一、存储引擎是什么
存储引擎是数据库的核心,对于mysql来说,存储引擎是以插件的形式运行的。MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
二、存储引擎有哪些
MySQL版本为5以后的(博客测试版本是MySQL5.5.15)
1、查看MySQL默认支持的存储引擎
show engines g;
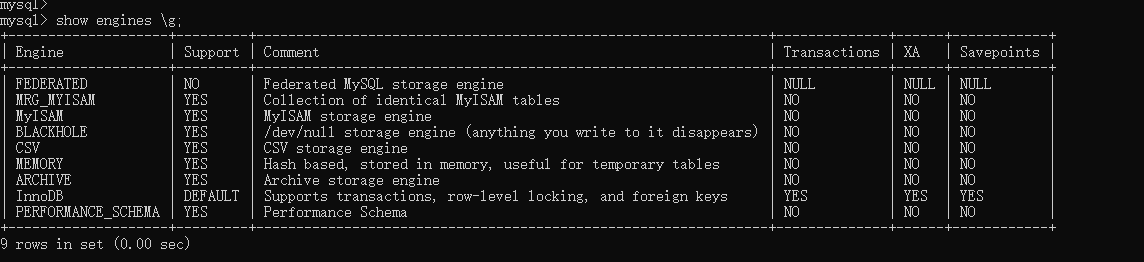
可以看到,这里一共有九种默认的存储引擎,但能够经常使用到的其实只有那么几种,
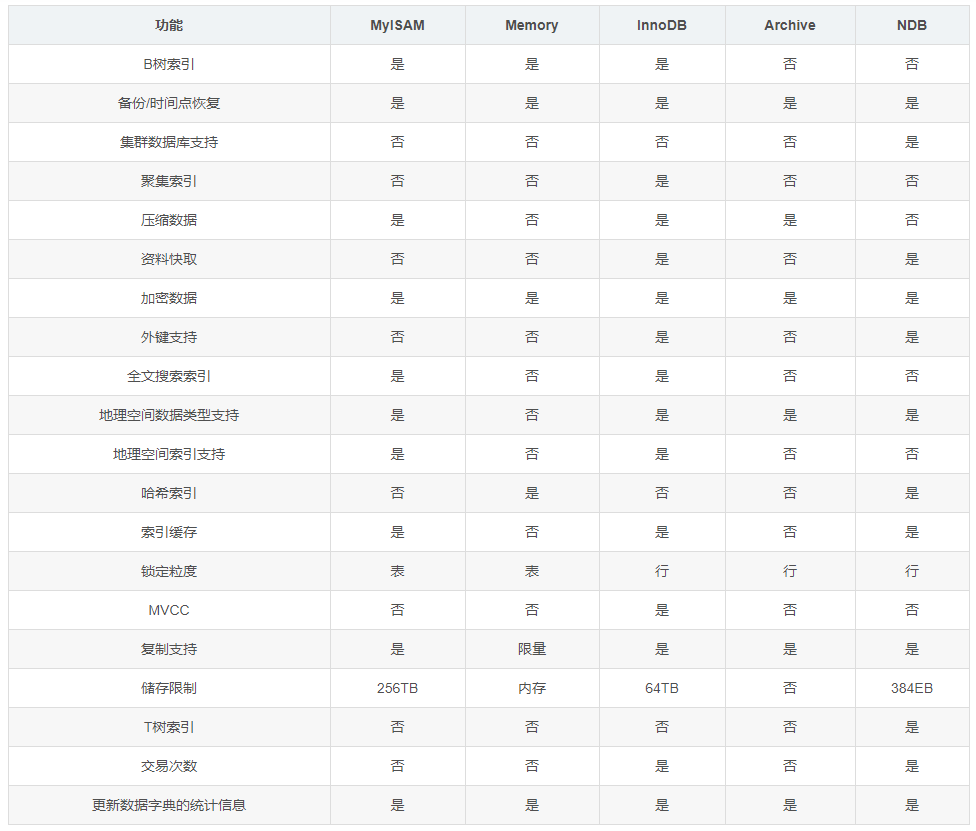
2、各主要存储引擎对比
三、常用存储引擎介绍
1、InnoDB
MySQL5.5后的默认数据库存储引擎。
这个可能是平常用的最多的一个数据库引擎了,因为他支持事务,MySQL中支持事务的存储引擎并不多,除了InnoDB,还有NDB(而且NDB只支持在NDB集群中使用),所以一般需要用到事务的场景,我们一般选用的就是InnoDB存储引擎。
(1)优缺点
优点:支持ACID事务;聚集索引;支持外键;支持行锁;存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度;
缺点:不支持全文索引,不保存表行数,相比MyISAM,InnoDB写的处理效率要差一些,并且会占用更多的磁盘空间以保留数据和索引。
(2)存储方式
① 使用共享表空间存储:
这种方式创建的表结构保存在.frm文件中,数据和索引保存在innodb_data_home_dir和innodb_data_file_path定义的表空间中,可以是多个文件。
② 使用多表空间存储:
这种方式创建的表结构仍然保存在.frm文件中,但是每个表的数据和索引单独保存在.idb文件中。如果是个分区表,则每个分区对应单独的.idb文件,文件名是“表名+分区名”,可以在创建分区的时候指定每个分区的数据文件的位置,以此来将表的IO均匀分布在多个磁盘上。
要使用多表空间的存储方式,需要设置参数innodb_file_per_table并重启服务器后才可以生效,而且只对新建的表生效。多表空间的数据文件没有大小限制,不需要设置初始大小,也不需要设置文件的最大限制、扩展大小等参数。即使在多表空间的存储方式下,共享表空间仍然是必须的,InnoDB把内部数据词典和工作日志放在这个文件中,所以备份使用多表空间特性的表时直接复制.idb文件是不行的,可以通过命令将数据备份恢复到数据库中:
ALTER TABLE tbl_name DISCARD TABLESPACE; ALTER TABLE tbl_name IMPORT TABLESPACE;
但是这样只能恢复到表原来所在数据库中,如果需要恢复到其他数据库则需要通过mysqldump和mysqlimport来实现。
(3)数据文件
InnoDB的数据文件由表的存储方式决定。
① 共享表空间文件:由参数innodb_data_home_dir和innodb_data_file_path定义,用于存放数据词典和日志等。
② .frm:存放表结构定义,共享表空间存储与多表空间存储均有。
③ .idb:使用多表空间存储方式时,用于存放表数据和索引,若使用共享表空间存储则无此文件。
(4)外键约束
InnoDB是MySQL唯一支持外键约束的引擎。外键约束可以让数据库自己通过外键保证数据的完整性和一致性,但是引入外键会使速度和性能下降。在创建外键的时候,要求父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引。
(5)适用情况
如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询以外,还包括很多的更新、删除操作,那么InnoDB 存储引擎应该是比较合适的选择。InnoDB 存储引擎除了有效地降低由于删除和更新导致的锁定,还可以确保事务的完整提交和回滚,对于类似计费系统或者财务系统等对数据准确性要求比较高的系统,InnoDB 都是合适的选择。
2、MyISAM
(1)优缺点
优点:全文索引,非聚集索引、查询速度快。
缺点:不支持事务、不支持外键、仅仅支持表锁;数据库所在主机如果宕机,MyISAM的数据文件容易损坏,而且难恢复;。
(2)存储方式
① 静态表(默认):字段都是非变长的(每个记录都是固定长度的)。存储非常迅速、容易缓存,出现故障容易恢复;占用空间通常比动态表多。
② 动态表:占用的空间相对较少,但是频繁的更新删除记录会产生碎片,需要定期执行optimize table或myisamchk -r命令来改善性能,而且出现故障的时候恢复比较困难。
静态表的数据在存储的时候会按照列的宽度定义补足空格,在返回数据给应用之前去掉这些空格。如果需要保存的内容后面本来就有空格,在返回结果的时候也会被去掉。(其实是数据类型char的行为,动态表中若有这个数据类型也同样会有这个问题)
(静态表和动态表是根据正使用的列的类型自动选择的。)
(3)数据文件
MyISAM数据表在磁盘存储成3个文件,其文件名都和表名相同,扩展名分别是:
① .frm:存储数据表结构定义。
② .MYD:存储表数据。
③ .MYI:存储表索引。
其中,数据文件和索引文件可以放置在不同的目录,平均分布IO,获得更快的速度。指定索引文件和数据文件的路径,需要在创建表的时候通过data directory和index directory语句指定。(文件路径需要是绝对路径并且具有访问的权限)
MyISAM类型的表可能会损坏,原因可能是多种多样的,损坏后的表可能不能访问,会提示需要修复或者访问后返回错误的结果。可以使用check table语句来检查MyISAM表的健康,并用repair table语句修复已经损坏的MyISAM表。
frm和MYI可以存放在不同的目录下。MYI文件用来存储索引,但仅保存记录所在页的指针,索引的结构是B+树结构。下面这张图就是MYI文件保存的机制:

从这张图可以发现,这个存储引擎通过MYI的B+树结构来查找记录页,再根据记录页查找记录。并且支持全文索引、B树索引和数据压缩。
(4)适用情况
如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常适合的。MyISAM 是在Web、数据仓库和其他应用环境下最常使用的存储引擎之一。
3、MEMORY
(1)优缺点
优点:①分离静态的和动态的数据,②利用结构接近的数据来优化查询,③查询时可以访问更少的数据,④更容易维护大数据集,⑤可以通过修改.mrg文件来修改merge表,当然也可以用alter进行修改,修改后要通过flush tables刷新表缓存,此法可以动态增加减少子表,⑥Memory存储引擎将表的数据存放在内存中,能像会话或缓存一样方便操作和管理,充分发挥内存引擎的特点——速度快,延迟低;仅仅读或写为主的访问模式。
缺点:一旦服务关闭,表中的数据就会丢失;对表的大小有限制。
(2)存储方式
数据存放在内存中。
(3)数据文件
每个MEMORY表只对应一个.frm磁盘文件,用于存储表的结构定义,表数据存放在内存中。默认使用HASH索引,而不是BTREE索引。
(4)适用情况
Memory存储引擎主要用在那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果。
4、MRG_MYISAM (MERGE)
(1)引擎原理
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询、更新、删除的操作,这些操作实际上是对内部的实际的MyISAM表进行的。
通过insert_method子句定义merge表的插入操作:使用first或last可以使插入操作被相应地作用在第一或最后一个表上,不定义或定义为No表示不能对这个merge表进行插入操作。对merge表进行drop操作只是删除了merge的定义,对内部的表没有任何影响。
(2)存储方式
(3)数据文件
① .frm:存储表定义。
② .MRG:存储组合表的信息,包括merge表由哪些表组成、插入新数据时的依据。可以通过修改.mrg文件来修改merge表,但是修改后要通过flush tables刷新。
(4)适用情况
用于将一系列等同的MyISAM 表以逻辑方式组合在一起,并作为一个对象引用它们。MERGE 表的优点在于可以突破对单个MyISAM 表大小的限制,并且通过将不同的表分布在多个磁盘上,可以有效地改善MERGE 表的访问效率。这对于诸如数据仓储等VLDB环境十分适合。
5、ARCHIVE
Archive存储引擎基本上用于数据归档;它的压缩比非常的高,存储空间大概是InnoDB的10-15分之一所以它用来存储历史数据非常的适合,由于它不支持索引同时也不能缓存索引和数据,所以它不适合作为并发访问表的存储引擎。archive存储引擎使用行锁来实现高并发插入操作,但是它不支持事务,其设计目标只是提供高速的插入和压缩功能。
6、BLACKHOLE
黑洞引擎,学习过网络的同学大概听过黑洞路由器,在Linux系统中接触过/dev/null,这个引擎和这一样,表不保存数据库,主要作用是如果主被模式slave节点过多,通过blachole减轻master的压力。
7、FEDERATED
主要是用于和远程数据库链接的引擎
8、CSV
CSV存储引擎可以将CSV文件作为MySQL的表进行处理。存储格式就是普通的CSV文件
特点:①以CSV格式进行数据存储、②所有的列必须都是不能为null的、③不支持索引,不适合大表,不适合在线处理、④可以对数据文件直接编辑
9、PERFORMANCE_SCHEMA
10、NDB
(也称为NDBCLUSTER)-此集群数据库引擎特别适合于需要最高正常运行时间和可用性的应用程序。
参考链接:
https://zhidao.baidu.com/question/942624256925786012.html
https://blog.csdn.net/qq_42534026/article/details/106197607
https://www.jb51.net/article/139110.htm
https://baijiahao.baidu.com/s?id=1655327558614401593&wfr=spider&for=pc
