1.传统算法与机器学习的区别
机器学习:让机器去学习
传统算法:让机器去执行
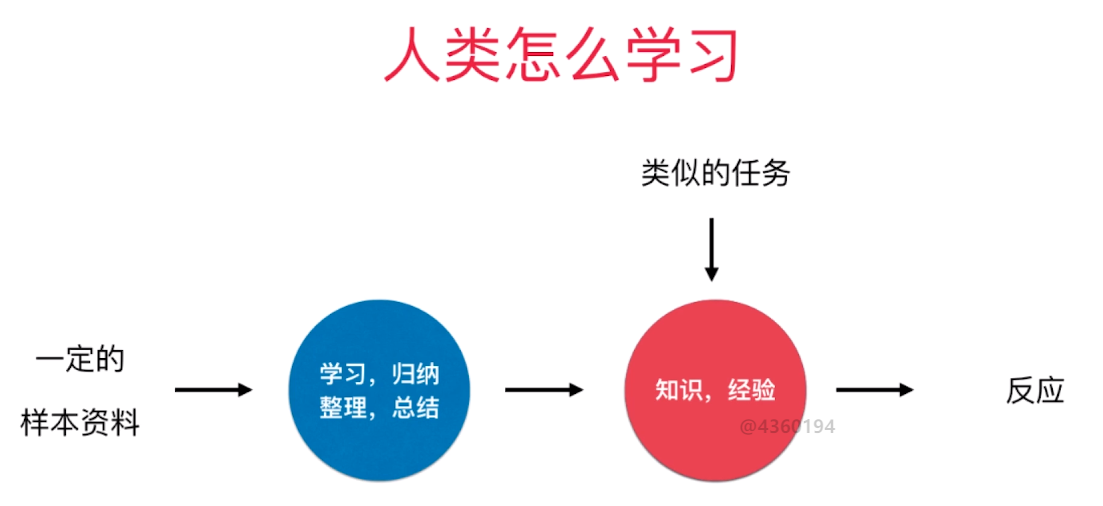
2.人类学习的过程
人类的学习过程是一个典型的经验学习的过程。
3.机器学习的过程
机器学习的过程和人类学习的过程是极为相似的。
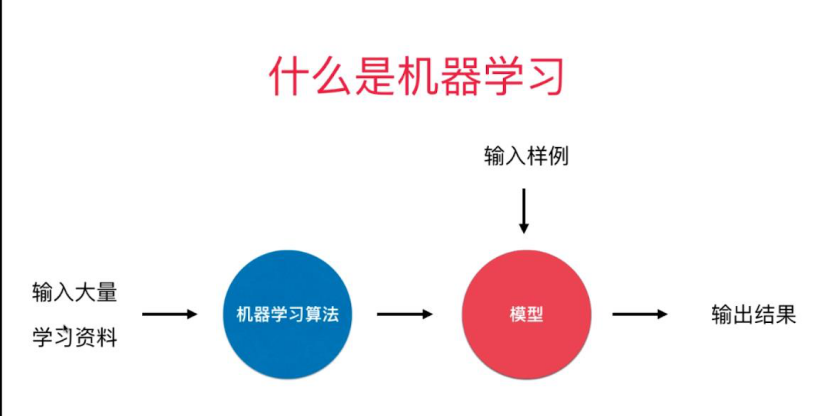
4.机器学习发展的两个前提:
(1)数据资料的大量产生与获取。
(2)计算机运算速度提高,计算能力越来越强。
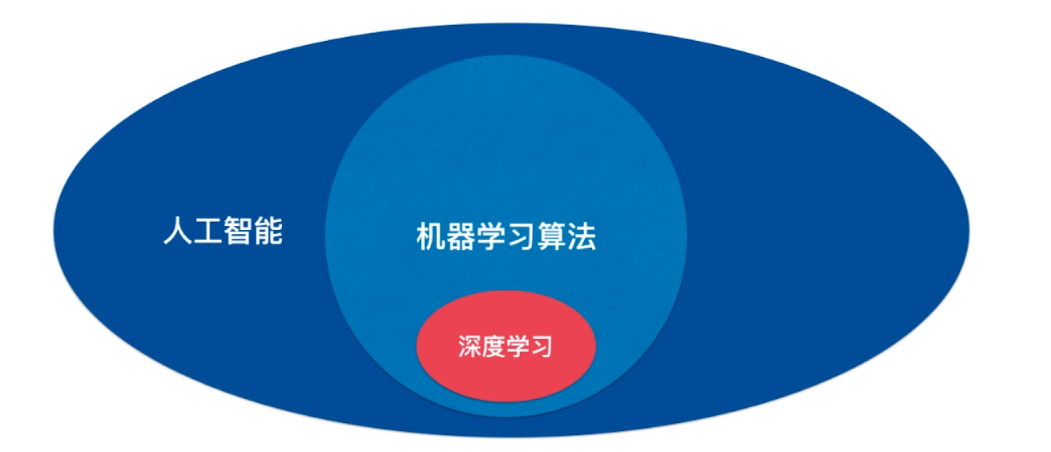
5.人工智能,机器学习和深度学习的关系
6.学习机器学习需要关注的问题

7.对于调库的态度

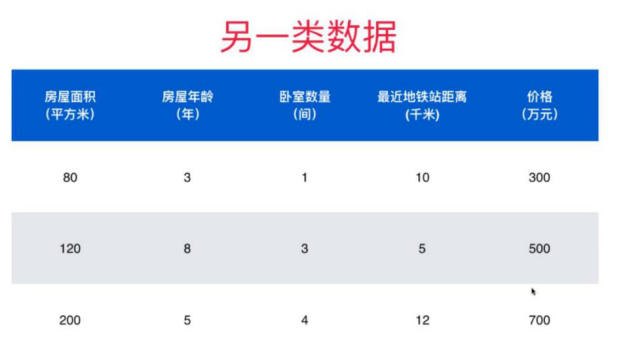
8.机器学习世界的数据
鸢尾花数据集的一部分:
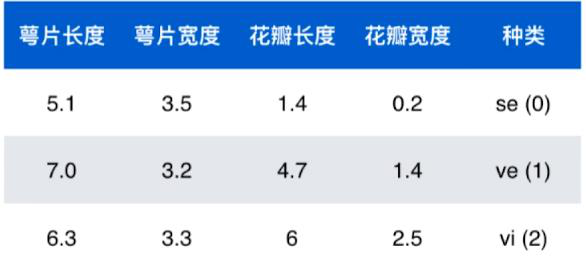
数据整体叫数据集(data set)
每一行数据称为一个样本(sample)
除最后一列,每一列表达样本的一个特征/属性(feature) 每一个样本由不同的特征进行描述
最后一列称为标记(label) (机器学习要学习的内容)
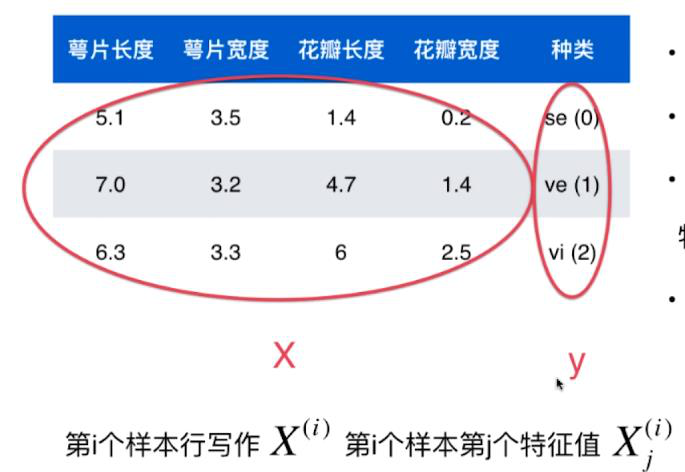
数学上常用大写字母表示矩阵,小写字母表示向量。
