摘要:
大数据催生了互联网,电子商务,也导致了信息过载。信息过载的问题可以由推荐系统来解决。推荐系统可以提供选择新产品(电影,音乐等)的建议。这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口味向用户推荐歌曲。本文介绍一种基于用户和物品的协同过滤技术。首先,建立一个用户-物品相关矩阵来形成用户集群和物品集群。然后,使用这些集群找出和目标用户最相似的用户集群和物品集群。最后,系统会根据最相似的用户和物品集群来推荐音乐。该算法将在基准数据集Last.fm上进行实施。实验结果显示该算法的表现要优于最热门的基准算法。
关键字:推荐系统;协同过滤; 相似度估计
PS:仔细读了一遍,英文也翻译了,算法也读了,花了那么长时间,却是这个普通的一个算法,很失望。
1.引言
进入电子商务和互联网时代后,信息开始如血液般流动。推荐系统是一种解决信息过载问题的工具。推荐系统由两种实体:用户和物品所组成。用户就是网上商店的顾客,物品就是商品。现今有大量推荐系统的应用,例如电影推荐系统,书籍推荐系统,音乐推荐系统等。这篇论文将会讨论音乐推荐系统。在音乐推荐系统中,用户就是听众,物品就是歌曲。
音乐无处不在。每个人只要点击鼠标就能倾听数之不尽的音乐。随着歌曲,乐队和艺术家的数量越来越多,听众很难做出选择。用户想要找到合自己音乐口味的歌曲。音乐推荐系统就是在这种情况下诞生了。Many services like Pandora, Spotify, and Last.fm [1] have come up in order to provide recommendations to users.Netflix组织了百万歌曲数据集挑战赛,希望参赛者能够设计出在Last.fm数据集上具有良好表现的推荐系统。要求对音乐的选择基于用户对某些艺术家的口味,偏爱和信任。为一个软件或者一部机器量化所有这些因素是很难的。因此找到真正使用户感兴趣,合乎用户口味的歌曲是很难的。Every music recommendations system works on a given set of assumptions in order to provide effective recommendations。
文学领域的两种标准推荐系统是协同过滤推荐系统和基于内容的推荐系统。协同过滤基于其他用户的行为进行推荐,而基于内容的系统基于物品的内容进行推荐。
论文的其余部分内容组织如下:
第二部分解释相关研究,第三部分讨论算法,第四部分讨论算法的效果,第五部分进行总结和指明未来的研究方向。
2.相关研究
2.1 用户-物品相关矩阵
协同过滤技术基于用户-物品相关矩阵这种数据结构。在这种数据结构中记录着每个用户和每种物品之间的相关性。
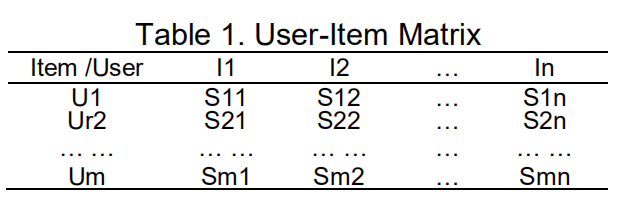
其中Sij是用户i(Ui)听歌曲j(Ij)的次数。
2.2 协同过滤技术
协同过滤技术是推荐系统中最常用的技术。协同过滤技术的基本思想是:如果用户的口味不变,则他过去喜欢的东西,他在未来也会喜欢。
协同过滤技术可以分为以下两类。
2.2.1 基于用户的协同过滤
这种方法的主要思想是找到与当前目标用户最相近的所有用户,然后尝试推荐目标用户可能会喜欢的物品。
2.2.2 基于物品的协同过滤
基于物品的协同过滤方法是基于物体的属性而不是用户的属性。它会根据用户对某物品的评测行为生成物品的特征。使用的相似度评测方法有欧氏距离,谷本系数和基于对数似然的相似度。对于任一给定的物品,它将与所有用户有过行为的物品计算相似度,由此决定是否将该物品推荐给该用户。这种方法在经常有新物品加入系统时非常有用。
3 算法
这部分会描述数据标准化技术,相似度计算,基于用户的方法和基于物品的方法,并形成用于推荐的用户集群和物品集群。
3.1 相似度计算
相似度计算用于寻找所给目标用户的最近邻居。以下是文学领域中的一些相似度计算方法。相似度计算方法可以根据数据类型进行分类。
欧氏距离测量方法是最常用的,用于显示用户与用户之间或物品与物品之间的距离是否相近。
数学公式如下:
d(p,q)为p和q之间的距离,表示两个用户或两个物品之间的距离。其中物品和用户用n维的向量来表示(n是物品的数量)。
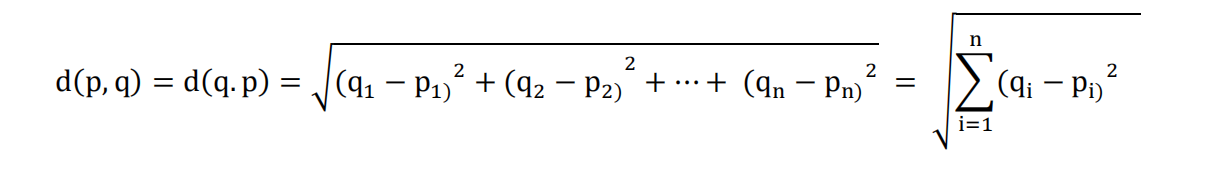
3.2 数据标准化技术
数据标准化技术是数据挖掘中的一种标准方法。它通过转换数据或正则化数据使所有的属性具有相同的权重。最常用的标准化技术是长度归一化和均方根归一化。
3.3 推荐方法
该论文推荐实现音乐推荐系统的一种方法。该方法使用的是基于模型的协同过滤。模型是根据基于用户的协同过滤和基于物品的协同过滤构建的。然后这个模型被用于给测试用户推荐音乐。
3.3.1 数据预处理
初步的数据处理作用在用户-物品相关矩阵上。首先对用户-物品矩阵进行二进制化,如下图所示:
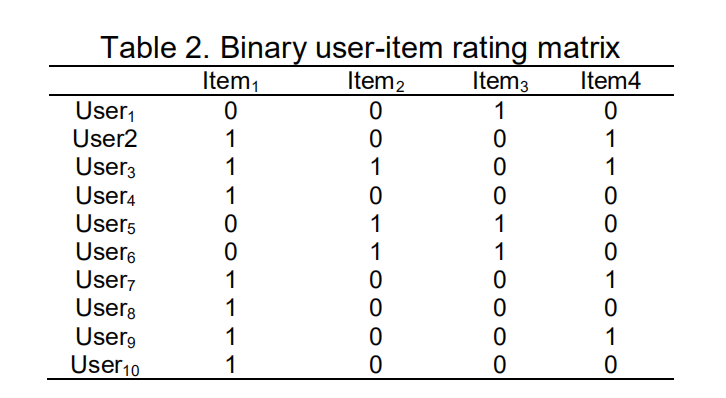
第二步预处理是正则化。
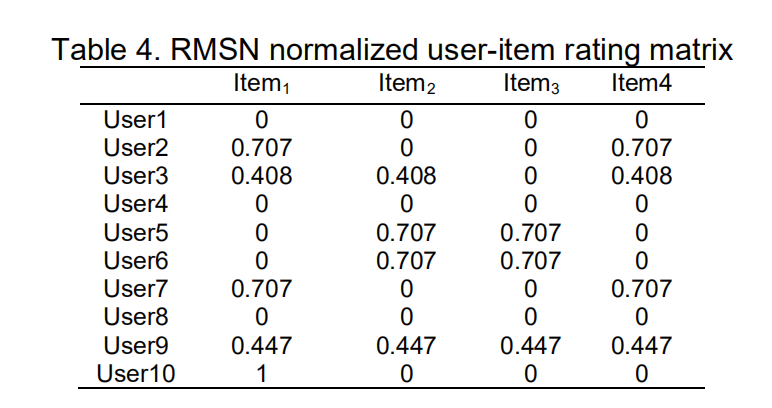
长度归一化和均方根归一化用于正则化二进制用户-物品相关矩阵。
表格3展示使用长度归一化的用户-物品矩阵,表格4展示使用均方根归一化的用户-物品矩阵:

3.3.2 模型建立
模型建立的输入数据是用户-物品相关矩阵。每一行被看做一个用户向量,每一列被看做一个物品向量。使用基于层次阈值的聚类算法建立用户和物品模型。使用图二中的伪代码形成用户模型(创建若干个相似用户集群),使用图三中的伪代码形成物品模型(创建若干个相似物品集群)。
测试数据分别作为用户模型和物品模型的输入,根据用户集群和物品集群进行推荐。推荐算法展示在图4中。


