通过上文 Window7 开发 Spark 应用 ,展示了如何开发一个Spark应用,但文中使用的测试数据都是自己手动录入的。
所以本文讲解一下如何搭建一个开发闭环,本里使用了Nginx日志采集分析为例,分析页面访问最多的10个,404页面的10。
如果把这些开发成果最终展示到一个web网页中,在这篇文章中就不描述了,本博其他文章给出的示例已经足够你把Spark的应用能力暴露到Web中。
版本信息
OS: Window7
JAVA:1.8.0_181
Hadoop:3.2.1
Spark: 3.0.0-preview2-bin-hadoop3.2
IDE: IntelliJ IDEA 2019.2.4 x64
服务器搭建
Hadoop:CentOS7 部署 Hadoop 3.2.1 (伪分布式)
Spark:CentOS7 安装 Spark3.0.0-preview2-bin-hadoop3.2
Flume:Centos7 搭建 Flume 采集 Nginx 日志
示例源码下载
应用开发
1. 本地新建一个Spark项目,POM.xml 内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.phpdragon</groupId>
<artifactId>spark-example</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.4.5</spark.version>
<spark.scala.version>2.12</spark.scala.version>
</properties>
<dependencies>
<!-- Spark dependency Start -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>com.github.fommil.netlib</groupId>
<artifactId>all</artifactId>
<version>1.1.2</version>
<type>pom</type>
</dependency>
<!-- Spark dependency End -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.phpragon.spark.WordCount</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
2. 编写Nginx日志分析代码:
import com.alibaba.fastjson.JSONObject;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;
import java.io.Serializable;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
/**
* 分析
*/
@Slf4j
public class NginxLogAnalysis {
private static String INPUT_TXT_PATH;
static {
// /flume/nginx_logs/ 目录下的所有日志文件
String datetime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"));
//TODO: 请设置你自己的服务器路径
INPUT_TXT_PATH = "hdfs://172.16.1.126:9000/flume/nginx_logs/" + datetime + "/*.log";
}
/**
* 请现在配置nginx日志格式和安装flume
* 文件:本项目根目录 test/nginx_log
* 参考:
*
* @param args
*/
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("NetworkWordCount(Java)")
//TODO: 本地执行请启用这个设置
//.master("local[*]")
.getOrCreate();
analysisNginxAllLog(spark);
analysisNginx404Log(spark);
}
/**
*
* @param spark
*/
private static void analysisNginx404Log(SparkSession spark) {
// 通过一个文本文件创建Person对象的RDD