X是一个矩阵
X有多少行说明有多少样本,有多少列说明有多少特征。
y是一个向量


每个样本的特征都可以表示为一个特征向量。
在数学上,向量通常都用列向量表示(特征向量x(i)为列向量)
以上的鸢尾花数据集可以用向量表示为:
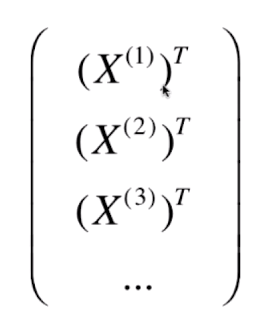
样本的本质是在特征所组成的空间中的一个点: (在高维空间同理)
该空间称为特征空间(feature space)
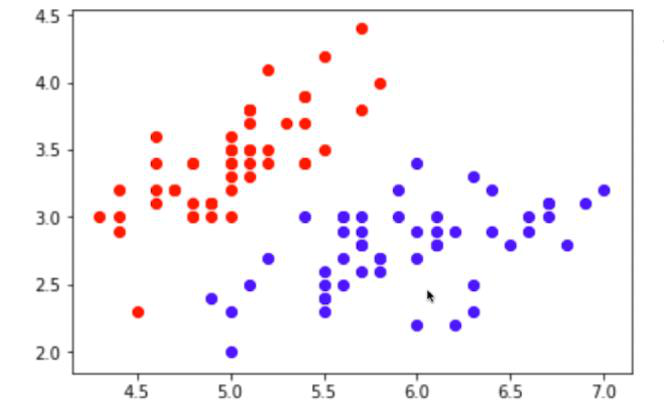
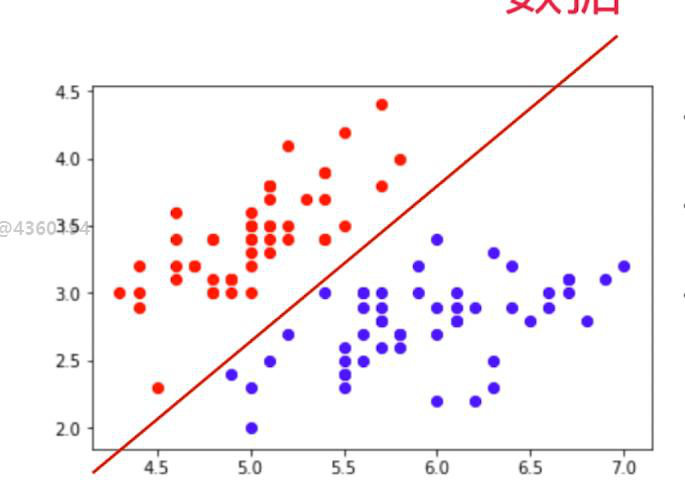
分类任务的本质就是在特征空间进行切分:
特征可能是有具体语义的,也可能是抽象的。
9.机器学习的主要任务
机器学习的基本任务分为分类任务和回归任务。更准确地说,是监督学习这种方式处理的是分类问题和回归问题。
分类任务: 将给定的数据进行分类
(1) 二分类
(2) 多分类
很多复杂的问题可以转换为多分类问题
一些算法只支持完成二分类的任务,但多分类的任务可以转换为二分类的任务,使得这些算法也能够胜任。
有些算法天然就可以完成多分类任务。
(3) 多标签分类
把一样事物分到多个类别当中
回归任务: 结果是一个连续数字的值,而不是一个类别。
有一些算法只能解决回归问题,有一些算法只能解决分类问题,还有一些算法既能解决回归问题又能解决分类问题
