用于创建一个带“行标签”和“列标签”的表格型的数据类型
data:可以是ndarray;元组、列表、字典等可迭代对象
index:行标签,如果没有定义或者data没有提供,则默认从0开始
columns:列标签,如果没有定义,则默认从0开始
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(1,10).reshape(3,3), columns=list('abc')) print(df) # 从字典创建 d1 = {'one':[1,2,3], 'two':[4,5,6]} df1 = pd.DataFrame(d1, index=list('abc')) print(df1)
# 改变列索引
df2 = pd.DataFrame(d1, columns=['two', 'one'])
print(df2)
把DataFrame变为列表形式的一种方法:
import numpy as np import pandas as pd frame = pd.DataFrame(np.arange(12).reshape(3,4), columns=list('abcd')) frame_to_list1 = frame.values.tolist() frame_to_list2 = frame['a'].tolist() print(frame_to_list1) #[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]] print(frame_to_list2) #[0, 4, 8]
常用属性:
index:返回行标签
columns:返回列标签
values:返回数组中元素的值
shape:返回DataFrame的形状
size:返回ndarray数组中元素的个数
at:通过标签访问单个元素
iat:通过整数位置访问单个元素

iloc: 通过整数位置访问DataFrame某几行或某个数据
loc:通过标签或布尔数组访问DataFrame的数据
import numpy as np import pandas as pd frame = pd.DataFrame(np.arange(12).reshape(3,4), index=list('abc'), columns=['num','name','sex','age']) #单个标签 print(frame.loc['a']) #行和列的多个标签 print(frame.loc[['a','b'],['num','name']]) #行和列的单标签,输出对应的单个元素 print(frame.loc['a','num']) #行切片,切片的开始和结束都包含在里面 print(frame.loc['a':'c']) print(frame['a':])
#布尔列表 [[]]返回一个DataFrame print(frame.loc[[False,True,True]]) #按条件筛选 print(frame[frame.age>4].iloc[:, :3]) print(frame[frame['age']>4].iloc[:, :3]) #DataFrame要获取某行的数据要用iloc或者loc,不能直接用行标签; 筛选某列可以直接标签索引 frame[['num']] 或者 frame.num

加入新的一列:
import pandas as pd dict = {'one':[1,2,3], 'two':[4,5,6]} df1 = pd.DataFrame(dict, index=['a','b','c']) col = pd.Series([7,8,9], index=df1.index) df1['three'] = col print(df1)
常用方法:
pd.DataFrame.drop(labels=None, axis=0, index=None, columns=None):删除指定的行或列标签
返回被被删除行或列的DataFrame,原数据不变
import pandas as pd import numpy as np frame = pd.DataFrame(np.arange(12).reshape(3,4),
index=list('123'),columns=list('abcd')) #删掉a,b两列 print(frame.drop(['a','b'],axis=1)) #删掉1,2两行 print(frame.drop(index=['1','2']))
#永久删除某列
del frame['d']
print(frame.columns)
pd.DataFrame.reindex():重新排列索引或者加入新定义的索引
reindex(self, labels=None, index=None, column=None, axis=None, method=None, copy=True, fill_value=nan)
indexcolumns:新的行列的自定义索引
fill_value:新的行列的填充值
import pandas as pd import numpy as np frame = pd.DataFrame(np.arange(12).reshape(3,4),index=list('123'),columns=list('abcd')) #重新排列行索引 print(frame.reindex(index=list('321'))) #加入新的索引列 newc = frame.columns.insert(3,'e') print(frame.reindex(columns=newc,fill_value='20')) #创建一个新索引 new_index = ['0','2','3'] print(frame.reindex(new_index))
pd.DataFrame.head():返回前n行数据,默认为5行
算术运算(索引对应运算):
add(self, other, axis='columns', level=None, fill_value=None):加法运算
sub(self, other, axis='columns', level=None, fill_value=None):减法运算
div(self, other, axis='columns', level=None, fill_value=None):除法运算
mul(self, other, axis='columns', level=None, fill_value=None):乘法运算
import pandas as pd import numpy as np frame1 = pd.DataFrame(np.arange(12).reshape(3,4)) print(frame1) frame2 = pd.DataFrame(np.arange(9).reshape(3,3)) print(frame2) #frame1与frame2对应相加,不对应的地方与填充值相加,没有填充值数据丢失 print(frame1.add(frame2, fill_value=100)) series = pd.Series(np.arange(3)) print(series) #默认frame1的每一行加上series print(frame1.add(series)) #frame1的每一列减去series print(frame1.sub(series,axis=0))
pd.DataFrame.append(self, other, ignore_index=False):把一个DataFrame加到另一个DataFrame的末尾,返回一个新的对象
import pandas as pd import numpy as np frame1 = pd.DataFrame(np.arange(6).reshape(3,2)) frame2 = pd.DataFrame(np.arange(4).reshape(2,2)) print(frame1.append(frame2)) #放弃原来的索引,行索引从0开始
print(frame1.append(frame2, ignore_index=True))
info():打印DataFrame的简要信息
where():当给定条件成立时,保持原始值;当给定条件不成立时,用给定值替换条件不成立处的值