JavaPairRDD<String, Integer> logsRDD = spark.read()
.json(INPUT_TXT_PATH)
.javaRDD()
//.filter(row-> 404 == Long.parseLong(row.getAs("status").toString()))
.filter(new Function<Row, Boolean>() {
@Override
public Boolean call(Row row) throws Exception {
return 404 == Long.parseLong(row.getAs("status").toString());
}
})
.map(line -> {
return line.getAs("request_uri").toString();
})
//log是每一行数据的对象,value是1
//.mapToPair(requestUri -> new Tuple2<>(requestUri, 1))
.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String requestUri) throws Exception {
return new Tuple2<>(requestUri, 1);
}
})
//基于key进行reduce,逻辑是将value累加
//.reduceByKey((value, lastValue) -> value + lastValue)
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer value, Integer lastValue) throws Exception {
return value + lastValue;
}
});
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = logsRDD
//key和value颠倒,生成新的map
.mapToPair(log -> new Tuple2<>(log._2(), log._1()))
//按照key倒排序
.sortByKey(false);
//取前10个
// FormatUtil.printJson(JSONObject.toJSONString(sorts.take(10)));
// 手动定义schema 生成StructType
List<StructField> fields = new ArrayList<>();
fields.add(DataTypes.createStructField("total(404)", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("request_uri", DataTypes.StringType, true));
//构建StructType,用于最后DataFrame元数据的描述
StructType schema = DataTypes.createStructType(fields);
JavaRDD<Row> rankingListRDD = sorts.map(log -> RowFactory.create(log._1(), log._2()));
// 对JavaBeans的RDD指定schema得到DataFrame
System.out.println("输出404状态的前10个URI:SELECT * FROM nginx_log_404 LIMIT 10");
Dataset<Row> rankingListDF = spark.createDataFrame(rankingListRDD, schema);
rankingListDF.createOrReplaceTempView("tv_nginx_log_404");
rankingListDF = spark.sql("SELECT * FROM tv_nginx_log_404 LIMIT 10");
rankingListDF.show();
}
private static void analysisNginxAllLog(SparkSession spark) {
// 通过一个文本文件创建Person对象的RDD
JavaPairRDD<String, Integer> logsRDD = spark.read()
.json(INPUT_TXT_PATH)
.javaRDD()
.map(line -> line.getAs("request_uri").toString())
