1.Hadoop的由来
2002年,开源组织Apache成立开源搜索引擎项目Nutch
2004年,Apache实现了Nutch版的NDFS和MapReduce
2006年,NDFS和MapReduce移出Nutch,形成独立项目,称为Hadoop。
Hadoop采用客户-服务器模式,Hadoop 2.0很容易从一台机器扩展至成千上万台机器,并且每台机器都能提供本地计算存储和本地计算。
考虑到集群中每台机器都可能会出问题(如硬件失效),Hadoop 2.0本身从设计上就在程序层规避了这些问题。
Hadoop的组成:
Hadoop至少应当包含分布式存储和分布式计算两个模块
(1)HDFS Hadoop的分布式文件系统。
主要提供分布式存储服务。
(2)Hadoop MapReduce 分布式计算框架。
主要负责资源管理、任务调度和MapReduce算法实现。
(3)Hadoop Common
联系HDFS和MapReduce的纽带,它一方面为另外两组件提供一些公用jar包,另一方面也是程序员访问其他两模块的接口。
(4)Yarn 分布式操作系统
2.Hadoop的相关项目
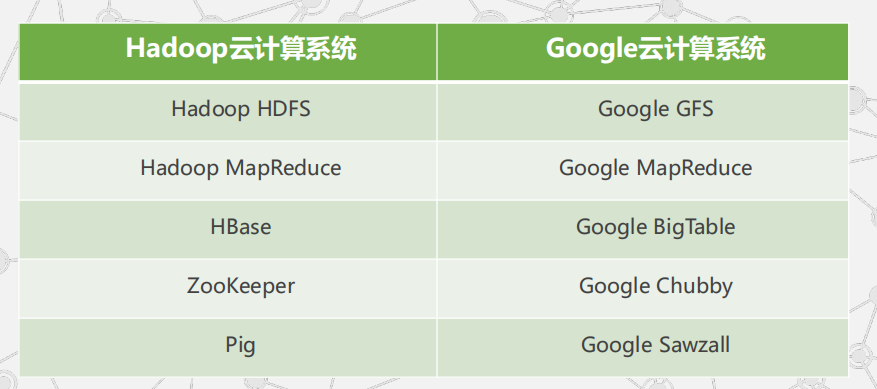
Google云计算组件和Hadoop及其相关项目之间的对应关系:
3.Hadoop的应用
(1)构建大型分布式集群
(2)数据仓库
(3)数据挖掘