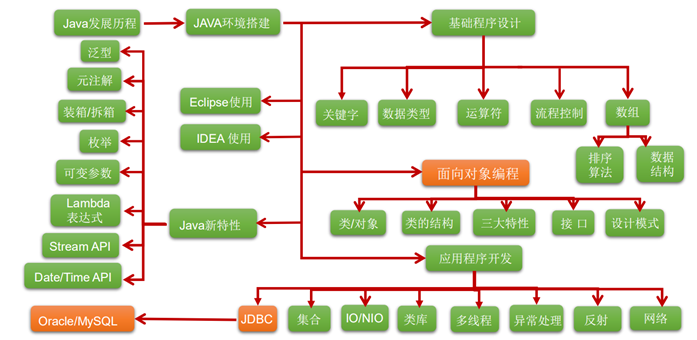
从Hello Word入手
public class HelloWorld {
/* 第一个Java程序 */
public static void main(String[] args) {
System.out.println("Hello World"); // 打印 Hello World
}
}
public class HelloWorld 一个文件中只能有一个 public 修饰类(class)。
public static void main(String[] args) main:程序的入口 String[] args :要传递的参数列表。
System.out.println("Hello World"); System.out System类中的 "标准" 输出流。
注意:类名要与文件名相同。
Java区分大小写。
知识点:
public:访问权限修饰符。
class:类修饰符。
HelloWorld:自定义类名。
访问修饰符:
1. private :(私有的)只能在所修饰的类中访问。
2.(默认的):能在本包中访问。
3. protect :(受保护的)本包和外包子类中都可以直接访问。
4.public :(公共的)项目下所有包都可以访问。。
标识(zhi)符:
java中所有要求自己命名的都是标识符
规则:
- 由26个英文字母大小写,0-9 ,_或 $ 组成
- 数字不可以开头。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- Java中严格区分大小写,长度无限制。
- 标识符不能包含空格。
规范:
1.见名知意即可,不要过长;2.驼峰原则
3.包的命名 : 全部小写 ,多级包用 . 隔开 例如:com.java
4.类 或者 接口 : (大驼峰原则)每个单词的首字母大写 例如:MyJava
5.方法 或者 变量 :(小驼峰原则) 首字母小写,第二个单词开始,每个单词首字母大写 例如:myJava
6.常量 : 全部大写, 每个单词之间使用 _ 进行分割 。例如:MY_JAVA
关键字与保留字
关键字
定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)
特点:关键字中所有字母都为小写


