本文作者:友盟+技术专家 刘章军
前言:App推送在日常运营场景中经常用到,如:资讯类的新闻及时下发、生活服务类优惠券精准推送、 电商类的货品状态或是促销优惠等,通常开发者会根据运营的需求通过自建消息推送通道或使用第三方消息推送平台实现,但自建消息推送的开发成本和人力成本非常高, 很多App开发者选择第三方消息推送。今天就以友盟+消息推送U-Push,详细解读在海量业务背景下如何保证服务的稳定性以及功能丰富的触达服务。
1. 业务背景
友盟+消息推送U-Push日均消息下发量百亿级,其中筛选任务日均数十万,筛选设备每分钟峰值可达7亿+,本文将分享友盟+技术架构团队在长期生产实践中沉淀的筛选架构解决方案。
如何保证百亿级的下发量?
友盟+U-Push筛选是Push产品的核心功能,其中实时筛选是面向推送要求较高的付费Pro用户提供的核心能力之一,实现了用户实时打标、筛选、分发、触达的功能。友盟+U-Push的设备识别以device_token为基准,为保证尽可能的触达我们留存了近期所有可能触达客户的device_token,以10亿真实设备为例,每个设备安装10个集成友盟+SDK的应用可以产生10个device_token,牵扯到硬件环境变动导致的device_token漂移问题,可能产生更多device_token。
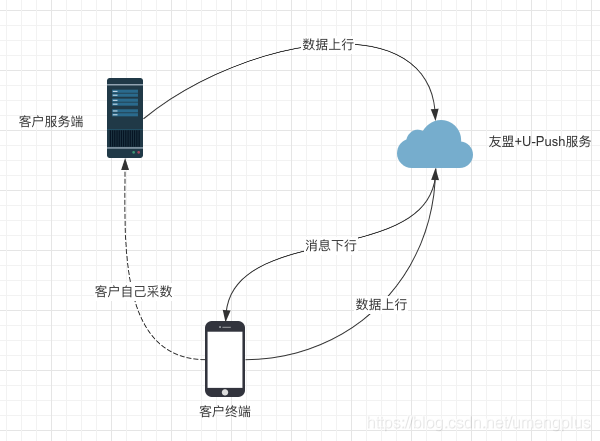
( 图1.1.1 友盟+U-Push业务数据流简图)
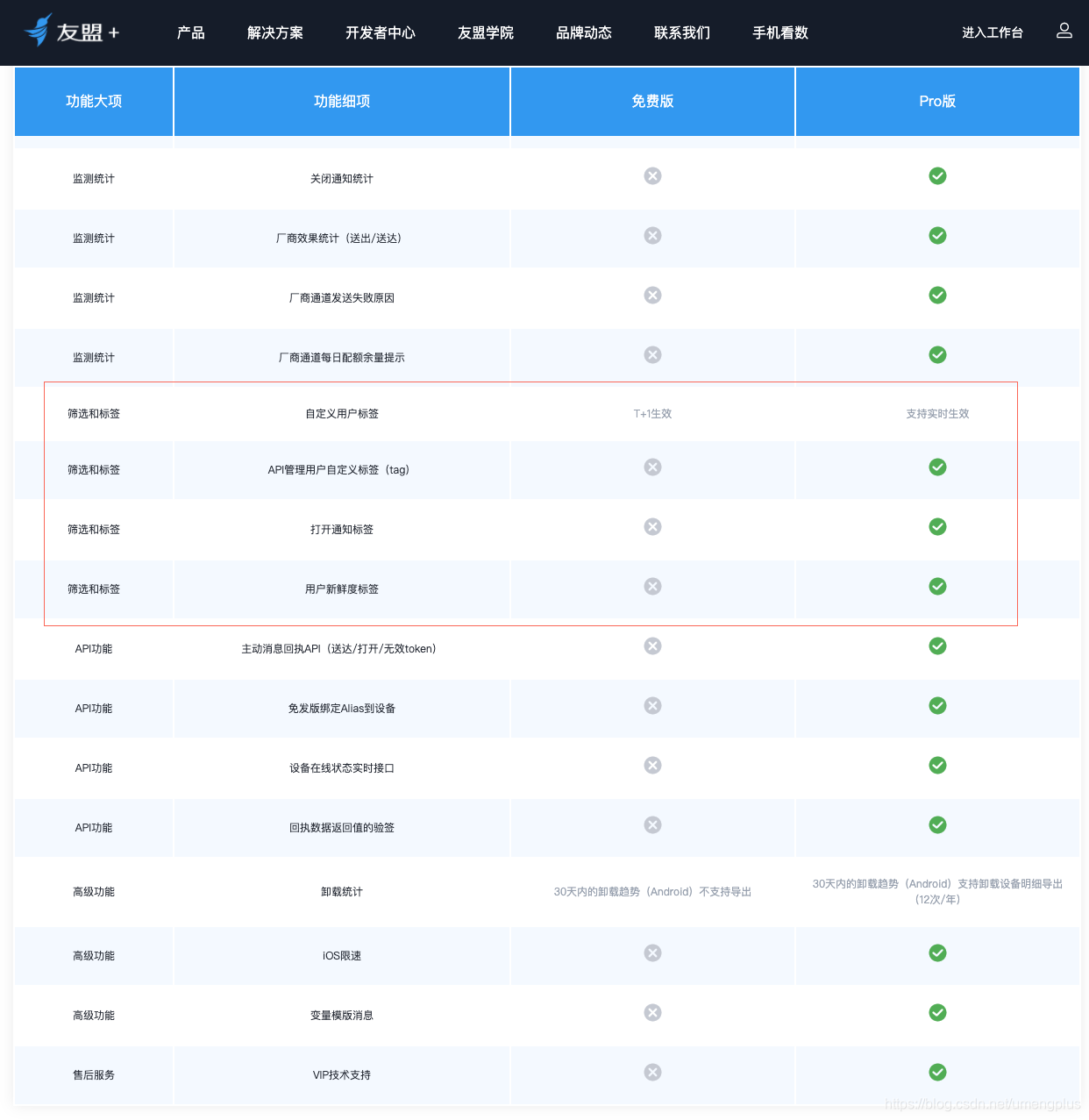
图1.1.2 友盟+U-Push功能清单
2. U-Push筛选架构概览
2.1 上下行两个核心链路
U-Push服务由两个关键链路组成,下行链路保证客户消息的触达,上行链路承载终端采数和与客户服务端的数据同步。其中下行链路主要分为任务调度、筛选中心,上行链路主要服务是多种收数通道(为兼容历史问题)和设备中心,上行通过设备中心实现跟下行桥接。
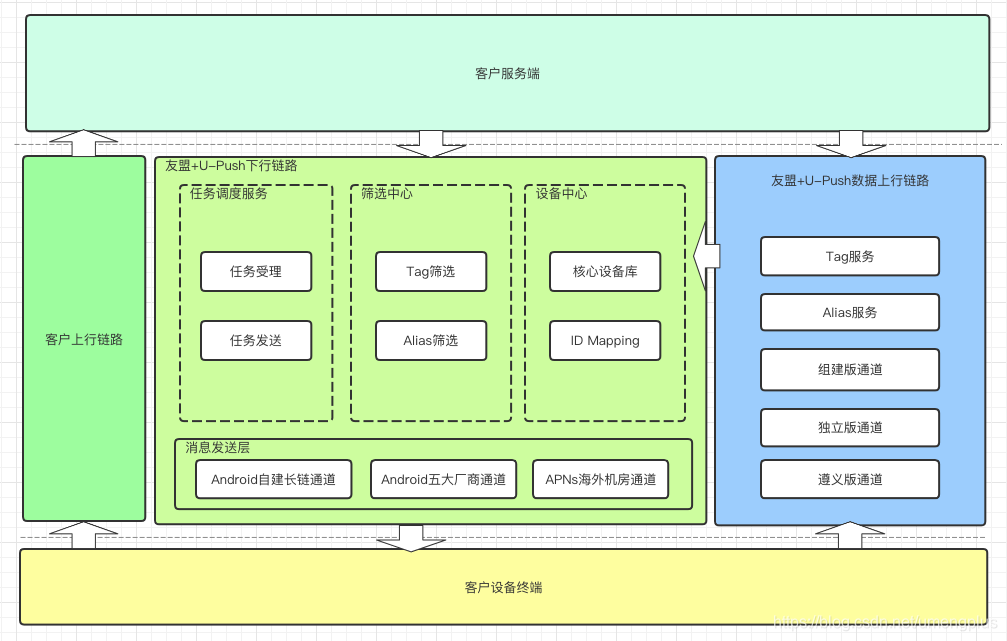
图2.1.1 友盟+U-Push筛选业务场景