//log是每一行数据的对象,value是1
//.mapToPair(requestUri -> new Tuple2<>(requestUri, 1))
.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String requestUri) throws Exception {
return new Tuple2<>(requestUri, 1);
}
})
//基于key进行reduce,逻辑是将value累加
//.reduceByKey((value, lastValue) -> value + lastValue)
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer value, Integer lastValue) throws Exception {
return value + lastValue;
}
});
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = logsRDD
//key和value颠倒,生成新的map
.mapToPair(log -> new Tuple2<>(log._2(), log._1()))
//按照key倒排序
.sortByKey(false);
//取前10个
//System.out.println("取前10个:");
//FormatUtil.printJson(JSONObject.toJSONString(sorts.take(10)));
// 手动定义schema 生成StructType
List<StructField> fields = new ArrayList<>();
fields.add(DataTypes.createStructField("total", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("request_uri", DataTypes.StringType, true));
//构建StructType,用于最后DataFrame元数据的描述
StructType schema = DataTypes.createStructType(fields);
JavaRDD<Row> rankingListRDD = sorts.map(log -> RowFactory.create(log._1(), log._2()));
// 对JavaBeans的RDD指定schema得到DataFrame
System.out.println("输出访问量前10的URI:SELECT * FROM tv_nginx_log LIMIT 10");
Dataset<Row> rankingListDF = spark.createDataFrame(rankingListRDD, schema);
rankingListDF.createOrReplaceTempView("tv_nginx_log");
rankingListDF = spark.sql("SELECT * FROM tv_nginx_log LIMIT 10");
rankingListDF.show();
}
public static void readNginxLog(SparkSession spark) {
// 通过一个文本文件创建Person对象的RDD
JavaRDD<NginxLog> logsRDD = spark.read()
.json(INPUT_TXT_PATH)
.javaRDD()
.map(line -> {
NginxLog person = new NginxLog();
person.setRemoteAddr(line.getAs("remote_addr"));
person.setHttpXForwardedFor(line.getAs("http_x_forwarded_for"));
person.setTimeLocal(line.getAs("time_local"));
person.setStatus(line.getAs("status"));
person.setBodyBytesSent(line.getAs("body_bytes_sent"));
person.setHttpUserAgent(line.getAs("http_user_agent"));
person.setHttpReferer(line.getAs("http_referer"));