corr(self, method='pearson', min_periods=1):计算列的成对相关性,不包括NA和空值
sort_values(by, axis=0, ascending=True):对数值进行排序。by是某一列的标签或者某几列标签组成的列表
sort_index(axis=0, ascending=True):对标签进行排序
映射操作
apply(func, axis=0):将DataFrame的每个元素交由func处理
map():是Series的一种方法;可以映射新的一列
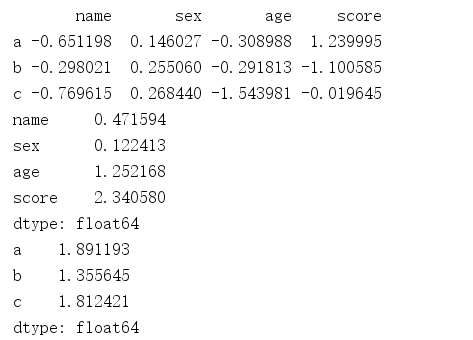
import numpy as np import pandas as pd frame = pd.DataFrame(np.random.randn(3,4), index=list('abc'), columns=['name','sex','age','score']) print(frame) frame1 = frame.apply(lambda x: x.max()-x.min()) # axis=0 按行操作,从上往下 print(frame1) frame2 = frame.apply((lambda x: x.max()-x.min()), axis=1) # 注意:axis=1代表列,这里是对一行的每一列进行处理 print(frame2)
#Series.map(arg) import numpy as np import pandas as pd frame = pd.DataFrame(np.random.randn(3,4), index=list('abc'), columns=['name','sex','age','score']) print(frame) frame1 = frame['score'].map(lambda x: '%.2f'%x) print(frame1) print(type(frame['name'])) # Series print(type(frame[['name']])) # DataFrame
分组操作
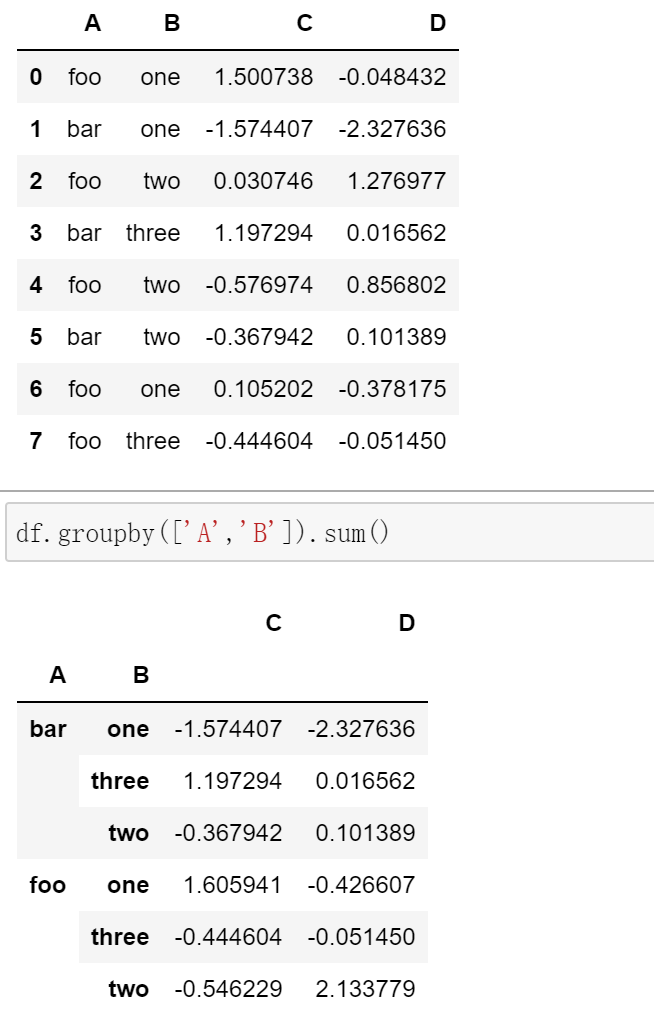
groupby(by=None, axis=0): 对数据按要求进行分组,然后可以进行数值操作,使用groups查看分组情况
缺失值处理:
python的 None 与 NaN
None是python object,不能参与计算
np.nan是浮点类型,可以参与计算,但结果总是nan
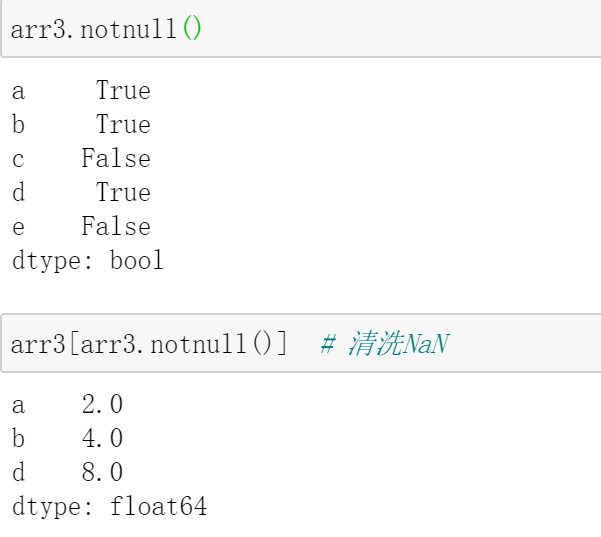
pd.DataFrame.isnull(obj):检查缺失值,返回布尔值 (结合any进行检测)
pd.DataFrame.notnull(obj):检查非缺失值 (结合all进行检测)
pd.DataFrame.dropna(axis=0, how='any'):删除缺失值,axis可以是{0, ‘index’, 1, 'columns'};how可以是{‘any’, 'all'},all表示如果整行或整列值是缺失值,则删除这行或列;any表示行或列中有缺失值,则删除这行或列