在U-Push服务中,依照业务场景不同定义了多种任务类型,其中除单播、列播直接下发外组播、广播、自定义播、自定义文件播均需要通过筛选服务处理后才可执行下发,下行链路中(如图2.1.2)优先级最高是的任务受理和任务发送流程(红色链路),即无论发生什么情况都要保证客户消息的正确下发,是U-Push服务稳定性的底线。出于融灾考虑,筛选服务在架构上与主链路解耦。
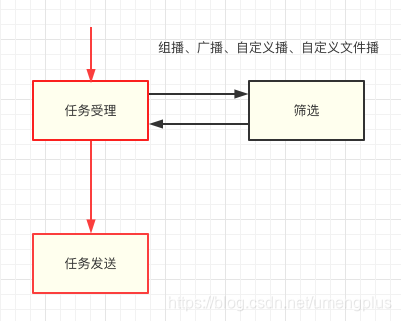
图2.1.2 筛选和核心链路隔离
2.2 数据架构目标和设计
提到筛选,其本质是通过建立合理的标签索引系统实现数据的快速定位。筛选的目标是U-Push核心设备库,但是为避免筛选请求影响到核心库稳定需要将待筛选集合分库冗余存储,与一般OLAP,OLTP场景不同,U-Push筛选的应用场景更加苛刻。
1. 不俗的在线任务并发能力
筛选本质还是在线场景,具有一定的并发能力,并发压力主要在于压榨系统IO上,通过合理的中间件使用、严谨的服务调度、针对性场景的差异化设计降低单次筛选的执行时间,提高并发。
2. 实时海量数据分析和传输能力
筛选提供了多种分析维度(图2.2.2),支持灵活的语法组合。筛选服务不仅要满足对海量数据的实时查询分析,还要支持对单次可能破亿的结果集做低成本传输。

图2.2.2 筛选支持的字段类型
3. 成本可控
一切问题都是成本问题,从行业看全民上云后服务架构的成本问题更是备受关注,尤其在友盟+庞大的业务量下成本问题更加重要。
4. 为下游任务并行发送创造条件
友盟+U-Push的发送层集群用于大量的发送节点,最理想的设计就是在任务筛选阶段即完成数据切片、分发、调度,下游直接并行发送以达到最高效率。
U-Push筛选在持续的技术迭代中,和多领域专业团队深度合作,充分利用不同组件的特性,通过整合Tair、AnalyticDB for MySQL(ADS)、OSS、MaxCompute(ODPS)、Lindorm、HBase、SchedulerX等产出了一套兼顾稳定、性能、和成本的均衡解决方案。