static 关键字:
1)表示static修饰的成员,属于静态成员,所有对象共享一份,它存放在方法区里;
2)用static声明的方法是静态方法,在调用该方法时,不会将对象的引用传递给它,所以在static 方法中不可访问非static的成员;(静态方法不再是针对于某个对象调用,所以不能访问非静态成员)
静态方法在类加载时就被初始化了;
在没有任何对象产生下,静态方法不能调用非静态成员;
静态方法可以调用静态成员;
3)Static修饰的成员,属于类级别的,可以用类名直接调用;
4)也可以用对象名调用,但建议用类名调用;
5)如果某个对象修改了static静态变量的值,其他对象共享改变;
6)Static的作用:
1、在堆里,每个对象都会有一个相同的空间,浪费内存;
2、如果修改值,需要每一个对象一个个的改;
this 关键字:
1)在普通方法中,this指向调用该方法的对象;
2)在构造方法中,this指向正要初始化的对象;
3)This不能用于static方法中;
4)区别成员变量和局部变量;当在一个方法内时,局部变量与成员变量重名时,为了区分,成员变量要加this ; 如果没有重名的情况,this可以省略(加上也可以);
5)使用this来调用方法;方法没有重名时,this可以省略;
6)This可以调用构造方法:(语法要求:必须是第一句, this())
7)This在内存中的表示:
This是一个引用变量,指向的是当前对象自身;
每个对象都有一个this变量,this成员变量;
super关键字 :
1)作用:
执行当前对象的父类对象,每一对象都有一个supser属性,创建对象时分配空间;
2)使用:
1、修饰父类的成员变量:super.属性名;
2、修饰父类的成员方法:super.方法名;
3、修饰父类的构造方法:super.构造器;<在子类的构造器中,调用父类的构造器,要求:必须是第一句>
3)注意:
This和super不能同时出现在子类的构造器中;
1、this和super都必须是构造方法中的第一条语句,如果存在,谁是第二条语句都是错误;
2、继承条件下,对象的构建顺序:子类会调用父类的构造器;
A ) 子类构造方法,默认会调用父类无参构造方法;
B)如果在子类构造方法中,显示指定了父类的构造方法时,就调用指定的父类构造方法;
3、父类使用private修饰的成员,子类可以继承,但是无法访问;如果访问,在父类中设置set方法,在子类中通过super.set方法来调用;
4)构建子类对象时的内存图:
Dog dog = new Dog();
创建一个Dog子类对象,会自上而下分别创建Object、Animal、Dog三个对象,每个对象除了具有自身的成员变量外,还分配this和super两个属性空间,this指向当前对象自身,super指向当前对象的直接父类对象;
Object、Animal、Dog三个对象是依赖于super关键词联系起来的,最后,将Dog子类的内存起始位置赋给dog引用变量;
注意:分配内存时,父类对象Animal的color, age属性并不会在Dog子类中分配空间。
子类对象要比父类对象大,因为子类对象包含了父类对象;
保留字(reserved word)
Java保留字:现有Java版本尚未使用,但以后版本可能会作为关键字使用。自己命名标记符时要避免使用这些保留字 byValue、cast、future、 generic、 inner、 operator、 outer、 rest、 var 、 goto 、const;
注释:
1. 单行注释 : // ...(java特有)
格式:/**
* @author 指定java程序的作者
*@version 指定源文件的版本
*@param 方法的参数说明信息
*/
1)正确的注释和注释风格:
使用文档注释来注释整个类或整个方法。
如果注释方法中的某一个步骤,使用单行或多行注释。
正确的缩进和空白
使用一次tab操作,实现缩进
运算符两边习惯性各加一个空格。比如:2 + 4 * 5。
变量:
变量的概念:
- 内存中的一个存储区域;
- 该区域的数据可以在同一类型范围内不断变化;
- 该区域有自己的名称(变量名)和类型(数据类型);
变量的作用:
用于在内存中保存数据;
使用变量注意:
Java中每个变量必须先声明,后使用
变量的作用域:一对{ }之间有效
初始化值
使用变量名来访问这块区域的数据
声明变量:
语法:<数据类型> <变量名称>
例如:int var;
变量的赋值:
语法:<变量名称> = <值>
例如:var = 10;
声明和赋值变量:
语法: <数据类型> <变量名> = <初始化值>
例如:int var = 10;
常量:
数据类型:


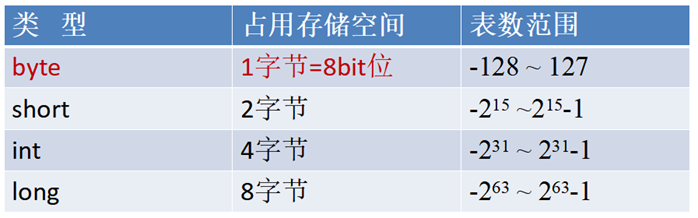
Java各整数类型有固定的表数范围和字段长度,不受具体OS的影响,以保证java程序的可移植性。
java的整型常量默认为 int 型,声明long型常量须后加‘l’或‘L’
java程序中变量常声明为int型,除非不足以表示大数,才使用long
bit: 计算机中的最小存储单位。byte:计算机中基本存储单元。

Java 的浮点型常量默认为double型,声明float型常量,须后加‘f’或‘F’。
char 型数据用来表示通常意义上“字符”(2字节);
注意:为了将字符存储到计算机中,需要引入一个字符编码集,将字符先通过字符编码集解析成对应的二进制,然后进行存储;
字符型常量的三种表现形式:
1)字符常量是用单引号(‘ ’)括起来的单个字符,涵盖世界上所有书面语的字符。例如:char c1 = 'a'; char c2 = '中'; char c3 = '9';
2)Java中还允许使用转义字符‘’来将其后的字符转变为特殊字符型常量。例如:char c3 = ‘ ’; // ' '表示换行符;
3)直接使用 Unicode 值来表示字符型常量:‘uXXXX’。其中,XXXX代表一个十六进制整数。如:u000a 表示 。
char类型是可以进行运算的。因为它都对应有Unicode码。
布尔类型:boolean:
boolean 类型适于逻辑运算,一般用于程序流程控制:
- if条件控制语句;
- while循环控制语句;
- do-while循环控制语句;
- for循环控制语句;
boolean类型数据只允许取值true和false,无null。
不可以0或非 0 的整数替代false和true,这点和C语言不同。
类型转换:
1)自动类型转换:
容量小的类型自动转换为容量大的数据类型。数据类型按容量大小排序为:

(1)有多种类型的数据混合运算时,系统首先自动将所有数据转换成容量最大的那种数据类型,然后再进行计算。
(2)byte,short,char之间不会相互转换,他们三者在计算时首先转换为int类型。
(3)当把任何基本类型的值和字符串(String)进行连接运算时(+),基本类型的值将自动转化为字符串类型。
2)强制类型转换:
自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符(()),但可能造成精度降低或溢出,格外要注意。
通常,字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型。
如: String a = “43”;
int i = Integer.parseInt(a);
boolean类型不可以转换为其它的数据类型。
3)隐式类型转换:
在三元运算符中。
运算符:
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。包含有:
1)算术运算符

算术运算符的注意问题:
如果对负数取模,可以把模数负号忽略不记,如:5%-2=1。 但被模数是负数则不可忽略。此外,取模运算的结果不一定总是整数。
对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。 例如:int x=3510;x=x/1000*1000; x的结果是?
“+”除字符串相加功能外,还能把非字符串转换成字符串.例如:System.out.println("5+5="+5+5); //打印结果是?
2)赋值运算符
1)符号:=
当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。支持连续赋值。
2)扩展赋值运算符(复合运算符): +=, -=, *=, /=, %=
注意:运算的结果不会改变原变量的数据类型(在复合运算符中,隐藏了强制转换,会自动转换成前面的操作数的类型);
3)比较运算符(关系运算符)

1)关系运算符用来进行比较运算,操作数与关系运算符组成关系运算表达式;
2)关系运算符的结果时布尔值;
3)> < >= <= :操作数数值类型,包含整型,浮点型,字符型;
4)== != :基本类型和引用类型都可以;
比较运算符的结果都是boolean型,也就是要么是true,要么是false。
比较运算符“==”不能误写成“=” 。
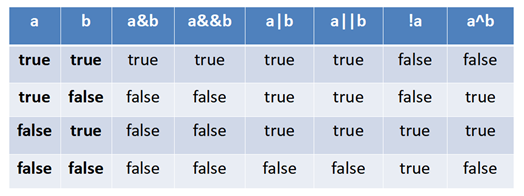
4)逻辑运算符
1)逻辑运算符与布尔操作数一起使用,组成逻辑表达式,所以,操作数要求是boolean值,运算结果也是Boolean值;逻辑运算符用于连接布尔型表达式,例:a>90&&b<100&&c>80;
注意:在Java中不可以写成3<x<6,应该写成x>3 & x<6 。
& :逻辑与,作为逻辑运算符时,两个操作数都是真时,为真,任意一个为假,则为假
| :逻辑或,有一个为真,就为真;
^ :逻辑异或,相同为假,不同为真;
! :逻辑反/逻辑非,非真即假;
&& :短路与;
|| :短路或;
2) & | 与 && || 的区别:
(1)运算规则相同;
(2) && || 只判断第一个操作数;
& 无论任务情况,它的两边的表达式都会参与计算;
&& 当它的左边为false时,则将不会计算其右边的表达式;即左false则false;
| 与 || 类似;
单&时,左边无论真假,右边都进行运算;
双&时,如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算。
“|”和“||”的区别同理,||表示:当左边为真,右边不参与运算。
异或( ^ )与或( | )的不同之处是:当左右都为true时,结果为false。
理解:异或,追求的是“异”!
逻辑运算符的优先级:! > & > ^ > |
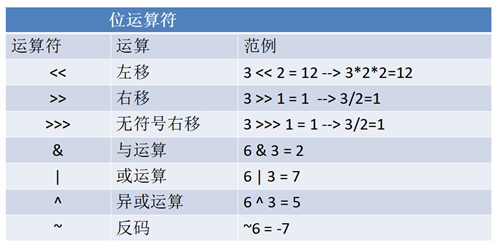
5)位运算符
位运算符先将十进制数转成对应的二进制的补码形式进行运算,并且最高位参与运算;
6)三元运算符
1)语法格式:
操作数为3个,语法格式:x ? y : z
2)执行过程:
其中x为boolean类型表达式,先计算x的值,若为true,则整个三目运算的结果为表达式y的值,否则整个运算结果为表达式z的值。
3)作用:经常用来代替简单的if else判断:
4)三元运算符与if-else的联系与区别:
1)三元运算符可简化if-else语句
2)三元运算符要求必须返回一个结果。
3)if后的代码块可有多个语句
运算符的优先级:
小括号>自增、自减>算术运算 > 位运算> 关系运算 > 逻辑运算 > 条件运算 > 赋值运算
运算符有不同的优先级,所谓优先级就是表达式运算中的运算顺序。如右表,上一行运算符总优先于下一行。
只有单目运算符、三元运算符、赋值运算符是从右向左运算的。

编码集介绍:
ASCII 码:
在计算机内部,所有数据都使用二进制表示。每一个二进制位(bit)有 0 和 1 两种状态,因此
8 个二进制位就可以组合出 256 种状态,这被称为一个字节(byte)。
ASCII码:上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码。ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
缺点:
不能表示所有字符。
相同的编码表示的字符不一样:比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג)
Unicode 编码:
Unicode码:可以包含世界上所有的字符,但固定的长度,有些浪费存储空间,Unicode 编码表中的字符占两个字节;
乱码:世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
Unicode:一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,使用 Unicode 没有乱码的问题。
Unicode 的缺点:Unicode 只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储:无法区别 Unicode 和 ASCII:计算机无法区分三个字节表示一个符号还是分别表示三个符号。另外,我们知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费。
UTF-8:
UTF-8 :对Unicode的优化,可以包含世界上所有字符,字母占1个字节,汉字占3个字节;
UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。
UTF-8 是一种变长的编码方式。它可以使用 1-6 个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则:
1)对于单字节的UTF-8编码,该字节的最高位为0,其余7位用来对字符进行编码(等同于ASCII码)。
2)对于多字节的UTF-8编码,如果编码包含 n 个字节,那么第一个字节的前 n 位为1,第一个字节的第 n+1 位为0,该字节的剩余各位用来对字符进行编码。在第一个字节之后的所有的字节,都是最高两位为"10",其余6位用来对字符进行编码。
程序流程控制:
顺序结构:程序从上到下逐行地执行,中间没有任何判断和跳转。
分支结构:根据条件,选择性地执行某段代码。有if…else和switch-case两种分支语句。
循环结构:根据循环条件,重复性的执行某段代码。有while、do…while、for三种循环语句。
注:JDK1.5提供了foreach循环,方便的遍历集合、数组元素。
循环的好处:
1、提高代码的重用性,代码更加简洁
2、提高代码的维护性,使代码扩展性更强!
循环语句 : 在某些条件满足的情况下,反复执行特定代码的功能;
循环四要素:
1)循环变量初始化(循环变量赋初值);
2)循环条件:满足该条件,将进入循环体执行操作(循环终止条件);
3)循环操作:反复执行的代码(循环语句);
4)循环变量更新(让循环趋向终止的条件,步进、迭代);
循环语句分类:
1)for 循环
2)while 循环
3)do/while 循环
跳转结构:
break 语句:
在任何循环语句的主体部分,均可用break控制循环的流程,break用于强行退出循环,不执行循环中剩余的语句。(break 只能与switch , 循环中使用,不能单独使用)
特点:
1)不管是单层还是多层,break是终止本层循环;
2)Break后,不能加执行代码,因为程序不会往下执行;
continue 语句:
用于在循环语句体中,用于终止某次循环过程,即跳过循环体中尚未执行的语句,接着进行下一次是否执行循环的判定;
特点:
1)不管是单层或多层,continue是终止本次循环;
2)Continue后,不能加执行代码,因为程序不会往下执行;
return 语句:
return:并非专门用于结束循环的,它的功能是结束一个方法。当一个方法执行到一个return语句时,这个方法将被结束。
与break和continue不同的是,return直接结束整个方法,不管这个return处于多少层循环之内;
Java学习