一些情况下,回归任务可以简化成分类任务
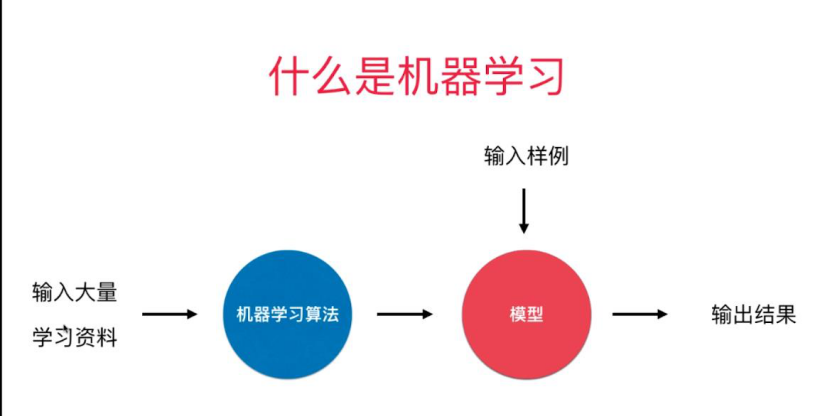
可以把模型理解成是一个函数f(x)
x为样本资料,函数的值即为结果(类别[分类问题]或连续数值[回归问题])
机器学习的本质就是找出这样的一个函数
10.监督学习,半监督学习,非监督学习和增强学习
可以把机器学习算法分为监督学习,半监督学习,非监督学习和增强学习四个大类
(1) 监督学习
给机器的训练数据集拥有”标记”或者”答案”
监督学习主要处理分类问题和回归问题
(2) 非监督学习(辅助监督学习的进行)
给机器的训练数据没有任何“标记”或”答案”
非监督学习的意义:
- 对没有标记的数据进行分类(聚类分析)
- 对数据进行降维处理(包括特征提取【忽略与判断无关的特征】和特征压缩【若干个特征联系紧密,可以用一个特征来表达。在尽量少的损失信息的情况下,将高维的特征向量压缩成低维的特征向量,大大提高机器学习算法的运行效率且不影响机器学习最终的准确率】)
特征压缩使用的主要手段:PCA
数据降维处理的意义:方便可视化
3.异常检测 检测出异常的样本并去除
(3)半监督学习
半监督学习是监督学习和无监督学习的结合
一部分数据有”标记”或”答案”,另一部分数据没有
半监督学习在实际生活中是更常见的,因为会有各种原因导致数据集中的标记缺失。