筛选分为离线和实时两部分,离线通过ODPS生成设备主库快照,导入ADS。实时通过消费数据上行服务的设备信息更新事件,实时更新ADS或者RDB库。在执行筛选时候,对于较大结果集通过upload或者dump到OSS的方式输出多个小文件,传输给发送链路下游执行并行发送。
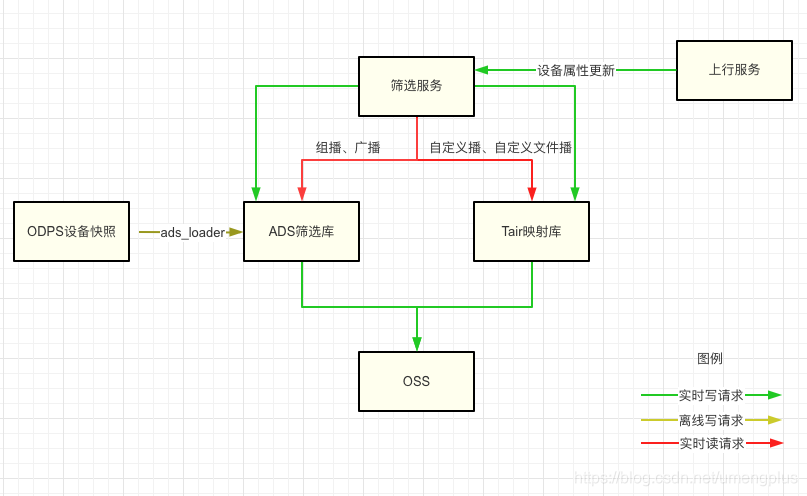
图2.2.4 筛选服务数据流向
上述业务链路和数据结构介绍了筛选目前的整体设计,但是要应付复杂的客情和多变的业务场景还需要做更多细节设计。
3. 设计细节
3.1 筛选库的场景设计
从上面的概览可以看出,筛选架构中的主要矛盾就是消息下行链路中海量数据的读和上行链路中设备属性更新的高频写的矛盾,解决这个矛盾需要大量的资源来保证数据一致性和性能,在常规的设计思路中在目前的成本资源下几乎是不可行。大数据三大宝,冷热分离分库分表,通过业务分析调研,U-Push将业务分成若干场景,基于客户的不同生命周期的业务诉求和服务能力将客户指向不同场景,尽量优化客户体验。
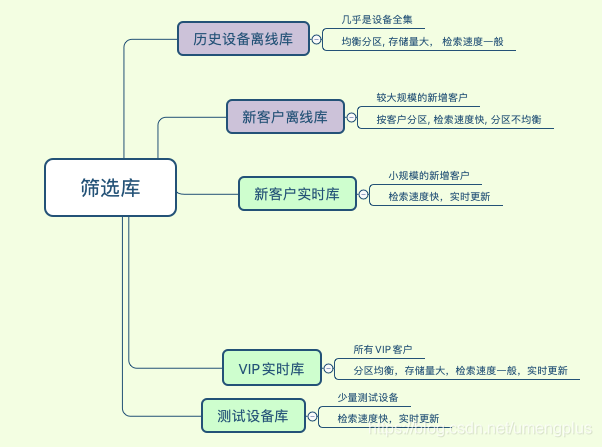
图3.1.1 筛选库的场景设计
组播和广播筛选我们主要围绕ADS来建设,ADS提供了实时和离线两种更新方式,在产品形态上只对Pro客户开放实时筛选能力,在架构设计上通过分库的方式隔离不同层客户的数据,提供差异化服务,提高稳定性。
离线部分:通过离线主库保证了所有客户的T+1筛选能力。在实际业务中离线主库只有读请求作为所有极端场景下的兜底,离线主库以device_token分区,可以实现完全打散但是聚合查询的时候性能稍差。为了提高部分客户尤其是新客户的体验我们设计了新客户离线库,修改为客户分区,提高了单客户聚合查询的效率。但是新客户离线库因客户间的规模差异容易引发分区倾斜,生产中这个表需要持续关注,及时清理和转移,否则在跑ads_loader的时候可能破线。
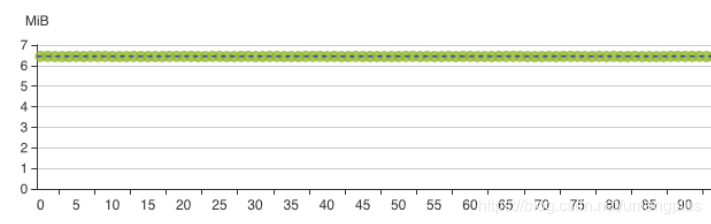
图3.1.2 离线主库的分区状态
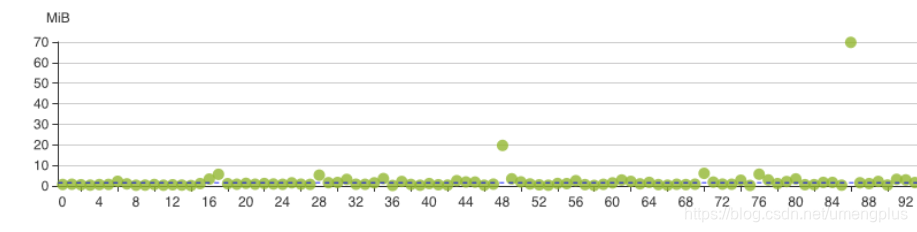
图3.1.3 以客户为分区的分区倾斜情况
实时部分:保证实时筛选服务体验是整个系统的重点,将实时筛选再细分为VIP实时库、测试设备库(方便客户接入阶段实时获取测试效果)、新客户实时库(新增客户一般设备量很小,U-Push会免费提供一段时间的实时筛选服务)。与离线分区类似,在分区设计上同样对大规模场景数据和较少规模场景的数据分表,特别的测试设备库可能产生大量脏数据,整体隔离出来。
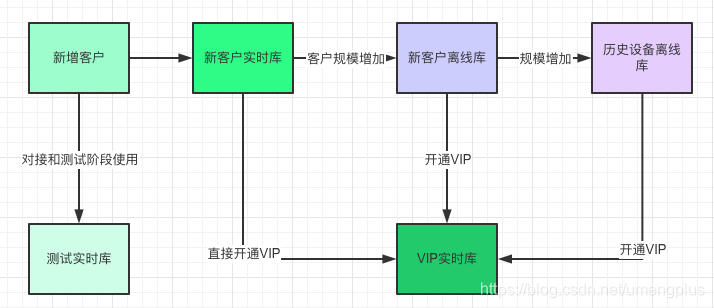
图3.1.2 客户场景迁移
新客户接入伊始基于客户规模区分,在不同的生命周期节点会被引入特定的场景,在保证大盘能力的前提下尽量输出更优质的客户体验。
3.2 利用OSS传输和切分文件
在上述设计中通过离线和实时的区分,降低了高频写可能对设备库造成的影响。但是始终绕不过海量数据的传输问题,为规避这个问题U-Push采用差异化的设计思路,以结果集规模做区分,对大结果集直接通过ADS dump到OSS,基于不同客户的并行度做远程切分,在OSS完成upload和split操作后返回文件路径集合,后续链路只保留文件路径集,直至进入发送层执行并行发送。对小结果集通过select拉取到内存整合消息报文传输,后续链路直接发送设备ID。通过OSS做中间存储,极大的降低冗余的IO损耗。
ADS3.0由于整体架构改动改为通过外部表的方式dump到OSS,与2.0可以dump出单个文件不同3.0在dump后会产生一系列小文件直接导致原有的方案不可行,在通过和ADS团队沟通后ADS特地在3.0版本完善了dump单个文件的功能,致谢ADS的同学。
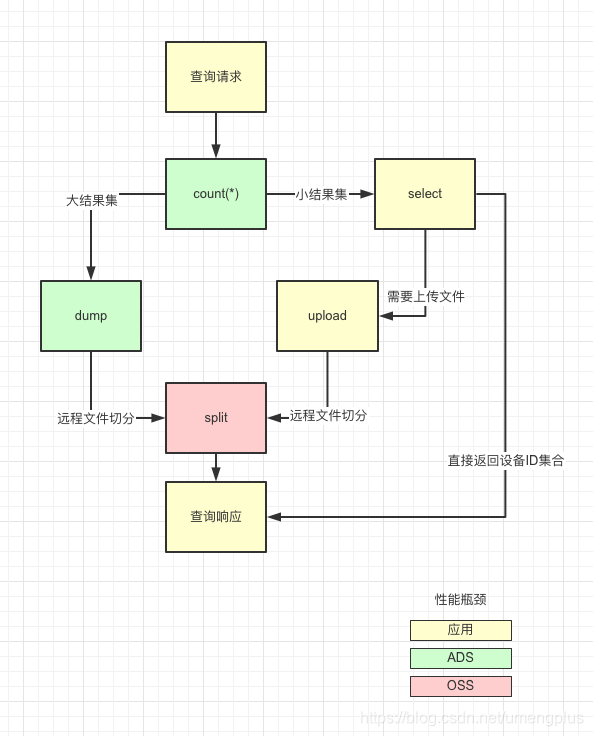
图3.2.1 筛选查询中的性能瓶颈风险
3.3 查询缓存和预筛选
谈到查询场景,必然会有缓存的一席之地,与一般设计思路不同,U-Push直接放弃了针对实时筛选能力的查询缓存,因为在这样的设备量级下随时的设备更新是必然。U-Push的实时筛选库是一个高频写低频读的场景,但是对单次读的要求比较苛刻,首先对未开启实时功能的离线客户,因为设备库是快照形式,一天内的多次读拿到的结果必然相同这时候设置缓存就很有意义,比如新闻、气象、工具类客户的习惯,一天内发送多次广播,就不必每次再去重新生成筛选集文件。
