一.数组浅拷贝(2020年8月10号)
方法一:
Array.prototype.slice() Array.prototype.concat()
这两种方法都可以返回一个新的数组


let user = [{name: "leo"}, {age: 18}];
let user1 = [{age: 20},{addr: "fujian"}];
let user2 = user.concat(user1);
user1[0]["age"] = 25;
console.log(user); // [{"name":"leo"},{"age":18}]
console.log(user1); // [{"age":25},{"addr":"fujian"}]
console.log(user2); // [{"name":"leo"},{"age":18},{"age":25},{"addr":"fujian"}]
注意:但是对于属性的值是对象的话只会拷贝一份相同的内存地址
方法二:拓展运算符(...)
语法:var cloneObj = { ...obj };扩展运算符也是浅拷贝,对于值是对象的属性无法完全拷贝成2个不同对象,但是如果属性都是基本类型的值的话,使用扩展运算符也是优势方便的地方
let user = { name: "leo", skill: { JavaScript: 90, CSS: 80}};
let leo = {...user};
leo.name = "leo1";
leo.skill.CSS = 90;
console.log(leo.name); // "leo1" ⚠️ 差异!
console.log(user.name); // "leo" ⚠️ 差异!
console.log(leo.skill.CSS); // 90
console.log(user.skill.CSS);// 90
上面注意差异存在的地方
手写浅拷贝
实现原理:新的对象复制已有对象中非对象属性的值和对象属性的「引用」,也就是说对象属性并不复制到内存。
function cloneShallow(source) { let target = {}; for (let key in source) { if (Object.prototype.hasOwnProperty.call(source, key)) { target[key] = source[key]; } } return target; }
- 「for in」
for...in语句以任意顺序遍历一个对象自有的、继承的、可枚举的、非Symbol的属性。对于每个不同的属性,语句都会被执行。
- 「hasOwnProperty」
该函数返回值为布尔值,所有继承了 Object 的对象都会继承到 hasOwnProperty 方法,和 in 运算符不同,该函数会忽略掉那些从原型链上继承到的属性和自身属性。语法:obj.hasOwnProperty(prop)prop 是要检测的属性「字符串名称」或者Symbol。
二 :深拷贝
1. JSON.parse(JSON.stringify())
其原理是把一个对象序列化成为一个JSON字符串,将对象的内容转换成字符串的形式再保存在磁盘上,再用JSON.parse() 反序列化将JSON字符串变成一个新的对象。
但是使用 JSON.stringify() 使用注意:
- 拷贝的对象的值中如果有函数,
undefined,symbol则经过JSON.stringify()`序列化后的JSON字符串中这个键值对会消失; - 无法拷贝不可枚举的属性,无法拷贝对象的原型链;
- 拷贝
Date引用类型会变成字符串; - 拷贝
RegExp引用类型会变成空对象; - 对象中含有
NaN、Infinity和-Infinity,则序列化的结果会变成null; - 无法拷贝对象的循环应用(即
obj[key] = obj)。
2.手写深拷贝
核心思想是「递归」,遍历对象、数组直到里边都是基本数据类型,然后再去复制,就是深度拷贝。实现代码:
const isObject = obj => typeof obj === 'object' && obj != null; function cloneDeep(source) { if (!isObject(source)) return source; // 非对象返回自身 const target = Array.isArray(source) ? [] : {}; for(var key in source) { if (Object.prototype.hasOwnProperty.call(source, key)) { if (isObject(source[key])) { target[key] = cloneDeep(source[key]); // 注意这里 } else { target[key] = source[key]; } } } return target; }
该方法缺陷:遇到循环引用,会陷入一个循环的递归过程,从而导致爆栈。其他写法,可以阅读《如何写出一个惊艳面试官的深拷贝?》 。
总结:
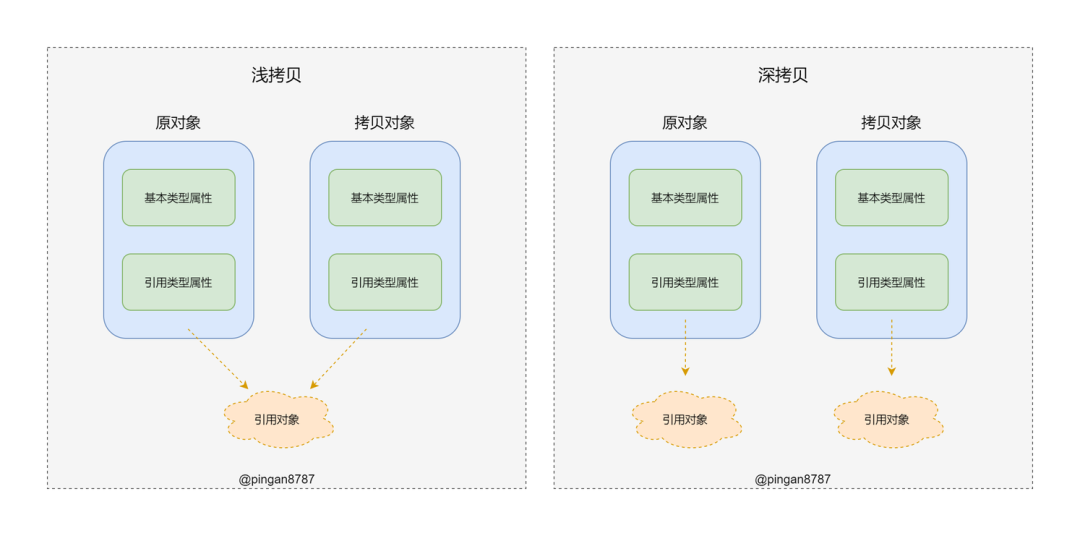
「浅拷贝」:将对象的每个属性进行依次复制,但是当对象的属性值是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
「深拷贝」:复制变量值,对于引用数据,则递归至基本类型后,再复制。深拷贝后的对象「与原来的对象完全隔离」,互不影响,对一个对象的修改并不会影响另一个对象。
「深拷贝和浅拷贝是针对复杂数据类型来说的,浅拷贝只拷贝一层,而深拷贝是层层拷贝。」
更多详细内容 查看文章:前端自测清单