一、自动化测试模型
1.线性测试
录制或编写对应应用程序操作步骤产生,每个线性脚本相互独立,相互之间不依赖,不调用彼此,即单纯地模拟用户完整操作场景。不易维护。
2.模块化与类库
将重复的操作单独封装成公共模块。在测试用例执行过程中,当需要用到模块封装时对其进行调用,如此一来便最大限度的消除了重复,从而提高测试用例的可维护性。
3.数据驱动测试
定义:数据的改变驱动自动化测试的执行,最终引起测试结果的改变。简单理解就是把数据驱动所需要的测试数据参数化,可以用多种方式来存储和管理这些参数化的数据(txt,html,csv,xml,json)
4.关键字驱动测试
又被称为【表驱动测试】或【基于动作字测试】。这类框架会把自动化操作封装为“关键字”,避免测试人员直接接触代码,多以“填表格”的形式降低脚本的编写难度。
Robot Framework是主流的关键字驱动测试框架之一,通过它自带的Robot Framework RIDE编写。
二、模块化与参数化
1.简单的一个文件线性测试
一般需要配合使用,即在创建函数或类方法时为它们设置入参,使其可以根据不同的参数执行相应的操作,下面以一个简单的126邮箱登录为例:
1 from selenium import webdriver 2 from time import sleep 3 4 driver = webdriver.Chrome() 5 driver.maximize_window() 6 driver.get("http://www.126.com") 7 # 登录 8 sleep(5) 9 10 login = driver.find_element_by_xpath("/html/body/div[2]/div[3]/div/div[3]/div[3]/div[4]/a[1]") 11 login.click() 12 driver.switch_to.frame(0) 13 """ 14 (driver.find_element_by_xpath("/html/body/div[2]/div[3]/div/div[3]/div[4]/div[1]/div/iframe")) 15 """ 16 sleep(3) 17 user = driver.find_element_by_name("email") 18 user.clear() 19 user.send_keys("zudangli") 20 driver.find_element_by_name("password").clear() 21 driver.find_element_by_name("password").send_keys("19820818kai") 22 driver.find_element_by_id("dologin").click() 23 # 登录之后的动作 24 sleep(3) 25 # 退出 26 driver.find_element_by_link_text("退出").click() 27 driver.quit()