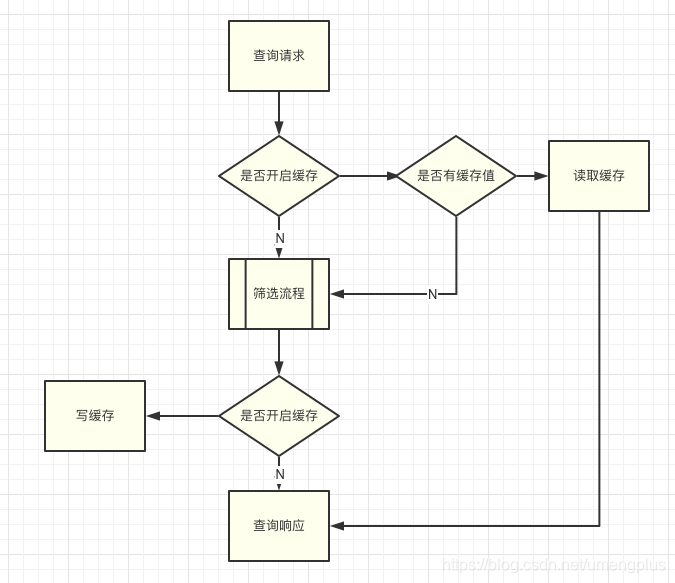
图3.3.1 查询缓存逻辑流程图
预筛选功能的开发是个小插曲,前面讲到U-Push放弃了对实时的查询缓存,导致客户的每次消息发送都要重新去生成文件,在保证数据实时性的角度考虑无可非议,但是遇到“较真”的客户就很有压力。比如新闻类客户极度关注消息下发的时效性,通过开发者控制台可以查看每个任务的筛选时间,有时候同类消息2s的差异也会引发客户在DING群的"客诉"。客户的诉求可以理解但是这也耗费了团队大量的精力。通过和个别客户沟通U-Push开发了预筛选功能,在客户习惯性发送消息的前一段时间预先调度执行筛选逻辑生成设备ID集合,通过损失少量的数据时效性来压缩消息下发时间,争取消息发送速度。
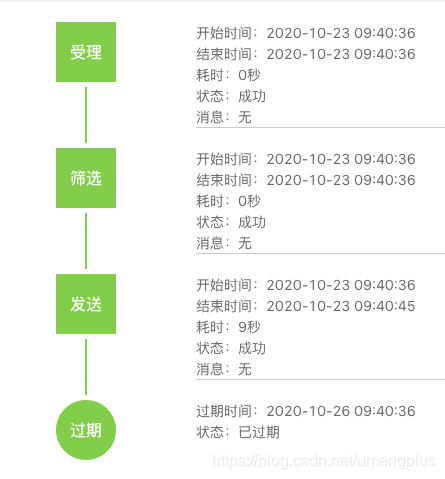
图3.3.1 友盟+U-Push消息轨迹
3.4 Alias筛选的优化
筛选请求可以归类为两种场景:
- Alias功能依赖的ID Mapping场景,NvN的设备ID和Alias映射。
- tag组播和iOS广播功能的select场景,条件查询,基于ADS实现。
Alias功能简介:Alias允许开发者为设备绑定别名,别名由alias_type,alias两个属性组成,譬如开发者可以标识设备A,为他增加alias_type=telephone_number, alias=13900000000以此来给设备A增加手机号的属性。在发送消息时候可以绕开device_token,直接通过服务端指定alias实现触达,alias是一个典型的NVN ID Mapping场景,一个设备在同一个alias_type下面同时只能拥有一个alias。这也是符合一般业务场景的,比如上例一般一个设备只有一个手机号,设置新手机号后会覆盖原alias。如果需要满足双卡双待的功能,需要设置两个alias_type,即alias_type=telephone_number_main,alias_type=telephone_number_secondary。alias的一般使用场景是开发者通过自定义文件播上传一批文件,文件内容为某个alias_type下若干设备alias的集合(百万千万级)。筛选服务扫描文件后依次找出alias值mapping的device_token。
3.4.1 Alias的早期设计
说到Mapping,轮询,高吞吐查询,首当其冲选Redis,早期的U-Push也是如此。

图3.5.1 alias早期数据结构设计
alias利用Redis的Set和Hash结构实现正查和反差的功能,为什么反差用hash,前面讲到1个设备在1个alias_type下只保存最新的alias。这也是出于保护用户的目的,如果1个设备同时存在多个alias下,在开发者执行圈选的时候可能会多次选出这个设备造成多次无效触达。
这个设计平淡无奇,的确也可以满足绝大部分客户的筛选场景,但是随着业务量的增加有几个问题逐渐暴露
- 轮询成为海量设备查询的瓶颈,且不可突破。
- Redis数据持久化难的问题凸显,数据分析难上加难。
- Alias无法很好的满足数据返还链路的需求。
3.4.2 研究Alias的解法
分库的确是很好的思路但是仍然无法满足性能问题和持久化问题,而且随着行业对大数据的关注,数据返还也成为更多开发者的诉求。打通数据返还链路做好客户数据的存、取、管、用已经是一个重要的行业方向。为了解决这个问题U-Push通过离线和实时相结合制定措施
- 分库,增加KA级别客户独享库,压缩横向扩容空间。
- 分层,基于Lindorm做持久化分层存储。
- 离线留存,通过日志系统留存下行筛选结果,一方面完善统计需求,一方面通过回执返还客户。
3.4.3 基于Lindorm宽表的分层设计
用宽表代替Redis的Set设计做正查,用普通表基于设备ID的联合主键做反查,在查询时候通过将单次轮询改为多次mget尽量压缩IO损耗寻找响应性能和服务稳定的中间值,Lindorm的磁盘存储可以满足业务需求的同时通过exporter的配置实现lindorm数据T+1同步至ODPS。

图3.5.2 基于Lindorm款表的分层设计
3.4.4 数据迁移的尝试和思考
数据迁移是在很多业务架构中都是痛中之痛,如何保证稳定、平滑、安全的迁移需要付出大量的成本。U-Push在Alias的数据迁移中做了多种方案的研究和思考。
- Tair整体dump迁移,dump方案理论上可行但是有较大的业务风险,出于稳定性的考虑放弃。
- 写请求增量更新,通过客户的写请求逐key迁移,会有漫长的灰度时间,且无法执行彻底清理,胜在稳定性强。
- 扫描设备主库,分客户批次灰度迁移。在U-Push的功能中,提供了appkey下alias_type的功能,客户可以在开发者控制台查询appkey下的alias_type列表,为实现这个功能对appkey和alias_type做了集合索引,这个索引成为数据迁移的关键。通过扫描设备库获取appkey和device_token,结合alias_type去反查库查找alias,再拿appkey+alias_type+alias去正查库查询device_token列表完成迁移。
第三种方法可以实现存量数据的完美迁移,对线上服务几乎没影响,但是在百亿级设备下,以1wTPS计算仍然需要10天的时间,好在该方案可以实现单个客户的灰度与回滚。
5. 结语
U-Push筛选服务只是U-Push众多服务中的一环,在友盟+巨大的业务量下,为满足形形色色的各行业需求输出了大量精致的设计,本文列出的只是冰山一角,日均消息下发量百亿级做到游刃有余离不开其他技术架构团队在筛选服务迭代中的共同协作。
目前U-Push已经以Push通道为基础,整合了微信、短信、隐私短信升级为多通道触达服务,为众多知名的App如:今日头条、澎湃新闻、作业帮、易车等提供了触达能力,后续持续接入支付宝小程序、头条号等更多运营场景通道,持续为客户提供稳定、高性能、低成本的触达能力保证。
友盟+,国内领先的第三方全域数据智能服务商,截至2020年6月已累计为200万移动应用和890万家网站提供十年的专业数据服务。
