神经网络经常加入weight decay来防止过拟合,optimizer使用SGD时我们所说的weight decay通常指L2 weight decay,即,加在loss中的L2正则项。
L2正则项在Michael Nielsen的Neural Networks and Deep Learning的第三章第2节有比较详细的介绍,下面就直接从书里截图过来:
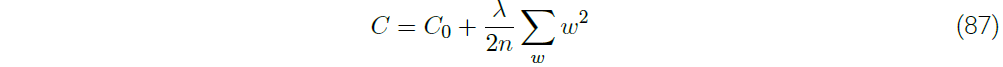


神经网络经常加入weight decay来防止过拟合,optimizer使用SGD时我们所说的weight decay通常指L2 weight decay,即,加在loss中的L2正则项。
L2正则项在Michael Nielsen的Neural Networks and Deep Learning的第三章第2节有比较详细的介绍,下面就直接从书里截图过来: