原文链接:http://www.one2know.cn/keras1/
原文链接:http://www.one2know.cn/keras2/
keras介绍与基本的模型保存
- 思维导图
1.keras网络结构

2.keras网络配置

3.keras预处理功能
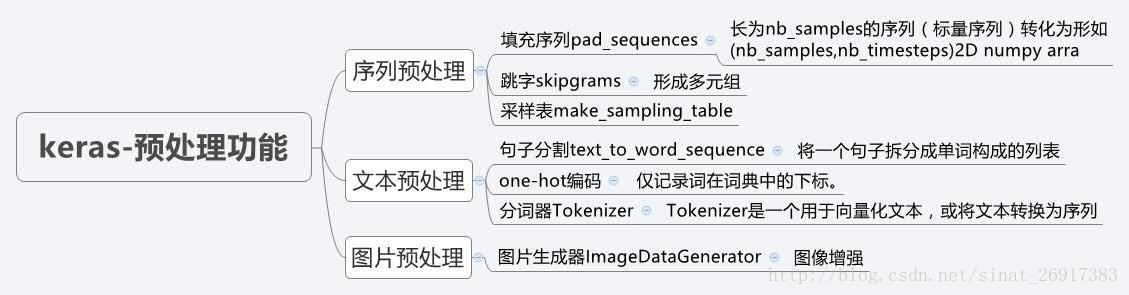
- 模型的节点信息提取
config = model.get_config()把model中的信息,solver.prototext和train.prototext信息提取出来
model = Model.from_config(config)用信息建立新的模型对象
model = Sequential.from_config(config)用信息建立新的Sequential模型对象 - 模型概况查询
1.模型概况打印
model.summary()
2.返回代表模型的JSON字符串,仅包含网络结构,不包含权值
from keras.models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)
3.model.to_yaml:与model.to_json类似,同样可以从产生的YAML字符串中重构模型
from keras.models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)
4.权重获取
model.get_layer()依据层名或下标获得层对象
model.get_weights()返回模型权重张量的列表,类型为numpy.array
model.set_weights()从numpy.array里将权重载入给模型,要求数组具有与model.get_weights()相同的形状
model.layers查看layer信息 - 模型保存与加载
model.save_weights(filepath=filepath)保存权重,文件类型HDF5,后缀.h5
model.load_weights(filepath, by_name=False)加载权重到当前模型,设置by_name=True,则只有名字匹配的层才会载入权重 - 在keras中设置GPU使用的大小,使用keras时候会出现总是占满GPU显存的情况,可以通过重设backend的GPU占用情况来进行调节
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config)) - 更科学地模型训练与模型保存
filepath = 'model-ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5'
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
model.fit(x, y, epochs=20, verbose=2, callbacks=[checkpoint], validation_data=(x, y))
如果val_loss 提高了就会保存,没有提高就不会保存 - 在keras中使用tensorboard
tensorboard能将keras的训练过程动态的、直观的显示出来
原理:keras的在训练(fit)的过程中,显式地生成log日志;使用tf的tensorboard来解析这个log日志,并且通过网站的形式显示出来
RUN = RUN + 1 if 'RUN' in locals() else 1 # locals() 函数会以字典类型返回当前位置的全部局部变量。
LOG_DIR = model_save_path + '/training_logs/run{}'.format(RUN)
LOG_FILE_PATH = LOG_DIR + '/checkpoint-{epoch:02d}-{val_loss:.4f}.hdf5' # 模型Log文件以及.h5模型文件存放地址
tensorboard = TensorBoard(log_dir=LOG_DIR, write_images=True)
checkpoint = ModelCheckpoint(filepath=LOG_FILE_PATH, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1)
history = model.fit_generator(generator=gen.generate(True),steps_per_epoch=int(gen.train_batches / 4),validation_data=gen.generate(False), validation_steps=int(gen.val_batches / 4),epochs=EPOCHS, verbose=1,callbacks=[tensorboard, checkpoint, early_stopping])
EarlyStopping patience:当early
(1)stop被激活(如发现loss相比上一个epoch训练没有下降),则经过patience个epoch后停止训练。
(2)mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值停止下降则中止训练。在max模式下,当检测值不再上升则停止训练。
模型检查点ModelCheckpoint
(1)save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
(2)mode:‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
(3)save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
(4)period:CheckPoint之间的间隔的epoch数
可视化tensorboard write_images: 是否将模型权重以图片的形式可视化
Sequential模型
- Sequential模型,即序贯模型,为最简单的线性、从头到脚的结构顺序,不分叉
- 基本组件
model.add添加层model.compile模型训练的BP模式设置model.fit模型训练参数设置和训练- 模型评估
- 模型预测
- add:添加层,train_val.prototxt文件
add(self,layer)
例子:
model.add(Dense(32,activation='relu',input_dim=100))
model.add(Dropout(0.25))
除了加层layer,还可以加其他模型add(self,other_model) - compile:训练模式,solver.prototxt文件
compile(self, optimizer, loss, metrics=None, sample_weight_mode=None)
参数:
optimizer:字符串(预定义优化器名)或优化器对象,参考优化器
loss:字符串(预定义损失函数名)或目标函数,参考损失函数
metrics:列表,包含评估模型在训练和测试时的网络性能的指标,典型用法是metrics=[‘accuracy’]
sample_weight_mode:如果你需要按时间步为样本赋权(2D权矩阵),将该值设为“temporal”。默认为“None”,代表按样本赋权(1D权)。在下面fit函数的解释中有相关的参考内容。
kwargs: 使用TensorFlow作为后端请忽略该参数,若使用Theano作为后端,kwargs的值将会传递给 K.function - fit:模型训练,train.sh+soler.prototxt(部分)
fit(self, x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
参数:
x:输入数据,如果模型只有一个输入,那么x的类型是numpy.array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy.array
y:标签,numpy.array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练的轮数,每个epoch会把训练集轮一遍。
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)的tuple,是指定的验证集,此参数将覆盖validation_spilt
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy.array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加sample_weight_mode=’temporal’。
initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。 - evaluate:模型评估
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
本函数按batch计算在某些输入数据上模型的误差,其参数有:
x:输入数据,与fit一样,是numpy.array或numpy.array的list
y:标签,numpy.array
batch_size:整数,含义同fit的同名参数
verbose:含义同fit的同名参数,但只能取0或1
sample_weight:numpy.array,含义同fit的同名参数 - predict:模型评估
predict(self, x, batch_size=32, verbose=0)
predict_classes(self, x, batch_size=32, verbose=1)
predict_proba(self, x, batch_size=32, verbose=1)
本函数按batch获得输入数据对应的输出,其参数有:
函数的返回值是预测值的numpy.array
predict_classes:本函数按batch产生输入数据的类别预测结果
predict_proba:本函数按batch产生输入数据属于各个类别的概率 - on_batch:batch的结果,检查
train_on_batch(self, x, y, class_weight=None, sample_weight=None)
test_on_batch(self, x, y, sample_weight=None)
predict_on_batch(self, x)
参数:
train_on_batch:本函数在一个batch的数据上进行一次参数更新,函数返回训练误差的标量值或标量值的list,与evaluate的情形相同。
test_on_batch:本函数在一个batch的样本上对模型进行评估,函数的返回与evaluate的情形相同
predict_on_batch:本函数在一个batch的样本上对模型进行测试,函数返回模型在一个batch上的预测结果 - fit_generator,利用迭代器训练
利用Python的生成器,逐个生成数据的batch并进行训练。
生成器与模型将并行执行以提高效率。
例如,该函数允许我们在CPU上进行实时的数据提升,同时在GPU上进行模型训练
参考链接:http://keras-cn.readthedocs.io/en/latest/models/sequential/
有了该函数,图像分类训练任务变得很简单。
fit_generator(self, generator, steps_per_epoch, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_q_size=10, workers=1, pickle_safe=False, initial_epoch=0)
def generate_arrays_from_file(path):
while 1:
f = open(path)
for line in f:
# 在每行 创建输入数据和标签的array数组
x, y = process_line(line)
yield (x, y)
f.close()
model.fit_generator(generate_arrays_from_file('/my_file.txt'),samples_per_epoch=10000, epochs=10)
其他的两个辅助的内容:
evaluate_generator(self, generator, steps, max_q_size=10, workers=1, pickle_safe=False)
predict_generator(self, generator, steps, max_q_size=10, workers=1, pickle_safe=False, verbose=0)
evaluate_generator:本函数使用一个生成器作为数据源评估模型,生成器应返回与test_on_batch的输入数据相同类型的数据。该函数的参数与fit_generator同名参数含义相同,steps是生成器要返回数据的轮数。
predcit_generator:本函数使用一个生成器作为数据源预测模型,生成器应返回与test_on_batch的输入数据相同类型的数据。该函数的参数与fit_generator同名参数含义相同,steps是生成器要返回数据的轮数。
案例一:简单的二分类
from keras.models import Sequential
from keras.layers import Dense,Activation
# 建立模型
model = Sequential() # 初始化
model.add(Dense(32,activation='relu',input_dim=100))
# Dense代表全连接,有32个全连接层,最后接relu,输入的是100维
model.add(Dense(1,activation='sigmoid')) # 添加新的全连接层
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
# compile,跟prototxt一样,一些训练参数,solver.prototxt
# 生成数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# 训练数据
model.fit(data, labels, batch_size=32, nb_epoch =10,verbose=1)
# 版本1.2里面是nb_epoch ,而keras2.0是epochs
print(model.summary())
输出:
Using TensorFlow backend.
WARNING:tensorflow:From D:Python37Libsite-packages ensorflowpythonframeworkop_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
D:/PyCharm 5.0.3/WorkSpace/3.Keras/1.Sequential与Model模型、Keras基本结构功能/1.py:18: UserWarning: The `nb_epoch` argument in `fit` has been renamed `epochs`.
model.fit(data, labels, batch_size=32, nb_epoch =10,verbose=1)
WARNING:tensorflow:From D:Python37Libsite-packages ensorflowpythonopsmath_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/10
2019-07-08 12:12:29.800285: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
32/1000 [..............................] - ETA: 6s - loss: 0.7047 - acc: 0.5000
1000/1000 [==============================] - 0s 229us/step - loss: 0.7101 - acc: 0.5080
Epoch 2/10
省略了一堆epoch
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 32) 3232
_________________________________________________________________
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 3,265
Trainable params: 3,265
Non-trainable params: 0
_________________________________________________________________
None
案例二:多分类-VGG的卷积神经网络
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten
from keras.layers import Conv2D,MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
# 生成数据
x_train = np.random.random((100,100,100,3))
# 100张图片 每张100*100*3
y_train = keras.utils.to_categorical(np.random.randint(10,size=(100,1)),num_classes=10)
# 100*10
x_test = np.random.random((20,100,100,3))
y_test = keras.utils.to_categorical(np.random.randint(10,size=(20,1)),num_classes=10)
# 20*100
# keras.utils.to_categorical 将一列数字转化为keras格式的额一堆类
model = Sequential()
# input: 100x100 images with 3 channels -> (110,100,3) tensore.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32,(3,3),activation='relu',input_shape=(100,100,3)))
model.add(Conv2D(32,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))
sgd = SGD(lr=0.01,decay=1e-6,momentum=0.9,nesterov=True)
model.compile(loss='categorical_crossentropy',optimizer=sgd)
model.fit(x_train,y_train,batch_size=32,epochs=10)
score = model.evaluate(x_test,y_test,batch_size=32)
Model式模型
- 比序贯模型要复杂,但是效果很好,可以同时/分阶段输入变量,分阶段输出想要的模型,函数式模型
- 函数式模型基本属性与训练流程
- model.layers,添加层信息
- model.compile,模型训练的BP模式设置
- model.fit,模型训练参数设置和训练
- evaluate,模型评估
- predict,模型预测
- 常用Model属性
model.layers:组成模型图的各个层
model.inputs:模型的输入张量列表
model.outputs:模型的输出张量列表 - compile 训练模式设置——solver.prototxt
compile(self, optimizer, loss, metrics=None, loss_weights=None, sample_weight_mode=None)
参数:
optimizer:优化器,为预定义优化器名或优化器对象,参考优化器
loss:损失函数,为预定义损失函数名或一个目标函数,参考损失函数
metrics:列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[‘accuracy’]如果要在多输出模型中为不同的输出指定不同的指标,可像该参数传递一个字典,例如metrics={‘ouput_a’: ‘accuracy’}
sample_weight_mode:如果你需要按时间步为样本赋权(2D权矩阵),将该值设为“temporal”。默认为“None”,代表按样本赋权(1D权) - fit 模型训练参数设置和训练
fit(self, x=None, y=None, batch_size=32, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
参数:
x:输入数据,如果模型只有一个输入,那么x的类型是numpy.array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy.array,如果模型的每个输入都有名字,则可以传入一个字典,将输入名与其输入数据对应起来。
y:标签,numpy.array。如果模型有多个输出,可以传入一个numpy.array的list。如果模型的输出拥有名字,则可以传入一个字典,将输出名与其标签对应起来。
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
nb_epoch:整数,训练的轮数,训练数据将会被遍历nb_epoch次。Keras中nb开头的变量均为”number of”的意思
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之后,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)或(X,y,sample_weights)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
shuffle:布尔值,表示是否在训练过程中每个epoch前随机打乱输入样本的顺序。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。
sample_weight:权值的numpy.array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
输入数据与规定数据不匹配时会抛出错误
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况 - evaluate,模型评估
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
参数:
x:输入数据,与fit一样,是numpy.array或numpy.array的list
y:标签,numpy.array
batch_size:整数,含义同fit的同名参数
verbose:含义同fit的同名参数,但只能取0或1
sample_weight:numpy.array,含义同fit的同名参数
本函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的list(如果模型还有其他的评价指标),model.metrics_names将给出list中各个值的含义 - predict 模型预测
predict(self, x, batch_size=32, verbose=0) - 模型检查
_on_batch
train_on_batch(self, x, y, class_weight=None, sample_weight=None)
test_on_batch(self, x, y, sample_weight=None)
predict_on_batch(self, x)
train_on_batch:本函数在一个batch的数据上进行一次参数更新,函数返回训练误差的标量值或标量值的list,与evaluate的情形相同。
test_on_batch:本函数在一个batch的样本上对模型进行评估,函数的返回与evaluate的情形相同;
predict_on_batch:本函数在一个batch的样本上对模型进行测试,函数返回模型在一个batch上的预测结果 _generator
fit_generator(self, generator, steps_per_epoch, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_q_size=10, workers=1, pickle_safe=False, initial_epoch=0)
evaluate_generator(self, generator, steps, max_q_size=10, workers=1, pickle_safe=False)
案例一:简单的单层-全连接网络
from keras.layers import Input,Dense
from keras.models import Model
from keras.utils import to_categorical
import numpy as np
data = np.random.random((100,100,3))
data = data.reshape(len(data),-1)
labels = to_categorical(np.random.randint(10,size=(100,1)),num_classes=10)
inputs = Input(shape=(300,)) # 返回一个张量
x = Dense(64,activation='relu')(inputs) # inputs代表输入,x代表输出
x = Dense(64,activation='relu')(x) #输入x,输出x
predictions = Dense(10,activation='softmax')(x) # 输入x,输出分类
# This creates a model that includes the Input layer and three Dense layers
model = Model(inputs=inputs,outputs=predictions)
# 该句是函数式模型的经典,可以同时输入两个input,然后输出output两个模型
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
# 开始训练
model.fit(data,labels,epochs=3,batch_size=32)
输出:
Using TensorFlow backend.
WARNING:tensorflow:From D:Python37Libsite-packages ensorflowpythonframeworkop_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From D:Python37Libsite-packages ensorflowpythonopsmath_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
2019-07-08 16:47:48.627213: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Epoch 1/3
32/100 [========>.....................] - ETA: 0s - loss: 2.4095 - acc: 0.0625
100/100 [==============================] - 0s 2ms/step - loss: 2.3387 - acc: 0.1000
Epoch 2/3
32/100 [========>.....................] - ETA: 0s - loss: 2.2108 - acc: 0.2188
100/100 [==============================] - 0s 50us/step - loss: 2.2436 - acc: 0.1900
Epoch 3/3
32/100 [========>.....................] - ETA: 0s - loss: 2.1684 - acc: 0.1250
100/100 [==============================] - 0s 50us/step - loss: 2.1797 - acc: 0.2300
案例二:视频处理
from keras.layers import Input,Dense
from keras.models import load_model
model = load_model('xxxx.h5')
x = Input(shape=(784,)) # This works, and returns the 10-way softmax we defined above.
y = model(x) # model是训练好的,现在用来做迁移学习
# model里存着权重,输入x,输出结果,用来作fine-tuning
from keras.layers import TimeDistributed
input_sequences = Input(shape=(20,784))
processed_sequences = TimeDistributed(model)(input_sequences)
案例三:双输入、双模型输出:LSTM 时序预测
通过本案例可以了解到Model的精髓在于他的任意性,给编译者很多的便利。
输入:
新闻语料;新闻语料对应的时间
输出:
新闻语料的预测模型;新闻语料+对应时间的预测模型
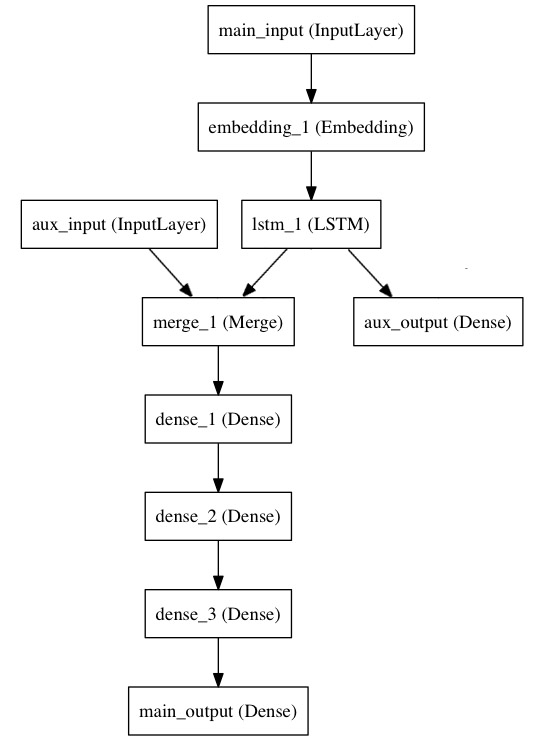
### 模型一:只针对新闻语料的LSTM模型
from keras.layers import Input,Embedding,LSTM,Dense
from keras.datasets import reuters
from keras.utils import to_categorical
(headline_data, additional_data), (labels, labels) = reuters.load_data(num_words=10000)
labels = to_categorical(labels,num_classes=46)
# 标题输入:用于接收100个整数的序列,介于1和10000之间
main_input = Input(shape=(1,),dtype='int32',name='main_input')
# 注意:我们可以通过传递一个“name”参数来命名任何层
# 一个100词的BOW序列
# 这个嵌入层将输入序列编码成一个密集的512维向量序列
# Embedding层,把100维度再encode成512的句向量,10000指的是词典单词总数
x = Embedding(output_dim=512,input_dim=10000,input_length=1)(main_input)
# LSTM将把向量序列转换为单个向量,包含关于整个序列的信息。
lstm_out = LSTM(32)(x) # units=32,正整数,输出空间的维数
#然后,我们插入一个额外的损失,使得即使在主损失很高的情况下,LSTM和Embedding层也可以平滑的训练
auxiliary_output = Dense(1,activation='sigmoid',name='aux_output')(lstm_out)
#再然后,我们将LSTM与额外的输入数据串联起来组成输入,送入模型中
### 模型二:组合模型 新闻语料+时序
import keras
from keras.models import Model
auxiliary_output = Input(shape=(5,),name='aux_input') # 新加入的一个Input,维度=5
x = keras.layers.concatenate([lstm_out,auxiliary_output]) # 组合起来,对应起来
# 我们在上面堆了一个深度密集连接的网络 组合模型的形式
x = Dense(64,activation='relu')(x)
x = Dense(64,activation='relu')(x)
x = Dense(64,activation='relu')(x)
# 最后我们添加了主要的逻辑回归层
main_output = Dense(1,activation='sigmoid',name='main_output')(x)
# 最后,我们定义整个2输入,2输出的模型
model = Model(inputs=[main_input,auxiliary_output],outputs=[main_output,auxiliary_output])
# 模型定义完毕,下一步编译模型
# 我们给额外的损失赋0.2的权重,我们可以通过关键字参数loss_weights或loss来为不同的输出设置不同的损失函数或权值
# 这两个参数均可为Python的列表或字典,这里我们给loss传递单个损失函数,这个损失函数会被应用于所有输出上
# 训练方式一:两个模型 一个loss
model.compile(optimizer='rmsprop', loss='binary_crossentropy',loss_weights=[1., 0.2])
model.fit([headline_data, additional_data], [labels, labels],epochs=50, batch_size=32)
# # 训练方式二:两个模型 两个Loss
# model.compile(optimizer='rmsprop',
# loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
# loss_weights={'main_output': 1., 'aux_output': 0.2})
# # And trained it via:
# model.fit({'main_input': headline_data, 'aux_input': additional_data},
# {'main_output': labels, 'aux_output': labels},
# epochs=50, batch_size=32)
案例四:共享层:对应关系、相似性
- 一个节点,分成两个分支出去
import keras
from keras.layers import Input,LSTM,Dense
from keras.models import Model
tweet_a = Input(shape=(140,256)) # 140个单词,每个单词256维度,词向量
tweet_b = Input(shape=(140,256))
# 若要对不同的输入共享同一层,就初始化该层一次,然后多次调用它
# 该层可以将矩阵作为输入,并返回大小为64的向量
shared_lstm = LSTM(64)
# 当我们多次重用同一层实例时,层的权重也将被重用(有效相同层)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# 连接两个结果
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# 在顶部添加逻辑回归
predictions = Dense(1, activation='sigmoid')(merged_vector)
# 我们定义了一个可训练的模型,将tweet输入与预测相连接
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=10) # 训练
案例五:抽取层节点内容
# 1.单节点
from keras.layers import Input,LSTM,Dense
from keras.layers import Conv2D
a = Input(shape=(140,256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a
# 抽取获得encoded_a的输出张量
# 2.多节点
a = Input(shape=(140,256))
b = Input(shape=(140,256))
lstm = LSTM(32)
encoded_a = lstm(a)
encoded_b = lstm(b)
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b
# 3.图像层节点
# 对于input_shape和output_shape也是一样,如果一个层只有一个节点,或所有的节点都有相同的输入或输出shape,那么input_shape和output_shape都是没有歧义的,并也只返回一个值。但是,例如你把一个相同的Conv2D应用于一个大小为(3,32,32)的数据,然后又将其应用于一个(3,64,64)的数据,那么此时该层就具有了多个输入和输出的shape,你就需要显式的指定节点的下标,来表明你想取的是哪个了
a = Input(shape=(3, 32, 32))
b = Input(shape=(3, 64, 64))
conv = Conv2D(16, (3, 3), padding='same')
conved_a = conv(a)
# Only one input so far, the following will work:
assert conv.input_shape == (None, 3, 32, 32)
conved_b = conv(b)
# now the `.input_shape` property wouldn't work, but this does:
assert conv.get_input_shape_at(0) == (None, 3, 32, 32)
assert conv.get_input_shape_at(1) == (None, 3, 64, 64)
案例六:视觉问答模型
# 这个模型将自然语言的问题和图片分别映射为特征向量,
# 将二者合并后训练一个logistic回归层,从一系列可能的回答中挑选一个。
from keras.layers import Conv2D,MaxPooling2D,Flatten
from keras.layers import Input,LSTM,Embedding,Dense
from keras.models import Model,Sequential
import keras
# 首先,让我们使用顺序模型定义一个视觉模型。
# 该模型将图像编码为矢量。
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3),activation='relu', padding='same', input_shape=(3, 224, 224)))
vision_model.add(Conv2D(64, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(128, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
# 视觉模型的输出得到张量:
image_input = Input(shape=(3, 224, 224))
encoded_image = vision_model(image_input)
# 接下来,我们定义一个语言模型,将问题编码为向量。
# 每个问题的长度最多为100个字,我们将把单词索引为1到9999之间的整数。
question_input = Input(shape=(100,), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# 将问题向量和图像向量连接起来:
merged = keras.layers.concatenate([encoded_question, encoded_image])
# 训练一个超过1000个单词的逻辑回归:
output = Dense(1000, activation='softmax')(merged)
# 最终的模型:
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
fine-tuning时如何加载No_top的权重
- 如果你需要加载权重到不同的网络结构(有些层一样)中,例如fine-tune或transfer-learning,你可以通过层名字来加载模型:
model.load_weights(‘my_model_weights.h5’, by_name=True)
原模型:
model = Sequential()
model.add(Dense(2, input_dim=3, name="dense_1"))
model.add(Dense(3, name="dense_2"))
...
model.save_weights(fname)
新模型:
# new model
model = Sequential()
model.add(Dense(2, input_dim=3, name="dense_1")) # will be loaded
model.add(Dense(10, name="new_dense")) # will not be loaded
# load weights from first model; will only affect the first layer, dense_1.
model.load_weights(fname, by_name=True)