对于半监督学习,通常先使用无监督学习手段对数据做处理,使得数据变成监督学习的模式,之后使用监督学习手段做模型的训练和预测。
(4)增强学习
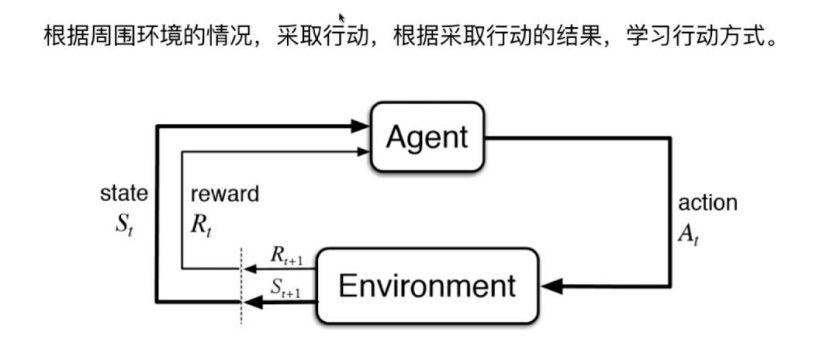
Agent:机器学习算法
机器学习算法(agent)根据周围的环境(environment)采取行动(action),采取行动之后,算法会收到环境的反馈(采用奖赏的机制或惩罚的机制),根据反馈改进自己的行为模式,然后再根据环境采取行动,环境再反馈,以此类推。
Agent在循环往复的行动-反馈中逐渐增强自己的智能。
监督学习和半监督学习是增强学习的基础。
11.批量学习(离线学习 Offline Learning)Batch Learning和在线学习 Online Learning:
(1)批量学习 模型训练完毕后就不会再发生变化
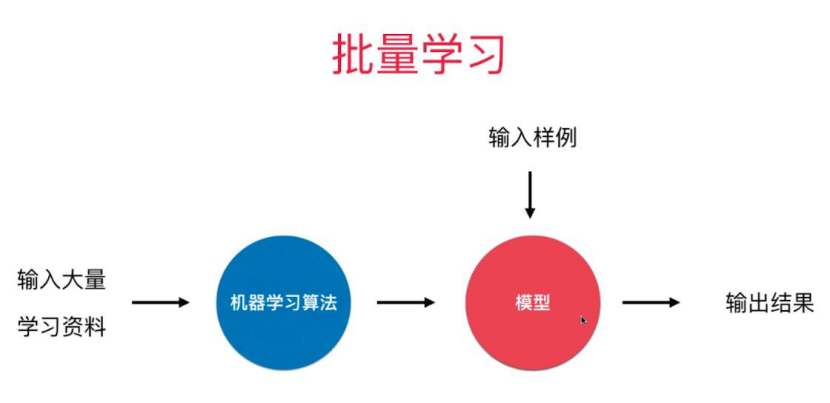
优点:简单
会产生的问题: 无法适应环境的变化
解决方法: 定时重新批量学习
缺点: 每次重新批量学习,运算量巨大。
在某些环境变化非常快的情况下(如股市),甚至是不可能的。
(2)在线学习 即时将新产生的数据用于改进机器学习模型
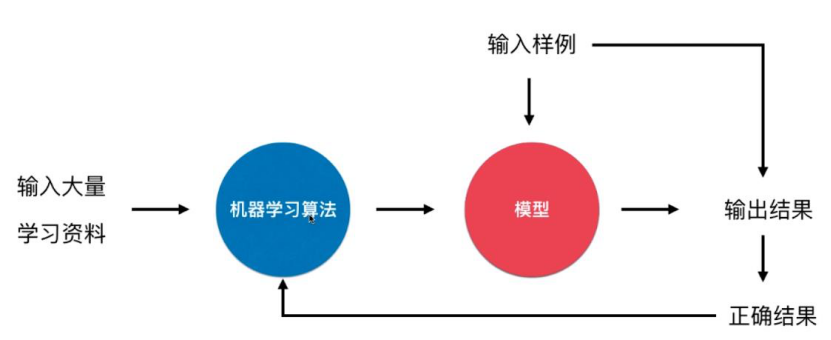
每次对输入数据产生产生输出结果时,同时也得到了输入数据对应的正确结果,将这一组新的样本实时地用于改进模型。