person.setRequestMethod(line.getAs("request_method"));
person.setRequestTime(line.getAs("request_time"));
person.setRequestUri(line.getAs("request_uri"));
person.setServerProtocol(line.getAs("server_protocol"));
person.setRequestBody(line.getAs("request_body"));
person.setHttpToken(line.getAs("http_token"));
return person;
});
JavaPairRDD<String, Integer> logsRairRDD = logsRDD
//log是每一行数据的对象,value是1
//.mapToPair(log -> new Tuple2<>(log.getRequestUri(), 1))
.mapToPair(new PairFunction<NginxLog, String, Integer>() {
@Override
public Tuple2<String, Integer> call(NginxLog nginxLog) throws Exception {
return new Tuple2<String, Integer>(nginxLog.getRequestUri(), 1);
}
})
//基于key进行reduce,逻辑是将value累加
//.reduceByKey((value, lastValue) -> value + lastValue)
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer value, Integer lastValue) throws Exception {
return value + lastValue;
}
}).sortByKey(false);
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> rankingListRDD = logsRairRDD
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false);
//取前10个
List<Tuple2<Integer, String>> top10 = rankingListRDD.take(10);
System.out.println(JSONObject.toJSONString(top10));
// 对JavaBeans的RDD指定schema得到DataFrame
Dataset<Row> allLogsDF = spark.createDataFrame(logsRDD, NginxLog.class);
allLogsDF.show();
}
@Data
public static class NginxLog implements Serializable {
private String remoteAddr;
private String httpXForwardedFor;
private String timeLocal;
private long status;
private long bodyBytesSent;
private String httpUserAgent;
private String httpReferer;
private String requestMethod;
private String requestTime;
private String requestUri;
private String serverProtocol;
private String requestBody;
private String httpToken;
}
}
准备工作
1.请查看文章, Centos7 搭建 Flume 采集 Nginx 日志 。
2.执行测试脚本,增加访问日志:
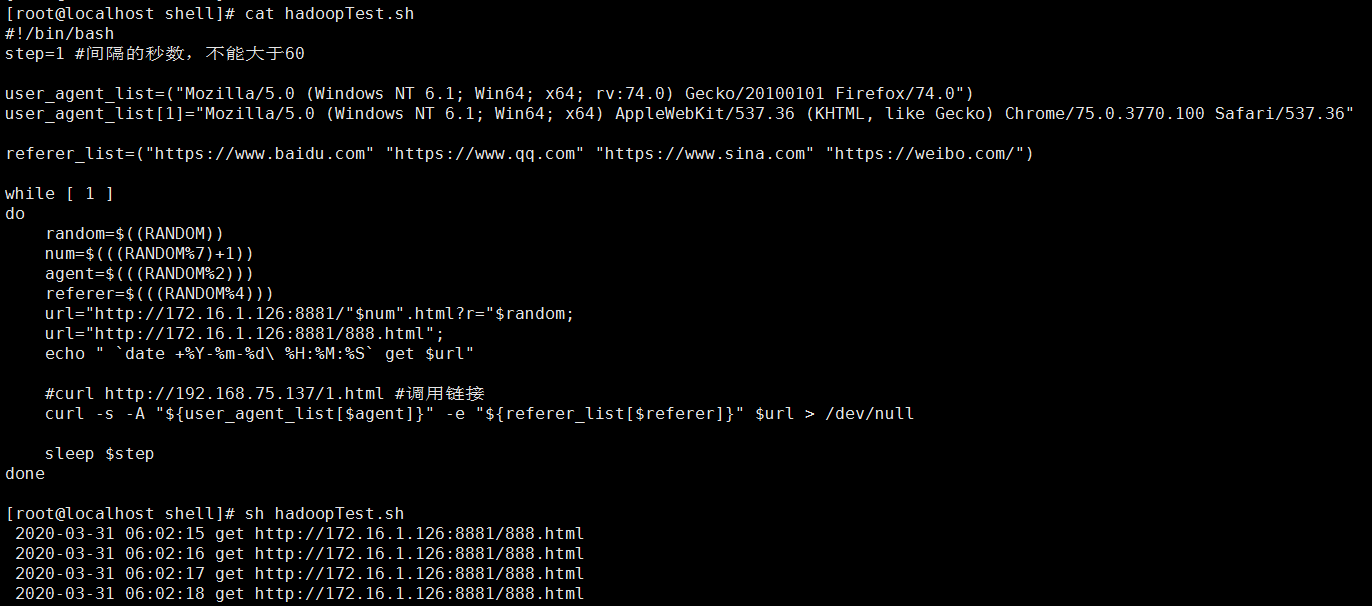
本地调试
1.增加红色部分代码,设置为本地模式 。
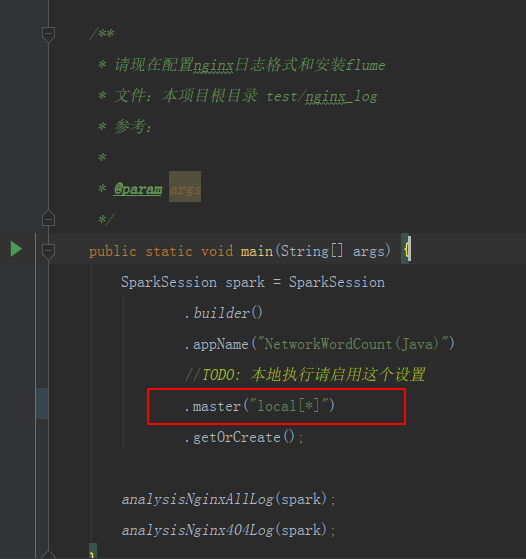
2.右键执行main方法:
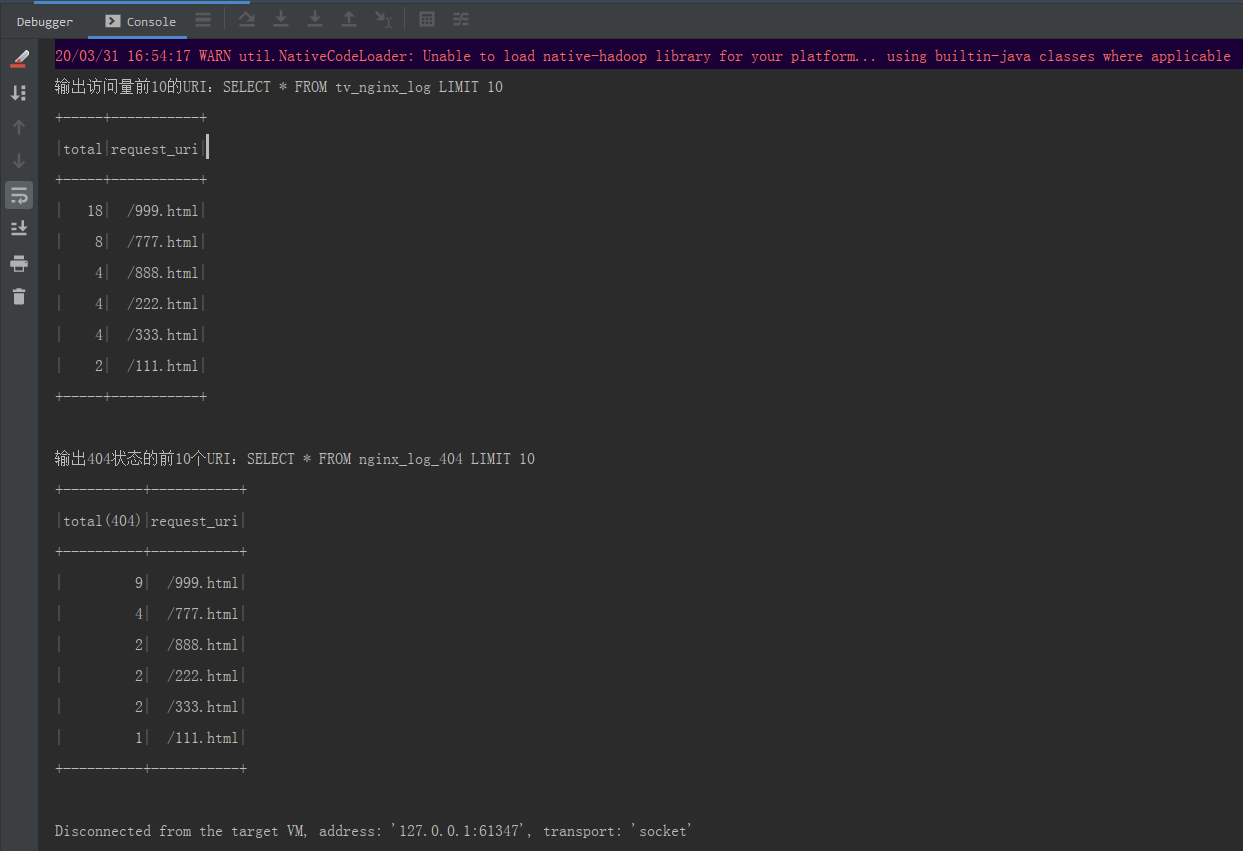
服务端调试:
PS: