继续昨天列表写起
1.列表
列表的常用方法
l = [1,2,3,4,5,6,7] res = 1.count(5) print(res)
count有返回值用来统计列表中字符的个数,比如count()小括号中数字为5,那么程序中打印出来的就是1,因为在l列表中5只出现了一次。
l = [1,2,3,4,5,6,7,] l.clear() print(l)
无返回值,清除列表中的内容,只剩下一个中括号。
l = [1,2,3,4,5,6,7] l.reverse() print(l)
此程序的作用是将列表中的内容进行反转。
l1 = [45,23,12,454] l1.sort(reverse=1) print(l1)
此程序为排序,默认情况下按从小到大进行排列,如果括号内这样写的话就按大到小排列。
队列:先进先出
l1 = []
l1.append('first')
l1.append('second')
l1.append('third')
append无返回值,编程时就按照这样的语法来进行编写。
堆栈:先进后出
l1.append('first')
l1.append('second')
l1.append('third')
print(l1)
print(l1.pop())
print(l1.pop())
print(l1.pop())
列表是有序的,可变的
可变类型:不可变数据类型在第一次声明赋值声明的时候, 会在内存中开辟一块空间, 用来存放这个变量被赋的值, 而这个变量实际上存储的, 并不是被赋予的这个值, 而是存放这个值所在空间的内存地址, 通过这个地址, 变量就可以在内存中取出数据了. 所谓不可变就是说, 我们不能改变这个数据在内存中的值, 所以当我们改变这个变量的赋值时, 只是在内存中重新开辟了一块空间, 将这一条新的数据存放在这一个新的内存地址里, 而原来的那个变量就不在引用原数据的内存地址而转为引用新数据的内存地址了.
不可变类型:结合不可变数据类型,可变数据类型就很好理解来,可变数据类型是指变量所指向的内存地址处的值是可以被改变的。
从另外一个角度来看:
不可变类型:当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,对于这种数据类型,就称不可变数据类型。
可变数据类型:当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,对于这种数据类型,就称可变数据类型。
2.元组
能够存储多个元素,元素与元素之间逗号隔开,元素可以是任意类型,元组本身不能被修改,元组内部有可变类型(列表等)的话就能被修改。与列表类型比,只不过是[]换成()。age=(11,22,33,44,55)本质age=tuple((11,22,33,44,55))。特别注意: 在定义容器类型的时候,哪怕内部只有一个元素,要要用逗号分隔开,区分下.
元素可以是多个类型:
按索引取值, 内部必须传容器类型,如果内部不是容器类型,按索引取值的话就会出现报错情况
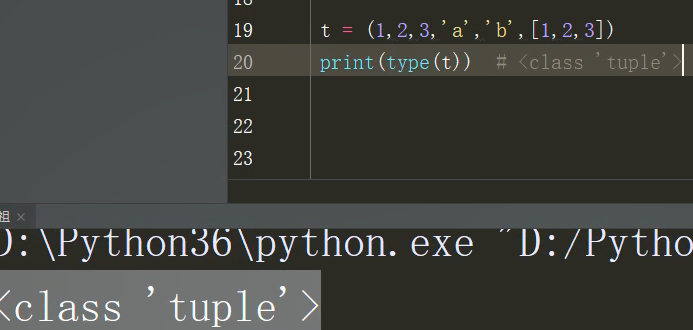
t = (1,2,3,'s','b',[1,2,3]) print(t[0]) t[-1][0] = 'hahaha' print(t)
在这个程序当中,元组内的内容不能被随意更改,只有当元组中存在可变类型(list dict set)时,才能在这些可变类型中随意更改,本程序中该元组中存在着列表,所以可以在列表中改。
t = (1,2,3,'s','b',[1,2,3])
print(t.count('a'))
print(t.index('xxx'))
在t.count()中,如果元组中无括号中的元素时,无返回值,在t.index()中,元组中没有小括号的元素时,运用index就会出现报错情况。find与index的区别就是find找不到元素的索引值时,不会报错,返回-1,index找不到元素时就会出现报错情况
元组是不可变的,有序的
区分可变与不可变类型: 只要是指向元素的内存地址的第一条线不断就是不可变类型
字典
能存储多组key:value键值对, key是对value的描述,key多数情况下都是字符串 key只能是不可变类型(值改变,id不改变),value可以是数据类型
d2 = {'name':'jason','name':'tank','name':'nick','pwd':123}
print(len(d2))
print(d2)
字典的key是不能重复的,要唯一标识一条数据,如果重复了,只会按照最后一组重复的键值对存储。
d3 = {'name':'jason','pwd':123}
print(id(d3))
print(d3['name'])
d3['name'] = 'egon'
d3['name'] = 'ddd'
d3['age'] = 18 // 当key不存在的情况下,会自动新增一个键值对
print(d3,id(d3))
从输出的结果来看,地址未曾发生过改变,赋值语句当key不在的时候,会自动增加一对键值对。
d3 = {'name':'jason','pwd':12}
del d3['name']
print(d3)
res = d3.pop('name')
print(res) # 弹出仅仅是value,当键不存在时就会出现报错情况。
d1 = {'name':'jason','passwod':123}
print(d1['name'])
print(d1['age'])
当字典中没有key存在时,立即报错。字典中的key存在时,后面的句子就不会再打印出来,有get语句时,当字典的key有不存在情况,不报错,返回None。get可以传第二个参数,当你的key不存在情况下,返回第二个你写好的参数信息,第二个参数不写的话当key不存在的情况下返回None,写了就返回写的内容。
删除:

获取字典values与keys:
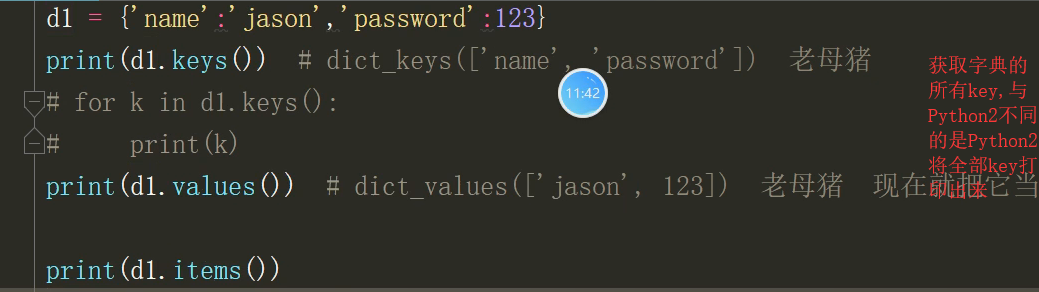
打印出来的都是列表类型的,你要几个我给你给几个,不是一次性全部都给你,比较节省内存空间
get获取value:
get()根据key获取value
d1 = {'name':'jason','pwd':123}
print(d1['name'])
print(d1['age'])
print(d1.get('name','你给我的name在字典的key中'))
res = d1.get('age') # 当字典的key不存在的情况 不报错 返回None
res1 = d1.get('xxx','你给我的age在字典的key中') # 当字典的key不存在的情况 不报错 返回None
get可以传第二个参数。当你的key不存在的情况下,返回第二个你写好的参数信息
print(res1)
print(d1.get('xxx','asdsad'))
第二个参数不写的话 当key不存在的情况下返回None,写了就返回写了内容
字典可以存多个值,无序的,可变类型
3.集合
作用: 去重,关系运算,集合的目的是将不同的值存放在一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
s1 = set()
print(type(s1))
x = {}
print(type(x)) #如果仅仅写了一个大括号,那么python默认把他当作字典类型
t = () print(type(t))
如果仅仅写了一个小括号,那么python默认把他当作元组类型
每个元素必须是不可变类型:

没有重复的元素,大括号内部有重复元素时,就会自动的去重,集合也是无序的
pythons = {'jason','egon','kevin','yangpan','tom'}
linux = {'jason','yangpan','xiaodu','xiaoyan'}
print(pythons & linux) # 求两个集合的交集
print(pythons - linux) # 求学python中学生的姓名
print(linux - pythons) # 求学linux中的学生姓名
print(pythons ^ linux) # 求交叉错集 报了两门课程剩下没报学生的姓名
print(pythons | linux) # 求报了课程的全部人数
s = {1,2,3,4,5}
print(s.add(666))
print(s.add((1,2,3,4))) # 将容器类型当成一个元素传入
print(s)
print(s.remove(1)) # 将1去除
print(s) #输出去除1之后剩下的元素
print(s.discard(3)) # 丢弃括号中的数字
print(s)