<这里涉及到一个表单切换的问题,因为打开这个邮箱的网址后主页面显示的是扫码登录,要切换到账户密码登录的表单下,但是在尝试了多种定位iframe的方式之后(name、css_selector、xpath),切换是切换成功无疑了,因为可以找到该iframe下的元素,但就是不能执行操作,报错:(selenium.common.exceptions.ElementNotInteractableException: Message: element not interactable),也搜了很多办法,最终也无疾而终,最后只能在切换表单之前手动切换到账号登录的iframe下,暂时先这样解决吧,随着后面进一步的学习再回来看看是怎么费事!!!>
2.将重复的动作模块化
好了,言归正传,继续来康康如何一步步模块化……要实现邮箱的自动化登录测试项目,那每条测试用例都需要有登录动作和退出动作,此时,需要创建一个新的module.py文件存放登录和退出动作。
1 from time import sleep 2 3 4 class Mail: 5 6 def __init__(self, driver): 7 self.driver = driver 8 9 def login(self): 10 login = self.driver.find_element_by_xpath("/html/body/div[2]/div[3]/div/div[3]/div[3]/div[4]/a[1]") 11 login.click() 12 self.driver.switch_to.frame(0) 13 14 sleep(3) 15 user = self.driver.find_element_by_name("email") 16 user.clear() 17 user.send_keys("zudangli") 18 self.driver.find_element_by_name("password").clear() 19 self.driver.find_element_by_name("password").send_keys("19820818kai") 20 self.driver.find_element_by_id("dologin").click() 21 22 def logout(self): 23 self.driver.find_element_by_link_text("退出").click()
首先创建一个Mail类,在__init__()初始化方法中接收driver驱动并赋值给self.driver,在login()和logout()方法中分别使用self.driver实现邮箱的登录和退出动作,接下来修改test_mail.py测试调用Mail类中的这两个方法:
1 from selenium import webdriver 2 from time import sleep 3 4 from files.module import Mail 5 6 driver = webdriver.Chrome() 7 driver.maximize_window() 8 driver.get("http://www.126.com") 9 sleep(5) 10 # 调用Mail类并接受driver驱动 11 mail = Mail(driver) 12 # 登录 13 mail.login() 14 sleep(5) 15 # 退出 16 mail.logout() 17 driver.quit()
3.将模块中的方法参数化
接着再进一步,如果需求是测试登录功能,虽然测试步骤是固定的,但是测试数据(账号)不同,这时就需要把login()方法参数化。修改的module.py文件代码如下:
1 from time import sleep 2 3 4 class Mail: 5 6 def __init__(self, driver): 7 self.driver = driver 8 login = self.driver.find_element_by_xpath("/html/body/div[2]/div[3]/div/div[3]/div[3]/div[4]/a[1]") 9 login.click() 10 self.driver.switch_to.frame(0) 11 sleep(3) 12 13 def login(self, username, password): 14 sleep(2) 15 self.driver.find_element_by_name("email").clear() 16 self.driver.find_element_by_name("email").send_keys(username) 17 self.driver.find_element_by_name("password").clear() 18 self.driver.find_element_by_name("password").send_keys(password) 19 self.driver.find_element_by_id("dologin").click() 20 sleep(3) 21 22 def logout(self): 23 self.driver.find_element_by_link_text("退出").click()
(这里对Mail类中的初始化方法做了微调,由于考虑到各种测试案例下,只需要一次定位到iframe就将iframe的定位操作放到了初始化方法中)
这样就进一步提高了login()方法的可复用性,不再使用一个固定的账号登录,而是根据被调用者传来的用户名和密码执行登录操作,相应的修改测试用例test_mail.py文件:
1 driver = webdriver.Chrome() 2 driver.maximize_window() 3 driver.get("http://www.126.com") 4 sleep(5) 5 # 调用Mail类并接受driver驱动 6 mail = Mail(driver) 7 # 登录账号为空 8 mail.login("", "") 9 10 # 用户名为空 11 mail.login("", "19820818kai") 12 13 # 密码为空 14 mail.login("zudangli", "") 15 16 # 用户名密码错误 17 mail.login("error", "error") 18 19 # 正确的账号登录 20 mail.login("zudangli", "19820818kai") 21 mail.login("pegawayatstudying", "19970507zudangli") 22 # ……
4.读取数据文件
- txt文件
Python提供了一下几种读取txt问价的方法:
- read():读取整个文件
- readline():读取一行数据
- readlines():读取所有行的数据
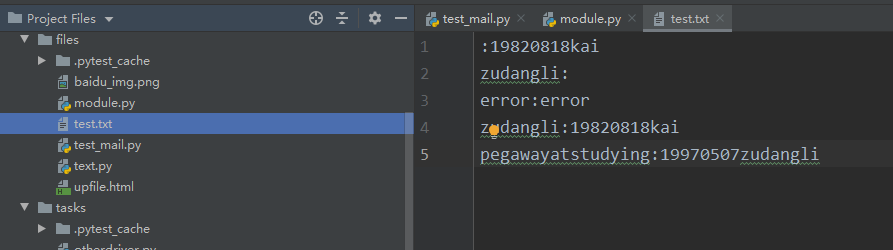