pd.DataFrame.fillna(value='None', method='None', axis='None'):用某种方法(‘backfill’, ‘bfill’ // ‘pad’, ‘ffill’)填补缺失值;value要是scalar、dict、Series、DataFame,不能是list
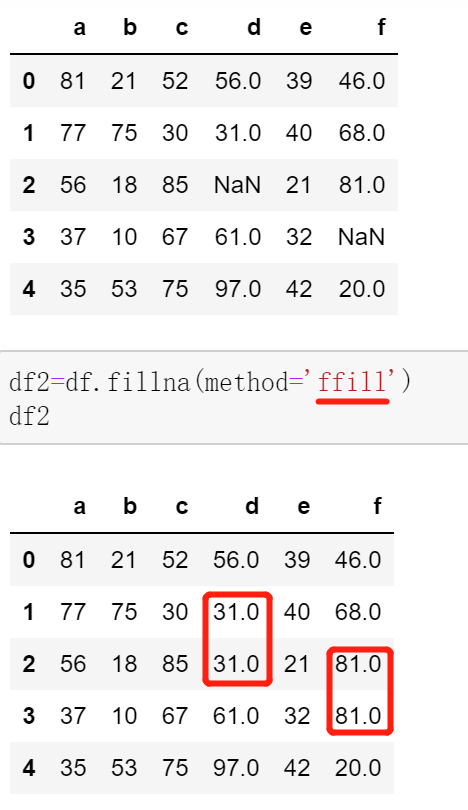
按条件清洗

pd.DataFrame.replace(to_replace='None',value='None'):用value的值去取代to_replace的值;to_replace可以是numeric、list、dict
拼接操作:
pd.concat(objs, axis=0, keys='None', names='None', ignore_index='False')

