论文阅读:
Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
作者声明
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://www.cnblogs.com/phoenixash/p/15371354.html
基本信息
1.标题:Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
2.作者:Haifeng Li, Yi Li, Guo Zhang, Ruoyun Liu, Haozhe Huang, Qing Zhu, Chao Tao
3.作者单位:Central South University
4.发表期刊/会议:arXiv
5.发表时间:2021
6.原文链接:https://arxiv.org/abs/2106.10605
Abstract
近年来,有监督深度学习在遥感图像语义分割中取得了巨大的成功。然而,基于监督学习的语义分割需要大量标注样本,在遥感领域很难获得。一种新的学习范式——自我监督学习(SSL)——可以用来解决这类问题,方法是先用大的未标记图像训练一个通用模型,然后用很少的标记样本对下游任务进行微调。对比学习是SSL的一种典型方法,它可以学习通用的不变量特征。然而,现有的对比学习大多是为了分类任务获得图像级的表示而设计的,这对于需要像素级识别的语义分割任务可能是次优的。因此,我们提出了全局风格和局部匹配对比学习网络(Local matching contrast Learning Network, GLCNet)的遥感语义分割方法。具体来说,1)全局风格对比模块可以更好地学习图像级的表示,因为我们认为风格特征可以更好地代表图像的整体特征。2)设计局部特征匹配对比模块,学习局部区域的表示,有利于语义分割。我们在4个遥感语义分割数据集上进行了实验,实验结果表明,该方法的性能优于目前最先进的自监督方法和ImageNet预训练方法。具体来说,通过利用原始数据中1%的标注,与现有基准相比,我们的方法在ISPRS Potsdam数据集上提高了6%,在Deep Globe Land Cover Classification数据集上提高了3%。此外,当上游任务和下游任务的数据集存在一定差异时,我们的方法优于监督学习。本研究促进了自监督学习在遥感语义分割领域的发展。由于SSL可以直接从遥感领域容易获取的未标记数据中学习到数据的本质特征,这对于全局匹配等任务可能具有重要意义。
1.Introduction
随着遥感技术的发展,高分辨率卫星图像的获取变得越来越容易。遥感影像广泛应用于城市规划、灾害监测、环境保护、农业管理等领域。遥感影像信息的提取与识别是这些应用的基础。语义分割作为一种像素级图像分析技术,是遥感图像解译领域中最重要、最具挑战性的研究方向之一。
