网站架构中最核心的几个要素包括:性能,可用性,伸缩性,扩展性和安全性,而性能又是其中最为重要的,本篇简要说下网站性能优化方面所需做的一些事情;
1. 网站性能问题概要
| 性能问题 | 说明 |
| 产生原因 | 大都是在用户高并发访问时产生的 |
| 主要工作 | 改善高并发用户访问情况下的网站访问速度 |
| 主要目的 | 改善用户体验,让用户觉得网站很快,一切的产品都必须站在用户的角度考虑问题 |
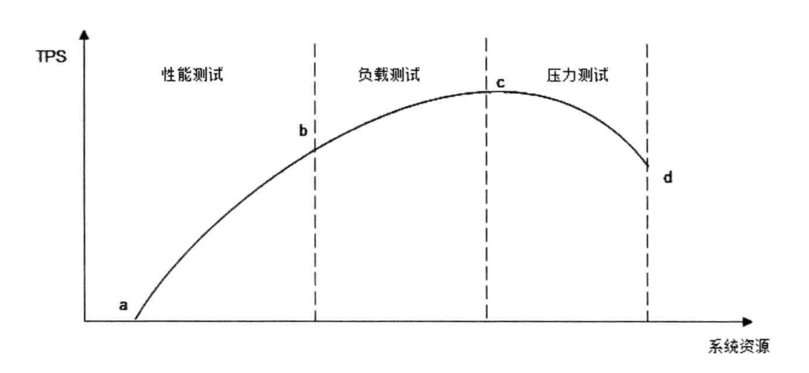
2. 网站性能测试
站在不同的视角,所关注的网站性能是不一致的:
| 视角 | 关注点 | 说明 |
| 用户视角 | 用户打开浏览器网页的响应速度,网页能再多长时间内打开,一般超过3秒就会感觉比较慢了 | 用户感受到的时间主要包括网络通信、服务器处理、浏览器解析时间 |
| 开发视角 | 主要关注应用程序本身及其子系统的性能 | 例如应用程序本身各业务耗时、并发量、程序是否稳定等 |
| 运维视角 | 更关注基础设施性能和资源利用率 | 如运营商带宽能力,服务器硬件配置,网络、服务器资源利用率等 |
站在开发、测试人员角度,性能测试的主要指标:响应时间、并发数、吞吐量、服务器各性能指标;
| 性能指标 | 说明 | 测试方法 |
| 响应时间 | 从发出请求开始到收到最后响应数据所花费的时间 | 一般计算多次重复请求所花费的总响应时间,再除以请求次数 |
| 并发数 | 系统能够同时处理请求的数目,也代表了同时发起请求的用户数 | 多线程模拟并发用户 |
| 吞吐量 | 单位时间内系统处理的请求数量,体现出系统的整体处理能力,一般常使用TPS(每秒事务数)、HPS(每秒处理HTTP请求数)、QPS(每秒处理查询数) | 不断增加并发数量,查看响应时间的变化曲线 |
| 服务器各性能指标 | 包括系统负载、内存使用、磁盘使用、CPU使用、网络I/O等 | 设定阈值,超过阈值报警 |
资源消耗与TPS性能曲线图:
并发用户访问响应时间曲线图:

3. 性能优化
根据性能测试,定位产生性能问题的具体原因,找到瓶颈点,逐步优化;
一般性能优化分为Web前端性能优化、应用服务器性能优化、存储服务器性能优化;
Web前端性能优化
1. 浏览器访问优化
| 优化方法 | 造成性能问题的原因 | 主要手段 |
| 减少http请求 | HTTP无状态,每次请求服务端都需要启动独立线程去处理,开销较大 | 合并CSS、JS文件,合并图片(可通过CSS偏移来解决显示问题) |
| 使用浏览器缓存 | 静态资源更新频度低,不宜每次都重新获取 | 设置HTTP头信息中的Cache-Control和Expires属性,可设定浏览器缓存 |
| 压缩 | 静态资源中一些无用的空格,回车等占据了大量字节,造成每次网络传输浪费不必要的流量 | 可使用GZip对CSS、JS等文件进行压缩 |
| CSS与JS位置 | 浏览器是下载完全部CSS后才会对页面进行渲染,加载JS后则立即执行 | 一般将CSS放在页面最上面,JS放在页面底部 |
| 减少Cookie传输 | Cookie会包含在每次的请求和响应中,太大的Cookie会影响数据传输 | 尽量减少Cookie中传输的信息量,静态资源使用独立的域名访问,关闭Cookie |
2. CDN加速
上面说了,CDN的本质仍然是缓存,将数据缓存在离用户最近的机房,提升访问速度,降低中心机房服务器的压力;
CDN能够缓存的一般都是静态资源,如图片,文件,视频,CSS,JS等,将访问频度高的静态资源放到CDN中;
3. 反向代理
| 反向代理作用 | 说明 |
| 保护网站安全 | 所有请求到达的第一层都是反向代理服务器,隔离了用户和网站服务器 |
| 缓存 | 将静态资源缓存在反向代理服务器,减轻Web服务器压力,提升访问速度 |
| 负载均衡 | 应用服务器有多台的话,使用反向代理做负载均衡是不错的选择,如Nginx |
应用服务器性能优化
1. 分布式缓存
网站性能优化第一定律:优先考虑使用缓存优化性能
缓存的本质是内存Hash表,数据以Key/Value的形式存储在Hash表中,时间复杂度O(1),Hash表存储如下图所示:

只要是缓存,就会涉及到缓存未命中与缓存失效问题,因此,缓存中的数据一般都是读取比例很高,很少变化的数据;
不合理的使用缓存意义不大,还可能降低网站性能,不合理使用缓存可能造成的影响如下表所示:
| 不合理使用缓存情况 | 原因 |
| 频繁修改的数据 | 缓存很快会失效,徒增系统负担 |
| 没有热点的访问 | 不遵循二八定律,所有数据访问频度基本相同的情况,使用缓存基本没意义 |
| 数据不一致与脏读 | 缓存会设置失效时间,超时后会重新加载,也会造成短时间内数据不一致问题,如修改了数据,实时同步缓存,又会造成系统开销较大问题,需要权衡 |
| 缓存可用性 | 当缓存大面积失效时或缓存服务崩溃时,会对后端数据库造成突发性的高并发访问,瞬间压力过大,可能导致数据库服务器宕掉,造成雪崩; 可通过分布式缓存服务器集群来提高缓存的可用性; |
| 缓存穿透 | 不恰当业务或攻击,持续请求不存在数据,缓存中没有该数据,所有请求全部落到数据库服务器上,造成雪崩,可将不存在数据也缓存起来,设为null来解决此问题; |
分布式缓存—Memcached,分布式内存对象缓存系统,K/V存储,具体流程:
1. 检查客户端请求的数据是否在Memchahe中存在,如存在,直接将数据返回; 2. 如果请求数据不在Memcache中,去查询数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存到Memcache; 3. 每次更新数据库,同时更新Memcache中的数据,保证数据一致性; 4. 当分配空间使用完毕后,使用LRU策略替换数据;
Memcached的分布式算法——一致性哈希,不再展开讨论,比较简单;
Memcached服务端通信模块基于Libevent(支持事件触发的网络通信程序库),服务器集群之间互不通信,能做到线性伸缩;
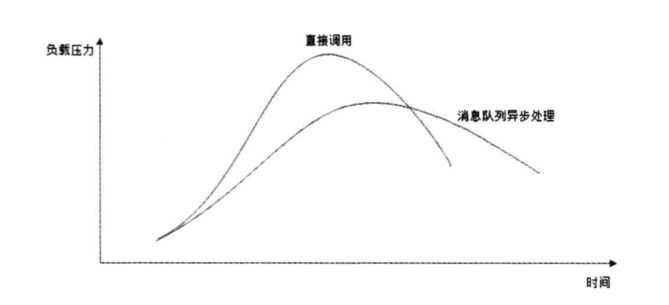
2. 异步操作

3. 使用集群
在高并发下,可使用负载均衡技术构建应用服务器集群,将请求分发到多台应用服务器来处理,降低单台服务器压力,提升响应速度;
4. 代码优化
| 关注点 | 说明 | 优化 |
| 多线程 |
多线程优势是充分利用CPU资源,加速请求处理速度; 对于Web应用,用户请求的多线程通常被Web服务器容器管理; 最需注意的问题:多线程安全 |
最佳线程数: [任务执行时间/(任务执行时间 - IO等待时间)] * CPU核数; 多线程对资源修改必须加锁 |
| 资源复用 | 尽量减少开销很大的系统资源的创建和销毁,如数据库连接,网络通信连接,线程、复杂对象等; |
资源复用主要使用: 1. 单例(如Spring中默认构造的对象都是单例) 2. 对象池(如各种连接池,线程池,因为连接、线程都是对象,其实各种池都是对象池) |
| 数据结构 | 好的数据结构和算法的使用是程序性能保障的核心 | —— |
| 垃圾回收 | 尽量了解所使用语言的垃圾回收算法,了解其本质后,在设计程序时能避免一些不良的设计,有助于程序优化和参数调优,编写内存安全的代码 | 比较流行的垃圾回收算法主要由引用计数、标记清除以及分代回收等 |
存储服务器性能优化
在很多情况下,磁盘的访问速度成为整个系统的瓶颈,而且磁盘中的数据是网站最重要的资产,故磁盘的容错性和可用性都至关重要;
- 适当使用SSD;
- 合理使用RAID(RAID0,RAID1,RAID10,RAID5,RAID6等)
- 合理使用HDFS等分布式文件系统