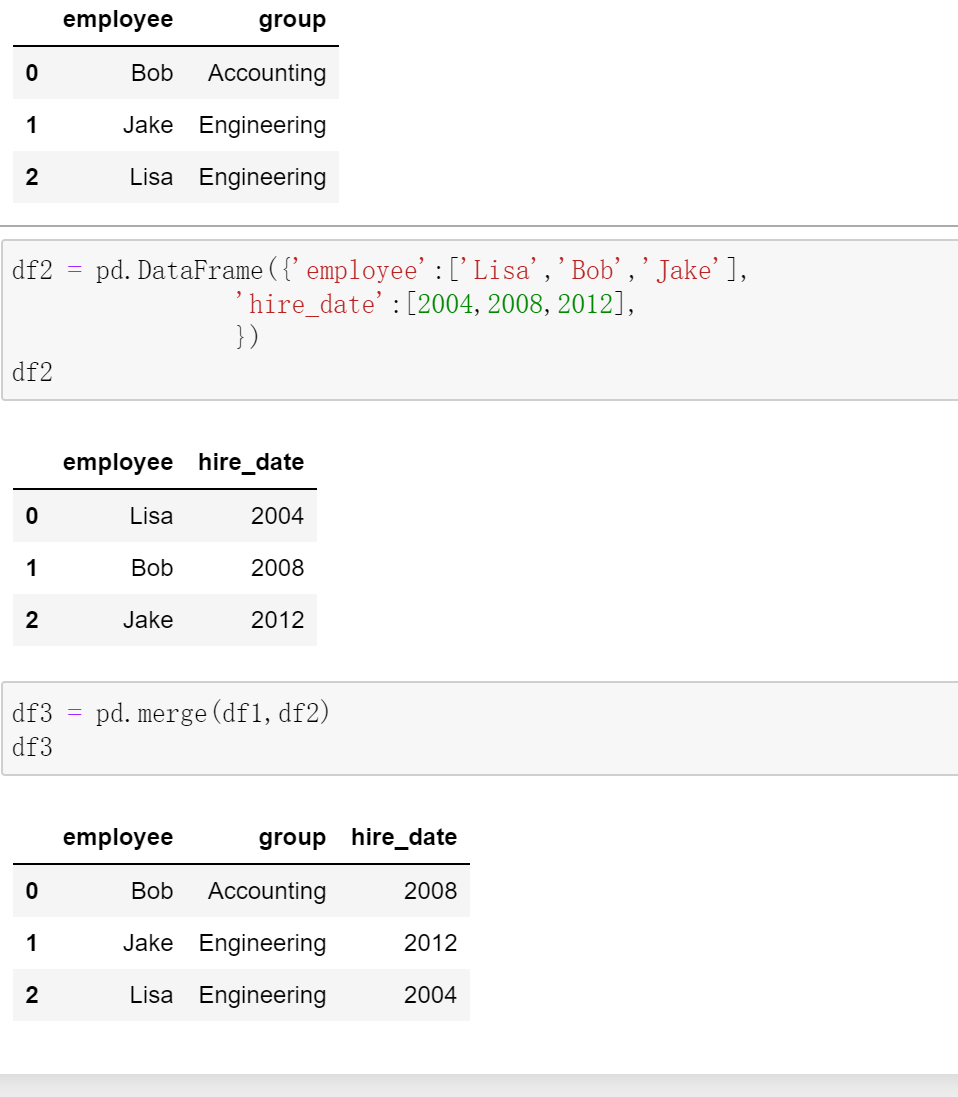
pd.merge(left, right, how='inner', on=None) 合并要有共同的列,或者用left_on和right_on,how='outer' 进行合并
left: DataFrame
right: DataFrame or Series
how: {‘left’, ‘right’, ‘outer’, ‘inner’} 连接条件:outer可以连接两张表所有数据,保证完整性; left保留左表的数据完整
on 指定合并条件,例如 on=‘group‘ 则是按两表的group合并; 还有left_on 和 right_on,按这两列中的元素进行合并
按条件查询
pd.DataFrame.query(expr) expr为字符串形式的条件表达式

对行或者列改变位置
pd.DataFrame.take(indices, axis=0) indices是一个整数标签数组