传统的遥感语义分割算法大多是基于手工特征的机器学习方法,如支持向量机(SVM,[5],[6])、随机森林(RF,[7])和人工神经网络(ANN,[8])。自2012年AlexNet[9]获得ILSVR冠军以来,深度学习特别是深度卷积神经网络(DCNN)受到越来越多的关注[10][12]。与传统方法相比,深度学习完全是数据驱动的,可以提取更抽象的高级特征,在图像分类任务[13]上取得了显著的效果。随后,FCN[14]、U-Net[15]、Deeplab series[16][18]等基于全卷积网络的方法几乎主导了计算机视觉图像语义分割领域。在遥感领域,研究人员针对遥感的具体特点,改进了一般的语义分割网络,进一步提高了遥感语义分割任务[19]、[20]的准确性。例如,Mohammadimanesh等人[21]设计了一种新的全卷积网络(FCN)体系结构,专门用于使用极化SAR(PolSAR)对湿地综合体进行分类。Ding等人([22])研究了大尺寸遥感图像(RSIs)语义分割问题。为了更好地利用RSIs中的全局上下文信息,他们提出了一种两阶段的语义分割网络,通过对图像进行不同大小的缩放,分别获得全局上下文信息和局部细节信息,然后融合特征来提高准确率。
然而,基于深度学习的监督遥感语义分割方法在很大程度上依赖于大量高质量的标记样本。随着遥感语义分割技术在全球可持续发展中发挥越来越重要的作用,其对全球大量高质量标记样本的需求日益增长[23],[24]。语义分割任务需要进行像素级标签这是非常昂贵的,而且遥感图像在时间和空间上有巨大的异质性,因此现有的标签数据实际上只有截取的图片,而且很难获得大量的,丰富涵盖全球地区,多分辨率、多季节、多光谱的标注样本。为了解决标记样本不足的问题,一种策略是通过数据增强[25]、GAN[26]等来生成更多的样本;第二种策略是利用其他标注的数据,如预训练[27]或迁移学习[28],[29],目的是迁移从更大或更相关的领域学到的知识,以提高在目标领域的性能或减少对标记样本的依赖;另一个策略是学习如何在少数标记的样本上有更好的性能,比如元学习[30]。但是,以上方法都是基于监督学习的范式,这种范式与具体任务和数据集高度相关,不可能得到通用的模型。例如,当源域和目标域的差异较大[31]时,迁移学习可能会出现负迁移。此外,这些方法没有利用大量未标记的数据。
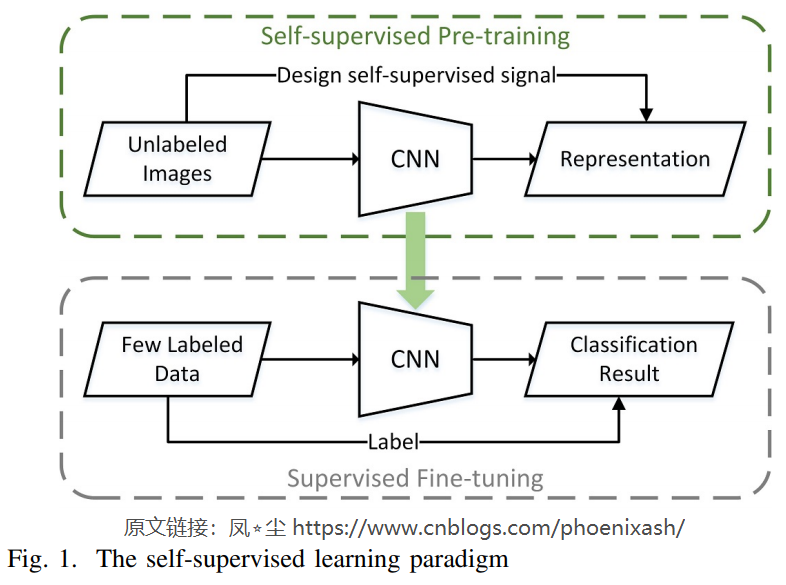
自监督学习提供了一种新的范式,如图1所示,首先通过设计自监督信号从未标记的图像数据中学习知识,然后转移到下游任务中,仅使用有限的标记样本[32],就可以实现与下游任务的监督学习相当的性能。虽然大量的标记数据无法获取,覆盖整个世界的多样的和丰富的无标注图像数据很容易获取,而且无标注图像数据中包含的信息比稀疏的标注数据更加丰富,所以我们可以期待通过self-supervised学习更多潜在的普遍性的知识。