优点: 能够及时地反映新的环境变化。
可能产生的问题:新的数据若是异常数据,可能带来不好的变化
解决方法: 需要加强对数据进行监控。(使用非监督学习进行异常数据检测)
在线学习不仅适用于需要及时反映新的环境变化的情况,还适用于数据量巨大,无法完全进行批量学习的情况。
12.参数学习(Parametric Learning)和非参数学习(Nonparametric Learning):
(1)参数学习
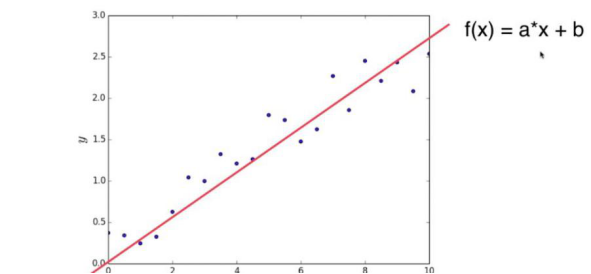
a和b即为参数
机器学习过程的本质就是找到合适的a和b,从而建立模型
一旦学到了参数,就不再需要原有的数据集
(2)非参数学习
不对模型进行参数上的假设
原有的数据集也要参与到预测的过程中
非参数学习不代表没有参数。
13.在机器学习领域,算法和数据都非常重要。
算法的重要性是毋庸置疑的。
数据也非常重要。现今的大多数机器学习任务是数据驱动(高度依赖数据本身的质量)的。
因此我们需要收集更多的数据,提高数据的质量,提高数据的代表性,研究更重要的特征。
14.如何选择机器学习算法
(1)简单的就是好的(问题:在机器学习领域,什么叫"简单"?)
(2) 没有一种算法,绝对比另一种算法好。但具体到某个特定的问题,有些算法可能更好。
脱离具体问题,谈哪个算法好是没有意义的。
在面对一个具体问题的时候,尝试使用多种算法进行对比试验,是必要的。