ORM、SQLAchemy
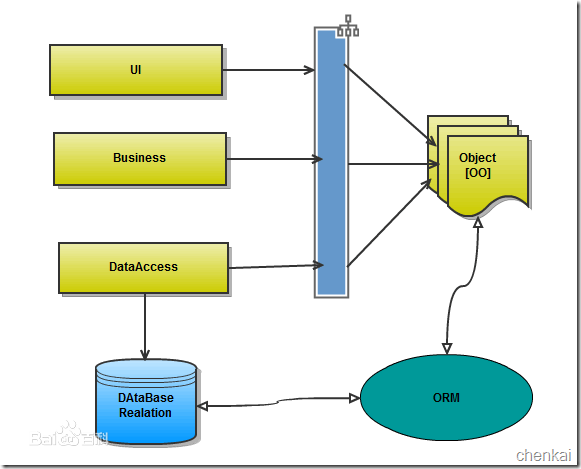
orm英文全称object relational mapping,就是对象映射关系程序,简单来说就是类似python这种面向对象的程序来说一切皆对象,但是使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作:
更多数据库ORM链接方式资料:查看
1、安装
|
1
|
pip3 install SQLAlchemy |
2、创建sql表
2.1、原本创建sql表命令
2.2、使用sqlalchemy创建表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, Stringconnect = create_engine("mysql+pymysql://root:123456@localhost:3306/mysql", encoding="utf-8", echo=True) # 连接数据库,echo=True =>把所有的信息都打印出来Base = declarative_base() # 生成ORM基类class User(Base): __tablename__ = "hello_word" # 表名 id = Column(Integer, primary_key=True) name = Column(String(32)) password = Column(String(64))Base.metadata.create_all(connect) # 创建表结构 |
2.3、sqlaicheym原始创建表的方式(2.2创建表的方式就是基于2.3的再封装,所以2.3基本这种方式基本不使用)
最基本的表建立好了之后,再建立与数据的Session会话连接,就可以进行增删查改等操作:
|
1
2
|
session_class = sessionmaker(bind=connect) # 创建与数据库的会话session class ,这里返回给session的是个class,不是实例session = session_class() # 生成session实例 |
3、增
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#新增一条数据#原生sql:insert into mysql.hello_word(name,password) values("test2","1234");obj = User(name="test", password="1234") #生成你要创建的数据对象session.add(obj) #把要创建的数据对象添加到这个session里, 一会统一创建session.commit() #统一提交,创建数据,在此之前数据库是不会有新增数据的#新增多条数据#原生sql:insert into mysql.hello_word(name,password) values("test2","1234"),("test3","123");obj = User(name="test", password="1234")obj1 = User(name="test", password="1234")session.add_all([obj,obj1])session.commit()<br><br>#回滚,在session.add()之后,在session.commit()之前,想把添加至session缓存中的数据清除,使用rollback()函数回滚即可<br>Session.rollback() |
|
1
|
|
4、删
|
1
2
3
|
#原生sql:mysql.hello_word where id > 5;session.query(User).filter(User.id > 5).delete() #通过session查询User类,然后过滤出id>5的进行删除session.commit() #提交 |
5、改
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#①第一种方式data = Session.query(User).filter_by(name="test1").first() #获取数据data.name = "test" #修改数据Session.commit() #提交#②第二种方式,通过查找表,过滤条件,然后更新对应参数session.query(User).filter(User.id > 15).update({"name": "test"})session.query(User).filter(User.id == 18).update({User.name: "hello"}, synchronize_session=False)session.query(User).filter_by(name="test1").update({User.password: User.name}, synchronize_session="evaluate")session.commit()#③synchronize_session解释,用于query在进行delete or update操作时,对session的同步策略:#1、synchronize_session=False,不对session进行同步,直接进行delete or update操作。#2、synchronize_session="evaluate",在delete or update操作之前,用query中的条件直接对session的identity_map中的objects进行eval操作,将符合条件的记录下来, 在delete or update操作之后,将符合条件的记录删除或更新。 |
6、查
6.1、几种查询方式的使用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#原生sql:select * from mysql.hello_word;ret = session.query(User).all() #查询所有#也可以这样写:ret = Session.query(User.name,User.id).all()#原生slq:select name,password from mysql.hello_word;ret = session.query(User.name, User.extra).all() #只查询name和extra字段所以所有数据#原生sql:select * from mysql.hello_word where name="test1";ret = session.query(User).filter_by(name='test1').all() #查询name='alex'的所有数据ret = session.query(User).filter_by(name='test1').first()#查询name='alex'的第一条数据#查询id>5的name字段内容,且以id大小排序#原生sql;select name from mysql.hello_word where id >5 order by id;ret = session.query(User).filter(text("id>:value and name=:name")).params(value=5, name='test2').order_by(User.id).all()#根据原生sql查询数据ret = session.query(User).from_statement(text("SELECT * FROM hello_word where name=:name")).params(name='test1').all() |
6.2、filter和filter_by使用的区别
|
1
2
3
4
|
#filter用于sql表达式查询过滤,如>,<, ==,等表达式session.query(MyClass).filter(MyClass.name == 'some name')#filter_by用于关键字查询过滤,如id=value,name=valuesession.query(MyClass).filter_by(name = 'some name') |
6.3、重构__repr__方法,将5.1 中ret内存对象按__repr__方法中定义的格式进行打印显示
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class User(Base): __tablename__ = "hello_word" # 表名 id = Column(Integer, primary_key=True) name = Column(String(32)) password = Column(String(64)) def __repr__(self): # 使返回的内存对象变的可读 return "<id:{0} name:{1} password:{2}>".format(self.id, self.name, self.password)#Base.metadata.create_all(connect) # 创建标结构session_class = sessionmaker(bind=connect) # 创建与数据库的会话session class ,这里返回给session的是个class,不是实例session = session_class() # 生成session实例user = session.query(User).all() #查询全部print(user)#输出[<id:1 name:test1 password:1234>, <id:2 name:test1 password:1234>, <id:8 name:test2 password:1234>, <id:9 name:test3 password:123>, <id:10 name:test4 password:123>, <id:11 name:test5 password:123>, <id:12 name:test2 password:1234>, <id:13 name:test3 password:123>, <id:14 name:test4 password:123>, <id:15 name:test5 password:123>, <id:16 name:test2 password:1234>, <id:17 name:test3 password:123>, <id:18 name:test4 password:123>, <id:19 name:test5 password:123>] |
7、其他操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#多条件查询#原生sql:select * from mysql.hello_word where id >2 and id < 19data = session.query(User).filter(Use.id>2).filter(Use.id<19).all()<br>#通配符#原生sql:select * from mysql.hello_word where name like "test%" #"test_"、%test%data = session.query(User).filter(User.name.like('test%')).all() #匹配以test开头,而后跟多个字符data = session.query(User).filter(User.name.like('test_')).all() #匹配以test开头,而后跟一个字符data = session.query(User).filter(~User.name.like('e%')).all() #加~后,忽略like(),直接匹配所有#原生sql select count(name) from mysql.hello_word where name like "%test%"data = session.query(User).filter(User.name.like("%qigao%")).count() # 模糊匹配并计数<br>#分组from sqlalchemy import func #导入func 进行函数操作#原生sql:select count(name),name from mysql.hello_word group by namedata =session.query(func.count(User.name),User.name).group_by(User.name).all() #根据User.name分组#原生sql:select max(id),sum(id),min(id) from mysql.hello_word group by name #根据name 分组data =session.query(func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).all()#原生sql:select max(id),sum(id),min(id) from mysql.hello_word group by name having min(id > 2) # 根据name分组且id>2data = session.query(func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).having(func.min(User.id) >2).all()<br><br>#排序#原生sql:select * from mysql.hello_word order by id ascdata = session.query(User).order_by(User.id.asc()).all() #将所有数据根据 “列” 从小到大排列#原生sql:select * from mysql.hello_word order by id desc, id ascdata = session.query(User).order_by(User.id.desc(), User.id.asc()).all()#将所有数据根据 “列1” 从大到小排列,如果相同则按照“列2”由小到大排列#条件表达式 in、between、 and 、ordata = session.query(User).filter_by(name='test').all()data = session.query(User).filter(User.id > 1, Users.name == 'test').all()data = session.query(User).filter(User.id.between(1, 3), Users.name == 'test').all()data = session.query(User).filter(User.id.in_([1,3,4])).all()data = session.query(User).filter(~User.id.in_([1,3,4])).all()data = session.query(User).filter(Users.id.in_(session.query(User.id).filter_by(name='test'))).all()from sqlalchemy import and_, or_data = session.query(User).filter(and_(User.id > 3, Users.name == 'test')).all()data = session.query(User).filter(or_(User.id < 2, Users.name == 'test')).all()data = session.query(User).filter(or_(User.id < 2,and_(User.name == 'test',User.id > 3),User.password != "")).all() |