在这项工作中,我们关注对比学习,这是一个典型的和成功的自我监督方法。我们将自我监督对比学习范式引入遥感语义分割任务中。在预训练阶段,我们使用对比学习来增强样本在无标注数据上的一致性来学习通用遥感视觉模型(G-RSvM)。G-RSvM增强了不变性,如光照不变性、旋转不变性、尺度不变性等。此外,之前的对比学习主要是针对图像分类任务设计的,只关注图像级表示的学习。然而,在遥感语义分割任务中,全局特征学习与局部特征学习之间存在平衡:从全局表示角度来看,由于时间(春、夏、秋、冬)、天气、传感器等方面的差异,遥感图像存在整体差异;从局部特征的角度来看,像素级语义分割需要更多的局部信息。鉴于此,我们提出了全局风格和局部匹配对比学习网络(Global style and Local matching contrast learning Network, GLCNet)框架,其中全局风格对比学习模块专注于全局表示,局部匹配对比学习模块用于学习像素(Local)级特征。
本文的主要贡献总结如下:
1) 据我们所知,我们首次将自监督对比学习应用于遥感语义分割任务,并在多个数据集上验证了自监督对比学习可以直接从未标注的图像中学习特征,以有限的标注指导下游的语义分割任务。
2)针对遥感语义分割任务中全局特征学习与局部特征学习之间的平衡问题,提出了一种新的自监督对比学习框架——Global style and Local matching contrast learning Network (GLCNet)
3)我们在两个公共数据集和两个现实数据集上评价我们提出的方法。实验结果表明,与现有基准相比,该方法仅使用1%的原始标注数据,在Potsdam数据集上提高了6%,在Deep Globe Land Cover数据集上提高了3%。在上游数据集和下游数据集不高度相似的情况下,它也优于监督学习。
本文的其余部分组织如下。在第二节中,我们介绍了基于自监督对比学习的语义分割方法以及我们进一步改进的用于语义分割任务GLCNet的自监督方法。实验结果见第三节。第四节说明了进一步的讨论,结论在第五节中提供。
2.METHOD
A. Overview
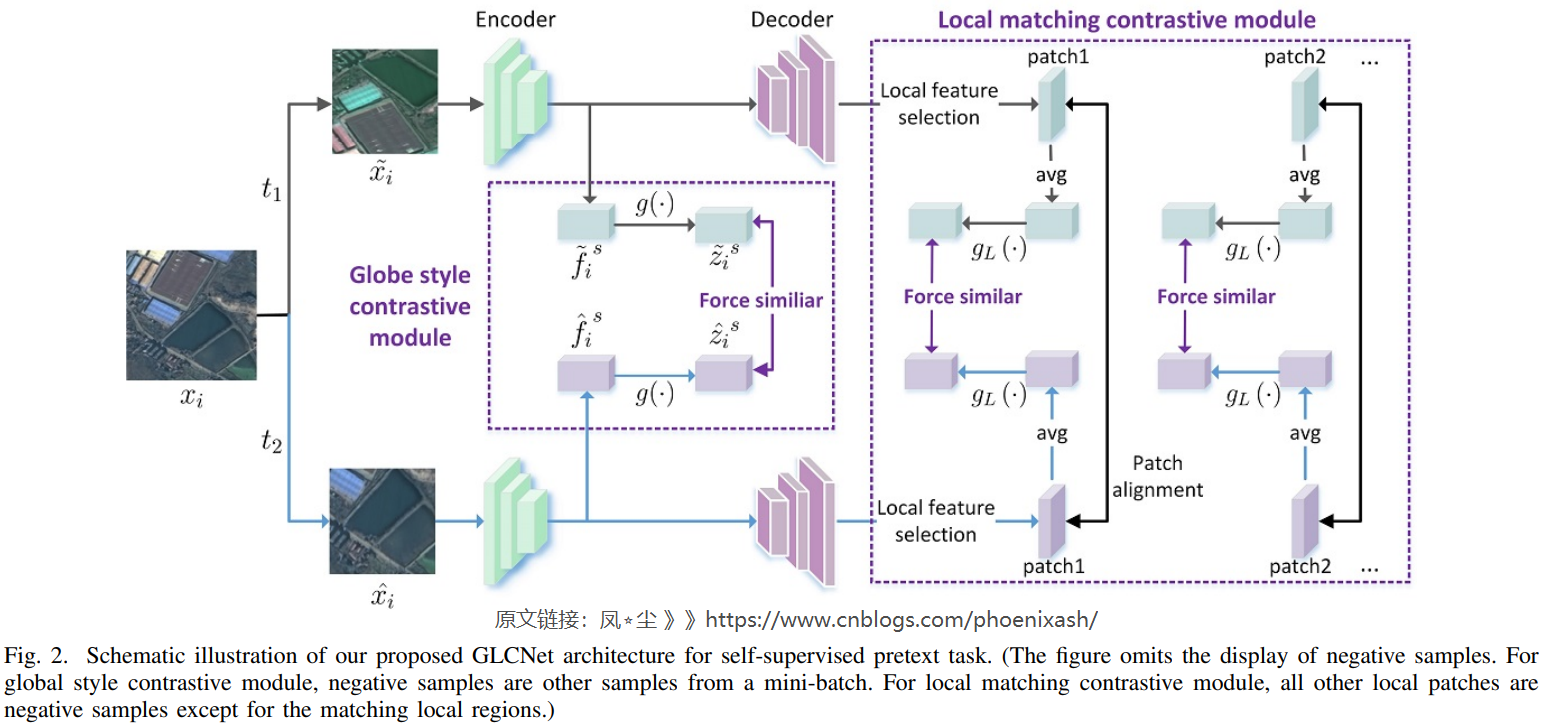
监督深度学习的成功依赖于大量标注样本,这是遥感语义分割中难以满足的。如图1所示,自监督学习提供了一种新的范式,可以直接从大量现成的未标记数据中学习潜在的有用知识,然后将其转移到下游任务中,尤其是在标记样本有限的情况下取得更好的性能。在我们的工作中,下游任务是遥感图像的语义分割,因此我们致力于设计一个自监督的遥感语义分割任务模型。在本文中,我们引入对比学习来学习一般不变表示,同时,我们考虑到语义分割任务的特点,提出了GLCNet自监督方法,如图2所示,该方法主要包含两个模块:
1)全局风格对比学习模块主要考虑到现有对比学习中衡量样本特征所用的全局平均池化特征并不能很好地替代图像的整体特征,因此,引入更能代表图像整体特征的风格特征,以帮助模型更好地学习全局表示。