test.txt文件如下:
:19820818kai
zudangli:
error:error
zudangli:19820818kai
pegawayatstudying:19970507zudangli
创建read_txt.py文件,用于读取txt文件
1 # 读取文件 2 with(open("./test.txt", "r")) as user_file: 3 data = user_file.readlines() 4 5 # 格式化处理 6 users = [] 7 for line in data: 8 user = line[:-1].split(":") 9 users.append(user) 10 11 # 打印users二维数组 12 print(users)
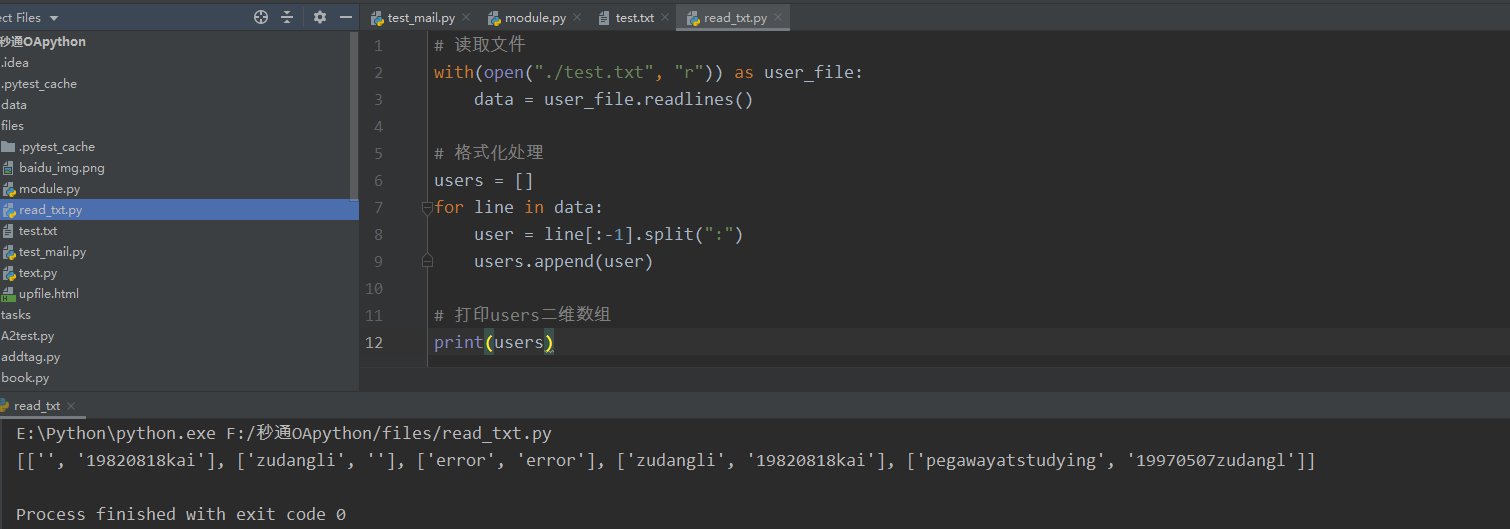
首先通过open()以读(“r”)的方式打开test.txt文件,readlines()可读取文件中的所有行并赋值给变量data。接下来循环data中的每一行数据,[:-1]可对字符串进行切片,以省略最后一个字符,因为读取的每一行数据结尾都有一个换行符“ ”。spilt()通过冒号(:)对每行数据进行拆分,会得到数组['','19820818kai'],最后使用append()把每一组用户名和密码追加到users数组中。取users数组中的数据,得到的数组用不同的用户名/密码进行登录,代码如下:
1 from selenium import webdriver 2 from time import sleep 3 from files.module import Mail 4 from files.read_txt import users 5 6 driver = webdriver.Chrome() 7 driver.maximize_window() 8 driver.get("http://www.126.com") 9 sleep(5) 10 # 调用Mail类并接受driver驱动 11 mail = Mail(driver) 12 # 登录账号为空 13 mail.login(users[0][0], users[0][1]) 14 15 # 用户名为空 16 mail.login(users[1][0], users[1][1]) 17 18 # 密码为空 19 mail.login(users[2][0], users[2][1]) 20 21 # 用户名密码错误 22 mail.login(users[3][0], users[3][1]) 23 24 # 正确的账号登录 25 mail.login(users[4][0], users[4][1]) 26 mail.login(users[5][0], users[5][1]) 27 # ……


- CSV文件
注:可以把WPS表格或Excel表格通过文件另存为CSV类型的文件,但不要直接修改文件的后缀名来创建CSV文件,因为这样的文件并非真正的CSV文件。这里遇到一个问题:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte。解决办法:https://blog.csdn.net/moledyzhang/article/details/78978312简单来说就是用记事本打开该文件,另存为时编码格式选择UTF-8即可
1 import codecs 2 import csv 3 from itertools import islice 4 5 # 读取本地CSV文件 6 data = csv.reader(codecs.open('./csv.csv', 'r', 'utf_8_sig')) 7 # 存放用户数据 8 users = [] 9 # 循环输出每行信息 10 for line in islice(data, 1, None): 11 users.append(line) 12 # 打印 13 print(users)

通过Python读取CSV文件比较简单,但会遇到两个问题:
1.中文乱码问题。codecs是Python标准的模块编码和解码器。首先通过codecs提供的open()方法,在打开文件时可以指定编码类型,如utf_8_sig,然后导入CSV模块,通过reader()方法读取文件,即可避免中文乱码问题。
2.跳过CSV文件的首行。因为一般会在第一行定义测试字段的名字,所以在读取数据时要跳过。Python的内建模块itertools提供了用于操作迭代对象的函数,即islice()函数,可以返回一个迭代器第一个参数指定迭代对象,第二个参数指定开始迭代的位置,第三个参数表示结束位。
- XML文件
当需要读取的数据是不规则时,可以用XML文件。比如需要用一个配置文件来配置当前自动化测试平台、浏览器、URL、登录的用户名和密码等,这时就需要使用XML文件存放这些数据。其特点是数据保存在标签对之间,或者是作为标签的属性存放。
1 <?xml version="1.0" encoding="utf-8" ?> 2 <info> 3 <platforms> 4 <platform>Windows</platform> 5 <platform>Linux</platform> 6 <platform>macOS</platform> 7 </platforms> 8 <browsers> 9 <browser>Firefox</browser> 10 <browser>Chrome</browser> 11 <browser>Edge</browser> 12 </browsers> 13 <url>http:www.xxxx.com</url> 14 <login username="admin" password="123456"/> 15 <login username="guest" password="654321"/> 16 </info>
1 from xml.dom.minidom import parse 2 # 打开XML文件 3 dom = parse('./config.xml') 4 # 得到文档元素对象 5 root = dom.documentElement 6 # 获取一组标签 7 tag_name = root.getElementsByTagName('platform') 8 9 print(tag_name[0].firstChild.data) 10 print(tag_name[1].firstChild.data) 11 print(tag_name[2].firstChild.data)
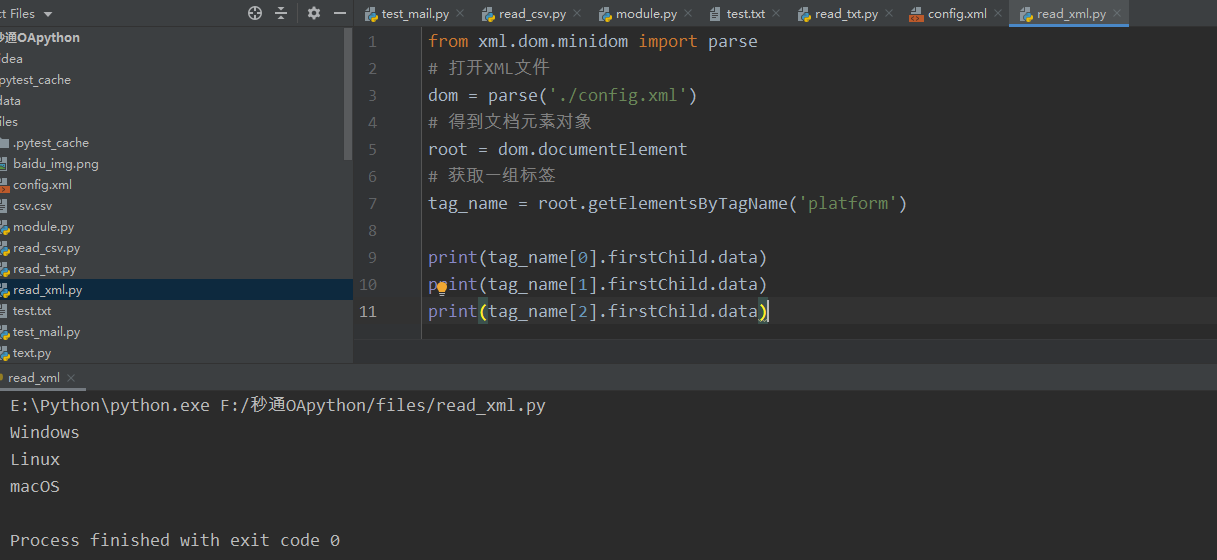
Python自带读取XML文件的模块,通过parse()方法可读取XML文件。documentElement()方法用于获取文档元素对象,getElementsByTagName()方法用于获取文件中的标签。这里不需要指定标签的层级关系,即获取的标签可以是任意层级的。接下来,获取标签数组中的某个元素。firstChild属性可返回被选节点的第一个子节点,data表示获取该节点的数据,它和WebDriver中的text语句作用相似。上面的代码是来获取标签对之间的数据,下面来看看如何获取标签的属性值:
1 from xml.dom.minidom import parse 2 dom = parse('./config.xml') 3 root = dom.documentElement 4 login_info = root.getElementsByTagName('login') 5 # 获得login标签的username属性值 6 username = login_info[0].getAttribute("username") 7 print(username) 8 # 获得login标签的password属性值 9 password = login_info[0].getAttribute("password") 10 print(password) 11 12 # 获得第二个login标签的username属性值 13 username = login_info[1].getAttribute("username") 14 print(username) 15 # 获得第二个login标签的password属性值 16 password = login_info[1].getAttribute("password") 17 print(password)
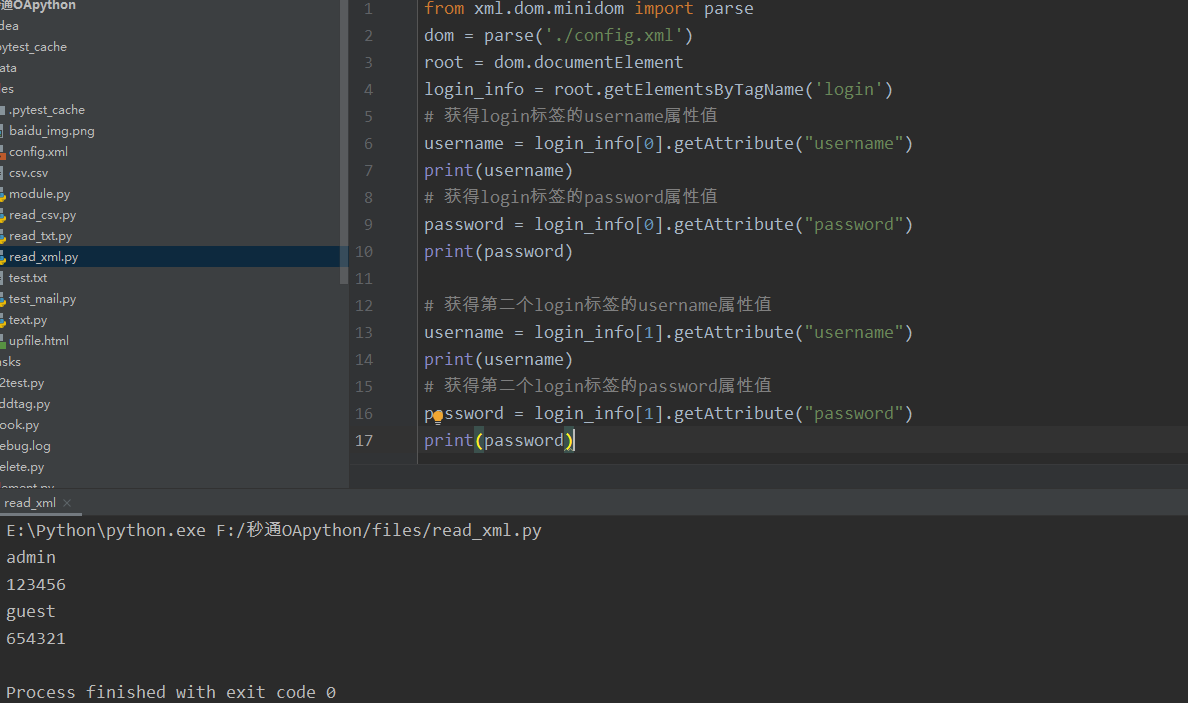
这里主要使用getAttribute()方法获取元素的属性值,它和WebDriver中的get_attribute()方法作用相似
- JSON文件
JSON是一种轻量级的数据交换格式,层次结构清晰,创建user_info.json文件:
1 [ 2 {"username": "", "password": ""}, 3 {"username": "", "password": "123"}, 4 {"username": "user", "password": ""}, 5 {"username": "error", "password": "error"}, 6 {"username": "admin", "password": "admin123"} 7 ]
创建read_json.py文件:
1 import json 2 3 with open("./user_info.json", "r") as f: 4 data = f.read() 5 6 user_list = json.loads(data) 7 print(user_list)
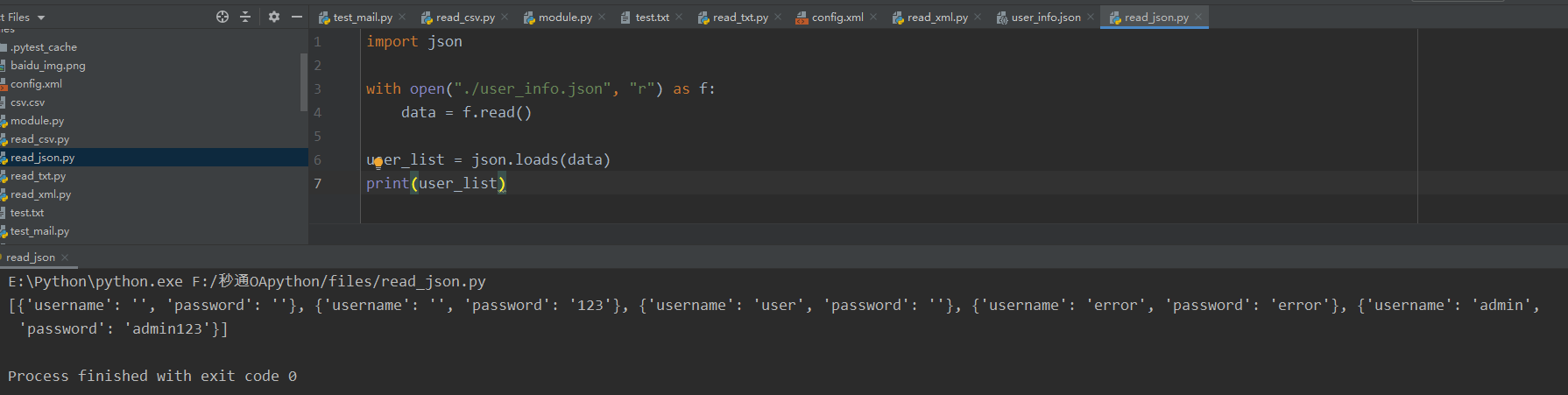
通过open()方法可读取user_info.json文件。因为测试数据本身是以列表和字典格式存放的,所以读取整个文件内容后,通过JSON提供的表将str类型转换为list类型即可。