2)局部匹配对比学习模块主要考虑语义分割数据集的单幅图像特征类的丰富程度,仅提取全局特征可能会丢失大量详细信息,而图像级表示对于需要像素级识别的语义分割任务可能是次优的。
B. Contrastive learning
对比学习就是通过强迫正样本对相似,负样本对不同[34],[36]进行学习。对比学习方法的关键在于构建正样本和负样本。最新的突破性方法[33],[34]将实例分类为各自的标签,这意味着将一个样本的不同增强版本作为正样本处理,其他样本作为负样本处理。对比学习可以鼓励模型学习变换的不变性和区分不同样本的能力。在这项工作中,我们使用对比学习来学习一般的时空不变性的遥感特征。具体来说,我们对样本进行随机旋转、裁剪、缩放等操作,使模型学习到空间不变性,如旋转不变性和缩放不变性。此外,遥感影像的时间性差异主要是由季节因素和成像条件造成的整体纹理和颜色差异。由于缺乏多时相图像数据,我们通过在样本上应用随机颜色失真、随机噪声等来模拟时间变换,使模型学习时不变特征。
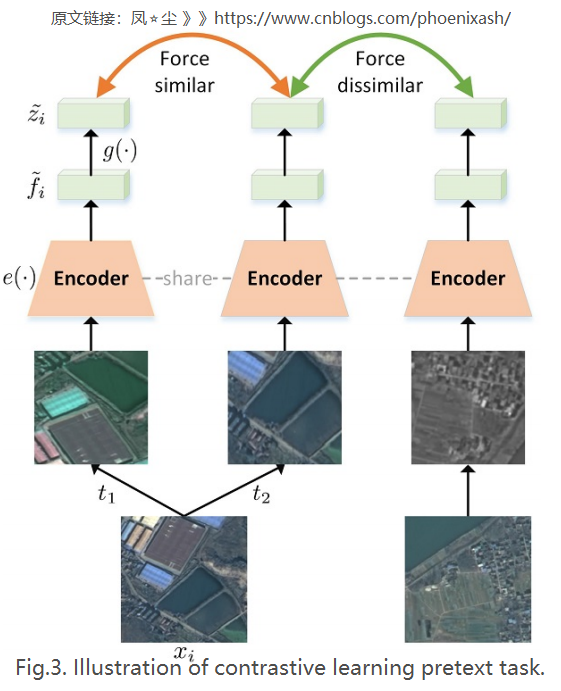
受SimCLR[34]的启发,我们采用对比学习的方法来训练语义分割网络的编码器部分,如图3所示,该网络由以下四个主要组成部分组成:
1)数据增强:为了鼓励模型能够学习一般的时空不变性特征,如图4所示,我们执行空间变换如随机裁剪,缩放,翻转和旋转来学习空间不变性特征,通过颜色失真、高斯模糊、随机噪声,等模拟时间变换,用于时间不变性特征的学习。具体来说,在给定的样本(x)中,通过数据扩充(t_1)和(t_2),生成两个扩充视图(x)属于和(hat{x}),即(x= t_1(x), hat{x}= t_2(x))。 在本工作中,(t_1)表示随机裁剪,然后调整大小到固定分辨率(例如,224x224),(t_2)表示依次应用几个增强:随机裁剪,然后调整大小到固定分辨率;随机翻转;随机旋转;随机颜色失真;随机高斯模糊;随机噪声和随机灰度。
2)特征提取:利用编码器网络(e(·))从增广样本实例中提取全局特征:
式中(mu)表示对feature map中各通道均值的计算,即全局平均池化。在本工作中,(e(·))是语义分割网络DeepLabV3+[18]的编码器部分。
3)映射头部分:如式2所示,映射头(g(·))是一个带有一层隐层(ReLU)的MLP。(g(·))的存在在SimCLR[34]中被证明是非常有益的,可能是因为它可以让(e(·))为下游任务构造和保留更多潜在的有用信息。
其中(σ)为ReLU非线性。
4)对比损失:对比损失期望正样本对相似,负样本对不同。具体来说,小批量的N个样品增广为2N个样品。由同一样本扩增的一对样本形成一对正样本,其余2(N-1)个样本为负样本,故将对比损耗(L_C)定义为:
这里:
其中sim为两个特征向量之间的相似度度量函数,在本文中sim为余弦相似度。(Lambda^{-})表示除正样本对外还有2 (N-1)个负样本,( au)表示一个温度参数。
虽然现有的对比学习范式可以学习到强大的图像级表征,但仍然存在一些问题:首先,现有的对比学习使用全局平均池化特征提取样本的特征,可能不能很好地代表样本的整体特征;其次,更关键的是,通过实例对比学习学习的图像级表示对于需要像素级识别的语义分割任务可能是次优的。因此,我们提出了GLCNet。
C. Global style and Local matching Contrastive learning Network (GLCNet)
我们提出GLCNet方法展示在图2中,主要包含两个模块:全局风格对比学习模块主要关注的问题在于:用于现有的对比学习的全局平均池化的特征并不是一个对复杂的遥感图像的整体特征好的替代;局部匹配对比学习模块主要考虑现有的对比学习方法大多是为图像分类任务而设计,获取图像级特征,对于需要像素级识别的语义分割可能是次优的。具体内容如下。
1) Global style contrastive learning module: 与已有的实例对比学习类似,全局风格对比学习通过强迫一个样本的不同增强视图与其他样本相似或不同进行学习。不同之处在于,我们使用的是风格特征,而不是实例对比学习中使用的简单的平均池化特征,因为我们认为它更能代表图像的整体特征。黄和Belongie[37]表明CNN提取的channel-wise均值和方差的特征映射可以表示图像的风格特点,所以我们通过计算编码器(e(·))提取的特征的channel-wise均值和方差,提取全局风格特征向量,定义如下
其中(mu)为特征图的通道均值,(sigma)为通道方差。
因此,对于一个小批量的N个样本,与式3类似,全局风格对比学习损失定义如下
和:
其中,( ilde{z_{i}}^{s}=gleft(f_{s}left( ilde{x}_{i} ight) ight), hat{z}_{i}{ }^{s}=gleft(f_{s}left(hat{x}_{i} ight) ight))
2) Local matching contrastive learning:提出局部匹配对比学习模块主要有以下两个原因:第一,单一遥感语义分割图像中的土地覆盖类别极为丰富。仅提取整幅图像的全局特征进行测量和区分,会丢失大量的信息;其次,利用实例对比学习方法获取图像级特征,由于需要像素级的识别,对语义分割可能是次优的。因此,局部匹配对比学习模块被设计用于学习有利于像素级语义的局部区域表示。它由以下主要组件组成:
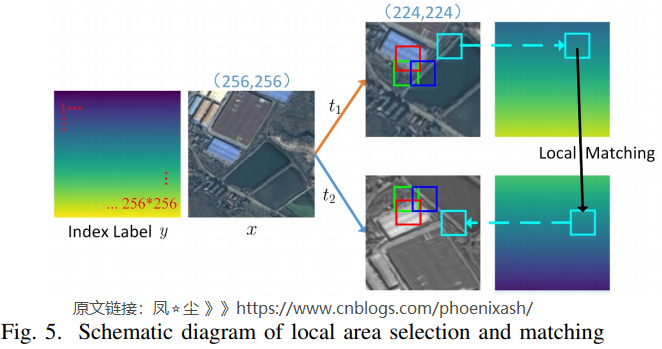
a). Local region selection and matching
如图5所示,变换后的两个版本( ilde{x})和(hat{x})来自同一张图像x,即( ilde{x} = t_1 (x), hat{x} = t_2 (x)),我们从( ilde{x})和(hat{x})中选择并匹配多个局部区域。此外,随机裁剪、翻转、旋转等数据增加操作会导致( ilde{x})和(hat{x})之间的位置不匹配。因此,我们通过引入索引标签来记录像素位置,以确保两个匹配局部区域的中心位置在原始图像中是对应的。具体来说,首先从( ilde{x})中随机选择一个大小为(s_p imes s_p)的局部区域,然后根据该局部区域的中心位置索引值确定匹配的相同大小的局部区域在(hat{x})中的位置。另外,为了保证不同的局部区域之间不存在过度的重叠,每次选择后都将局部区域排除,保证后续选择的局部区域的中心不落入之前选择的局部区域。以上步骤重复几次,得到多个匹配的局部区域。
b). Local matching feature extraction
局部特征提取步骤如下:首先,从编码器-解码器CNN网络的一对正样本(( ilde{x}, hat{x}))中提取特征映射(d (e ( ilde{x})))和(d (e (hat{x})))。在本文中,(e(·))和(d(·))分别对应DeepLabV3+[18]的编码器部分和解码器部分。其次,根据A中的局部区域选择与匹配的思想,从(d (e ( ilde{x})))和(d (e (hat{x})))中得到多个匹配局部区域的局部特征图。如果( ilde{p}_j)和(hat{p}_j)是匹配局部区域的特征映射,其中( ilde{p}_j)来自(d (e ( ilde{x}))), (hat{p}_j)来自(d (e (hat{x}))),则最终的局部特征向量定义如下:
式中(mu)为计算feature map中各通道的均值。
c). Local matching contrastive loss
局部匹配对比损失通过强制匹配局部区域的特征表示相似和不同局部区域的特征表示不相似来更新一个完整的语义分割码解码器网络。对于一个小批量的N个样本,局部匹配对比度损失定义如下
和:
式中,(N_L)表示从N个样本的小批中选择的所有局部区域的数量,即(N_L = N imes n_p),其中(n_p)为从一个样本中获得的匹配的局部区域的数量。(Lambda_L^-)是除两个匹配的局部区域外的所有局部区域对应的一个特征图一集合,(g_L(·))是与(g(·))相似的映射头。
3) Total loss:全局风格对比学习可以捕获全局信息,而局部匹配对比学习可以在局部水平上进行区分,这可能有助于需要像素级识别的语义分割。因此,我们的方法由这两个部分组成,即最终的损失定义如下:
式中λ为本工作中的常数0.5。(mathcal{L}_G)表示式5中的全局风格对比损失,仅用于更新编码器网络。式7中(mathcal{L}_L)表示局部匹配对比损失,可以同时更新编码器部分和解码器部分。
此外,我们提供了算法1来详细描述我们提出的GLCNet。
